Sidst opdateret den 27. januar 2021
Det kan være en udfordring for begyndere at skelne mellem forskellige relaterede computer vision-opgaver.
For eksempel er billedklassifikation ligetil, men forskellene mellem objektlokalisering og objektdetektion kan være forvirrende, især når alle tre opgaver lige så godt kan betegnes som objektgenkendelse.
Billedklassifikation indebærer tildeling af en klasselabel til et billede, mens objektlokalisering indebærer tegning af en bounding box omkring et eller flere objekter i et billede. Objektdetektering er mere udfordrende og kombinerer disse to opgaver og tegner en afgrænset boks omkring hvert objekt af interesse i billedet og tildeler dem en klasselabel. Tilsammen kaldes alle disse problemer for objektgenkendelse.
I dette indlæg vil du opdage en blid introduktion til problemet med objektgenkendelse og state-of-the-art deep learning-modeller, der er designet til at løse det.
Når du har læst dette indlæg, vil du vide:
- Objektgenkendelse er henviser til en samling relaterede opgaver til identifikation af objekter i digitale fotografier.
- Region-Based Convolutional Neural Networks, eller R-CNNs, er en familie af teknikker til håndtering af objektlokaliserings- og genkendelsesopgaver, der er designet til modelydelse.
- You Only Look Once, eller YOLO, er en anden familie af teknikker til objektgenkendelse, der er designet til hastighed og realtidsbrug.
Kick-start dit projekt med min nye bog Deep Learning for Computer Vision, inklusive trinvise vejledninger og Python-kildekodefilerne til alle eksempler.
Lad os komme i gang.

En blid introduktion til objektgenkendelse med Deep Learning
Foto af Bart Everson, nogle rettigheder forbeholdt.
Overblik
Denne vejledning er opdelt i tre dele; de er:
- Hvad er objektgenkendelse?
- R-CNNN-modelfamilie
- YOLO-modelfamilie
Vil du have resultater med Deep Learning til computervision?
Tag mit gratis 7-dages e-mail crash-kursus nu (med prøvekode).
Klik for at tilmelde dig og få også en gratis PDF Ebook-version af kurset.
Download dit GRATIS minikursus
Hvad er objektgenkendelse?
Objektgenkendelse er en generel betegnelse for en samling beslægtede computer vision-opgaver, der involverer identifikation af objekter i digitale fotografier.
Billedklassifikation involverer forudsigelse af klassen af et objekt i et billede. Objektlokalisering henviser til identifikation af placeringen af et eller flere objekter i et billede og tegning af abounding box omkring deres udstrækning. Objektdetektion kombinerer disse to opgaver og lokaliserer og klassificerer et eller flere objekter i et billede.
Når en bruger eller praktiker henviser til “objektgenkendelse”, mener han eller hun ofte “objektdetektion”.
… vi vil bruge udtrykket objektgenkendelse bredt til at omfatte både billedklassifikation (en opgave, der kræver en algoritme til at bestemme, hvilke objektklasser der er til stede i billedet) samt objektdetektion (en opgave, der kræver en algoritme til at lokalisere alle de objekter, der er til stede i billedet
– ImageNet Large Scale Visual Recognition Challenge, 2015.
Som sådan kan vi skelne mellem disse tre computer vision-opgaver:
- Billedklassifikation: Forudsigelse af typen eller klassen af et objekt i et billede.
- Input: Et billede med et enkelt objekt, f.eks. et fotografi.
- Output: En klasselabel (f.eks. et eller flere heltal, der er afbildet til klasselabels).
- Lokalisering af objekt: Lokalisere tilstedeværelsen af objekter i et billede og angive deres placering med en afgrænset boks.
- Input: Et billede med et eller flere objekter, f.eks. et fotografi.
- Output: En eller flere afgrænsende bokse (f.eks. defineret ved et punkt, bredde og højde).
- Objektdetektering:
- : Lokaliserer tilstedeværelsen af objekter med en afgrænset boks og typer eller klasser af de lokaliserede objekter i et billede.
- Input: Et billede med et eller flere objekter, f.eks. et fotografi.
- Output: En eller flere afgrænsende bokse (f.eks. defineret ved et punkt, bredde og højde) og en klasselabel for hver afgrænsende boks.
- : Lokaliserer tilstedeværelsen af objekter med en afgrænset boks og typer eller klasser af de lokaliserede objekter i et billede.
En yderligere udvidelse af denne opdeling af computervisionsopgaver er objektsegmentering, også kaldet “objektinstanssegmentering” eller “semantisk segmentering”, hvor forekomster af genkendte objekter angives ved at fremhæve de specifikke pixels i objektet i stedet for en grov afgrænsende boks.
Fra denne opdeling kan vi se, at objektgenkendelse henviser til en række udfordrende computervision-opgaver.
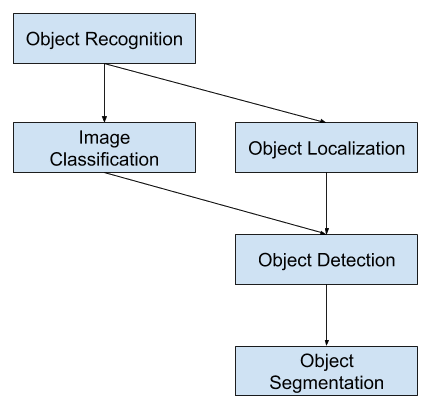
Overblik over objektgenkendelses-computervision-opgaver
De fleste af de seneste innovationer inden for billedgenkendelsesproblemer er kommet som led i deltagelsen i ILSVRC-opgaverne.
Dette er en årlig akademisk konkurrence med en separat udfordring for hver af disse tre problemtyper med henblik på at fremme uafhængige og separate forbedringer på hvert niveau, som kan udnyttes mere bredt. Se f.eks. listen over de tre tilsvarende opgavetyper nedenfor fra ILSVRC-undersøgelsesdokumentet fra 2015:
- Billedklassificering: Algoritmer producerer en liste over objektkategorier, der er til stede i billedet.
- Lokalisering af enkeltobjekter: Algoritmer producerer en liste over objektkategorier i billedet sammen med en aksejusteret afgrænsningsboks, der angiver position og skala for et eksemplar af hver objektkategori.
- Objektdetektion: Algoritmer producerer en liste over objektkategorier, der er til stede i billedet, sammen med en aksejusteret afgrænsningsboks, der angiver position og skala for hver forekomst af hver enkelt objektkategori.
Vi kan se, at “lokalisering af enkeltobjekter” er en enklere version af den mere bredt definerede “objektlokalisering”, idet lokaliseringsopgaverne begrænses til objekter af én type i et billede, hvilket vi kan antage er en lettere opgave.
Nedenfor er et eksempel, der sammenligner lokalisering af enkeltobjekter og objektdetektion, taget fra ILSVRC-papiret. Bemærk forskellen i forventningerne til grundsandheden i hvert tilfælde.
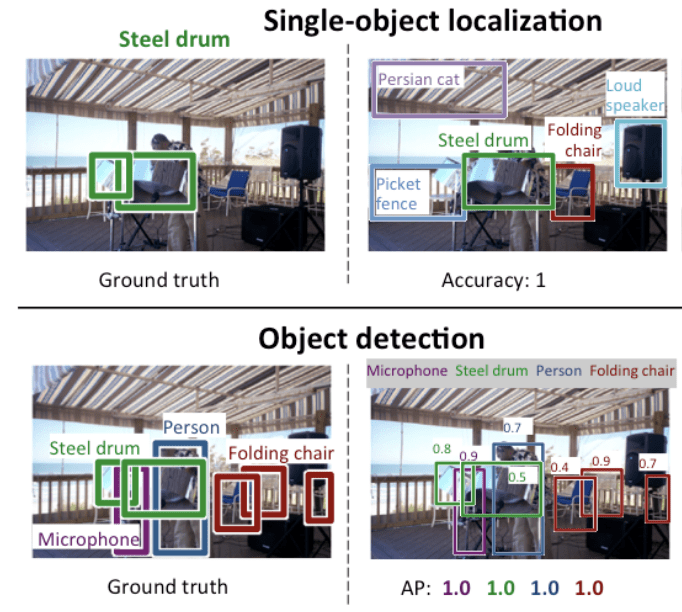
Sammenligning mellem lokalisering af enkeltobjekter og objektdetektering.Taget fra: ImageNet Large Scale Visual Recognition Challenge.
Effektiviteten af en model til billedklassifikation evalueres ved hjælp af den gennemsnitlige klassifikationsfejl på tværs af de forudsagte klasseetiketter. Ydelsen af en model til lokalisering af enkeltobjekter evalueres ved hjælp af afstanden mellem den forventede og den forudsagte afgrænsende boks for den forventede klasse. Mens præstationen af en model til objektgenkendelse evalueres ved hjælp af præcisionen og tilbagekaldelsen på tværs af hver af de bedst matchende bounding boxes for de kendte objekter i billedet.
Nu da vi er bekendt med problemet med objektlokalisering og -genkendelse, lad os tage et kig på nogle nyere top-præsterende deep learning-modeller.
R-CNNN-modelfamilie
R-CNN-familien af metoder henviser til R-CNN, som kan stå for “Regions with CNN Features” eller “Region-Based Convolutional Neural Network”, der er udviklet af Ross Girshick, et al.
Dette omfatter teknikkerne R-CNN, Fast R-CNN og Faster-RCNN, der er designet og demonstreret til objektlokalisering og objektgenkendelse.
Lad os se nærmere på højdepunkterne i hver af disse teknikker efter tur.
R-CNN
R-CNN blev beskrevet i 2014-artiklen af Ross Girshick, et al. fra UC Berkeley med titlen “Rich feature hierarchies for accurate object detection and semantic segmentation.”
Det kan have været en af de første store og vellykkede anvendelser af konvolutionelle neurale netværk til problemet med objektlokalisering, -detektion og -segmentering. Tilgangen blev demonstreret på benchmark-datasæt og opnåede derefter state-of-the-art-resultater på VOC-2012-datasættet og 200-klasses ILSVRC-2013-datasættet til objektdetektering.
Den af dem foreslåede R-CNN-model består af tre moduler; de er:
- Modul 1: Regionsforslag. Generering og udtrækning af kategoriuafhængige regionsforslag, f.eks. kandidatgrænser.
- Modul 2: Feature Extractor. Udtrække karakteristika fra hver kandidatregion, f.eks. ved hjælp af et dybt konvolutionelt neuralt netværk.
- Modul 3: Klassifikator. Klassificer funktioner som en af de kendte klasser, f.eks. lineær SVM-klassificeringsmodel.
Modellens arkitektur er opsummeret i nedenstående billede, taget fra papiret.
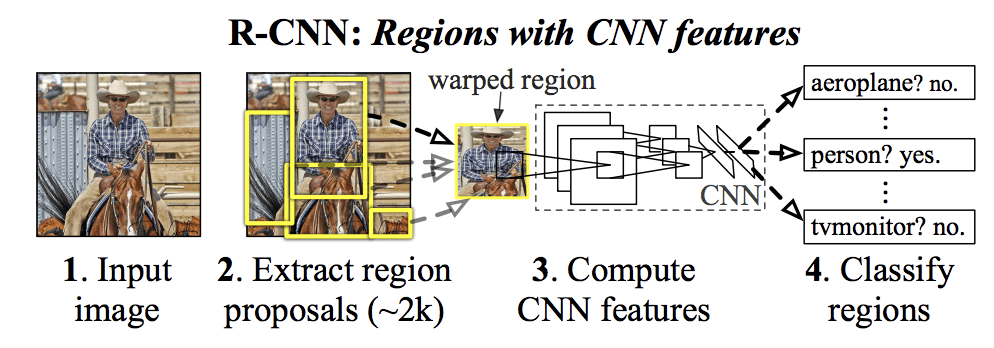
Summary of the R-CNN Model ArchitectureTaken from Rich feature hierarchies for accurate object detection and semantic segmentation.
Der anvendes en computervisionsteknik til at foreslå kandidatregioner eller afgrænsende kasser for potentielle objekter i billedet kaldet “selektiv søgning”, selv om fleksibiliteten i designet gør det muligt at anvende andre algoritmer til at foreslå regioner.
Den funktionsekstraktor, der anvendes af modellen, var AlexNet deep CNN, der vandt ILSVRC-2012-konkurrencen om billedklassificering. CNN’ens output var en vektor med 4 096 elementer, der beskriver billedets indhold, som føres til en lineær SVM til klassificering, specifikt trænes en SVM for hver kendt klasse.
Det er en relativt enkel og ligetil anvendelse af CNN’er på problemet med objektlokalisering og genkendelse. En ulempe ved denne fremgangsmåde er, at den er langsom, idet den kræver et CNN-baseret trækudtrækningsforløb på hver af de kandidatregioner, der genereres af regionforslagsalgoritmen. Dette er et problem, da artiklen beskriver, at modellen opererer på ca. 2.000 foreslåede regioner pr. billede på testtidspunktet.
Python- (Caffe) og MatLab-kildekoden til R-CNN som beskrevet i artiklen blev gjort tilgængelig i R-CNN GitHub-repositoriet.
Fast R-CNNN
I betragtning af den store succes med R-CNN foreslog Ross Girshick, der dengang var ansat hos Microsoft Research, en udvidelse for at løse hastighedsproblemerne ved R-CNN i en artikel fra 2015 med titlen “Fast R-CNNN.”
Afhandlingen indledes med en gennemgang af begrænsningerne ved R-CNN, der kan opsummeres som følger:
- Træning er en pipeline i flere faser. Involverer forberedelse og drift af tre separate modeller.
- Træning er dyrt i rum og tid. Træning af en dyb CNN på så mange regionsforslag pr. billede er meget langsom.
- Objektdetektion er langsom. At foretage forudsigelser ved hjælp af et dybt CNN på så mange regionsforslag er meget langsomt.
Der blev tidligere foreslået et arbejde for at fremskynde teknikken kaldet spatial pyramid pooling networks, eller SPPnets, i artiklen fra 2014 “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”. Dette fremskyndede udtrækningen af funktioner, men anvendte i det væsentlige en form for forward pass caching-algoritme.
Fast R-CNNN foreslås som en enkelt model i stedet for en pipeline til at lære og output regioner og klassifikationer direkte.
Modellens arkitektur tager fotografiet et sæt regionsforslag som input, der sendes gennem et dybt konvolutionelt neuralt netværk. Et forudtrænet CNN, f.eks. et VGG-16, anvendes til udtrækning af funktioner. Enden af det dybe CNN er et brugerdefineret lag kaldet et Region of Interest Pooling Layer, eller RoI Pooling, der udtrækker funktioner, der er specifikke for en given indgangskandidatregion.
Outputtet fra CNN’et fortolkes derefter af et fuldt forbundet lag, hvorefter modellen deler sig i to outputs, et til klasseforudsigelsen via et softmax-lag og et andet med et lineært output til den afgrænsende boks. Denne proces gentages derefter flere gange for hver region af interesse i et givet billede.
Modellens arkitektur er opsummeret i nedenstående billede, der er taget fra artiklen.
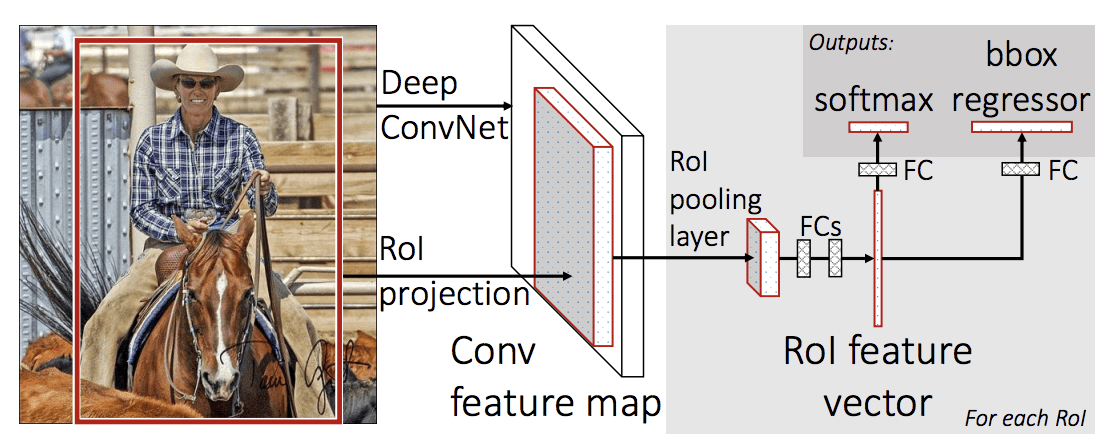
Summary of the Fast R-CNNN Model Architecture.
Taget fra: Fast R-CNN.
Modellen er betydeligt hurtigere at træne og foretage forudsigelser, men kræver stadig, at der foreslås et sæt kandidatregioner sammen med hvert indgangsbillede.
Python og C++ (Caffe) kildekoden til Fast R-CNN som beskrevet i artiklen blev gjort tilgængelig i et GitHub-repository.
Faster R-CNN
Modelarkitekturen blev yderligere forbedret med hensyn til både trænings- og detektionshastighed af Shaoqing Ren, et al. hos Microsoft Research i artiklen fra 2016 med titlen “Faster R-CNNN: Towards Real-Time Object Detection with Region Proposal Networks.”
Arkitekturen var grundlaget for de førstepladseresultater, der blev opnået på både ILSVRC-2015 og MS COCO-2015-opgaverne i konkurrencen om genkendelse og detektion af objekter.
Arkitekturen blev designet til både at foreslå og forfine regionsforslag som en del af træningsprocessen, benævnt et Region Proposal Network eller RPN (Region Proposal Network). Disse regioner anvendes derefter sammen med en Fast R-CNN-model i et enkelt modeldesign. Disse forbedringer reducerer både antallet af regionsforslag og fremskynder modellens drift i testtiden til næsten realtid med derefter state-of-the-art ydeevne.
… vores detektionssystem har en billedhastighed på 5fps (inklusive alle trin) på en GPU, mens det opnår state-of-the-art objektdetektionsnøjagtighed på PASCAL VOC 2007, 2012 og MS COCO-datasæt med kun 300 forslag pr. billede. I ILSVRC- og COCO 2015-konkurrencerne er Faster R-CNN og RPN grundlaget for de 1. pladsvindende bidrag i flere spor
– Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
Selv om det er en enkelt samlet model, består arkitekturen af to moduler:
- Modul 1: Regionsforslagsnetværk. Konvolutionelt neuralt netværk til forslag af regioner og den type objekt, der skal tages i betragtning i regionen.
- Modul 2: Fast R-CNN. Konvolutionelt neuralt netværk til at udtrække funktioner fra de foreslåede regioner og udgive den afgrænsende boks og klasselabels.
Både moduler opererer på det samme output af et dybt CNN. Regionsforslagsnetværket fungerer som en opmærksomhedsmekanisme for det hurtige R-CNN-netværk og informerer det andet netværk om, hvor det skal kigge eller være opmærksom.
Arkitekturen i modellen er opsummeret i nedenstående billede, der er taget fra papiret.
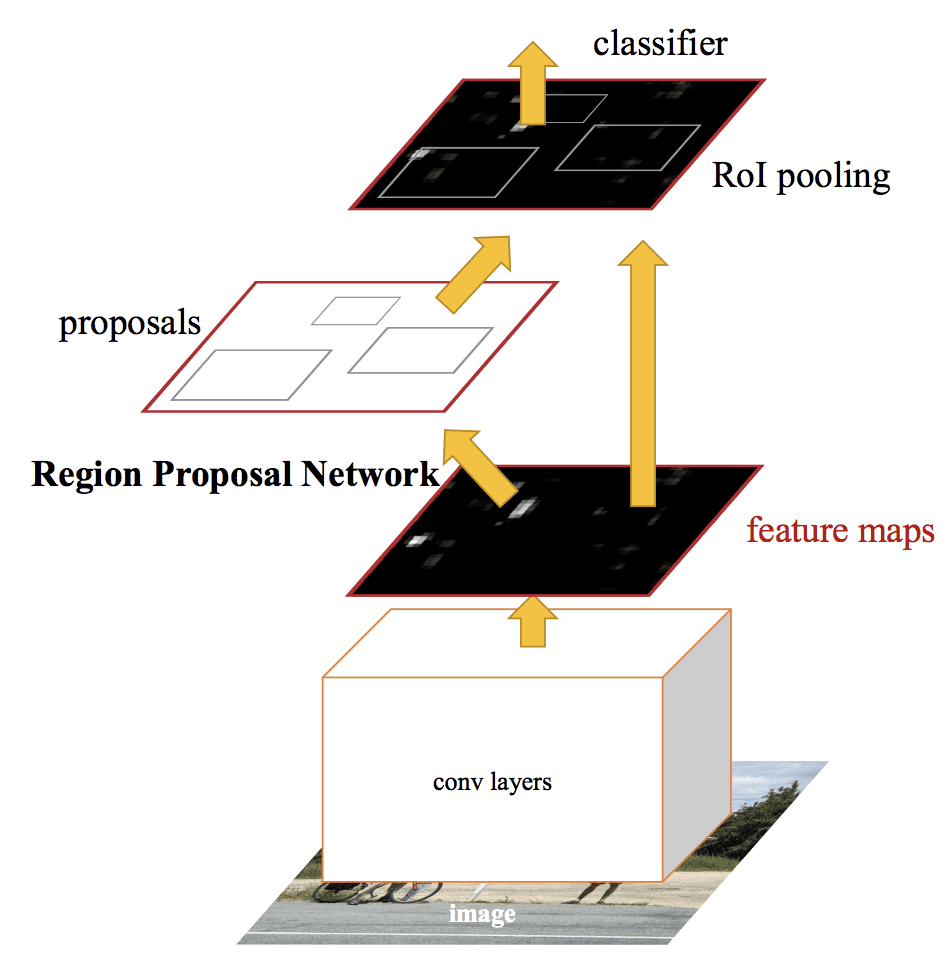
Summary of te Faster R-CNN Model Architecture.Taget fra: Faster R-CNN: RPN fungerer ved at tage output fra en forud trænet dyb CNN, såsom VGG-16, og sende et lille netværk over funktionskortet og udstede flere regionsforslag og en klasseforudsigelse for hver. Regionsforslagene er afgrænsende bokse, baseret på såkaldte ankerkasser eller foruddefinerede former, der er designet til at fremskynde og forbedre forslaget af regioner. Klasseprædiktionen er binær og angiver tilstedeværelsen af et objekt eller ej, såkaldt “objectness” for den foreslåede region.
Der anvendes en procedure med vekslende træning, hvor begge undernetværk trænes på samme tid, om end forskudt. Dette gør det muligt at skræddersy eller finjustere parametrene i feature detector deep CNN’en til begge opgaver på samme tid.
I skrivende stund er denne Faster R-CNNN-arkitektur toppen af familien af modeller og opnår fortsat næsten state-of-the-art-resultater på objektgenkendelsesopgaver. En yderligere udvidelse tilføjer understøttelse af billedsegmentering, som er beskrevet i papiret 2017 paper “Mask R-CNN.”
Python og C++ (Caffe) kildekoden til Fast R-CNN som beskrevet i papiret blev gjort tilgængelig i et GitHub repository.
YOLO-modelfamilie
En anden populær familie af objektgenkendelsesmodeller omtales kollektivt som YOLO eller “You Only Look Once”, udviklet af Joseph Redmon, et al.
R-CNN-modellerne kan generelt være mere præcise, men YOLO-modelfamilien er hurtig, meget hurtigere end R-CNN, og opnår objektdetektion i realtid.
YOLO
YOLO-modellen blev først beskrevet af Joseph Redmon, et al. i 2015-artiklen med titlen “You Only Look Once: Unified, Real-Time Object Detection”. Bemærk, at Ross Girshick, der har udviklet R-CNN, også var forfatter og bidragyder til dette arbejde, dengang hos Facebook AI Research.
Metoden indebærer et enkelt neuralt netværk, der er trænet fra ende til anden, og som tager et fotografi som input og forudsiger bounding boxes og klasseetiketter for hver bounding box direkte. Teknikken giver lavere forudsigelsesnøjagtighed (f.eks. flere lokaliseringsfejl), selv om den fungerer med 45 billeder pr. sekund og op til 155 billeder pr. sekund for en hastighedsoptimeret version af modellen.
Vores forenede arkitektur er ekstremt hurtig. Vores YOLO-grundmodel behandler billeder i realtid med 45 billeder i sekundet. En mindre version af netværket, Fast YOLO, behandler forbløffende 155 billeder i sekundet …
– You Only Look Once: Unified, Real-Time Object Detection, 2015.
Modellen fungerer ved først at opdele det indgående billede i et gitter af celler, hvor hver celle er ansvarlig for at forudsige en bounding box, hvis centrum af en bounding box falder inden for cellen. Hver gittercelle forudsiger en bounding box, der involverer x-, y-koordinaten og bredden og højden samt tilliden. En klasseprædiktion er også baseret på hver celle.
For eksempel kan et billede opdeles i et gitter på 7×7, og hver celle i gitteret kan forudsige 2 afgrænsende bokse, hvilket resulterer i 94 foreslåede forudsigelser af afgrænsende bokse. Klassesandsynlighedskortet og de afgrænsede bokse med konfidens kombineres derefter til et endeligt sæt af afgrænsede bokse og klasseetiketter. Billedet, der er taget fra papiret nedenfor, opsummerer modellens to output.
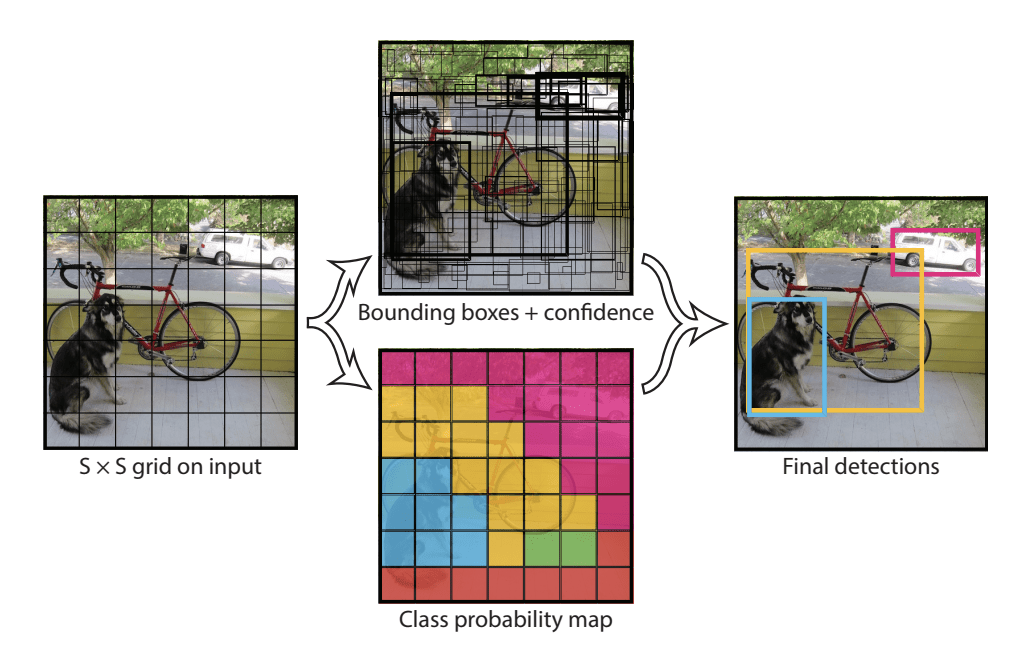
Summary of Predictions made by YOLO Model.Taget fra: You Only Look Once: Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) og YOLOv3
Modellen blev opdateret af Joseph Redmon og Ali Farhadi i et forsøg på at forbedre modellens ydeevne yderligere i deres artikel fra 2016 med titlen “YOLO9000: Better, Faster, Stronger.”
Selv om denne variant af modellen omtales som YOLO v2, beskrives en instans af modellen, der blev trænet på to datasæt til genkendelse af objekter parallelt, og som var i stand til at forudsige 9.000 objektklasser, hvorfor den fik navnet “YOLO9000″.”
Der blev foretaget en række trænings- og arkitektoniske ændringer i modellen, såsom brug af batch-normalisering og inputbilleder i høj opløsning.
Lige Faster R-CNN gør YOLOv2-modellen brug af ankerkasser, foruddefinerede bounding boxes med nyttige former og størrelser, der skræddersys under træningen. Valget af afgrænsende bokse til billedet forbehandles ved hjælp af en k-means-analyse på træningsdatasættet.
Væsentligt er, at den forudsagte repræsentation af de afgrænsende bokse ændres, så små ændringer har en mindre dramatisk effekt på forudsigelserne, hvilket resulterer i en mere stabil model. I stedet for at forudsige position og størrelse direkte forudsiges forskydninger for flytning og omformning af de foruddefinerede ankerkasser i forhold til en gittercelle og dæmpes af en logistisk funktion.
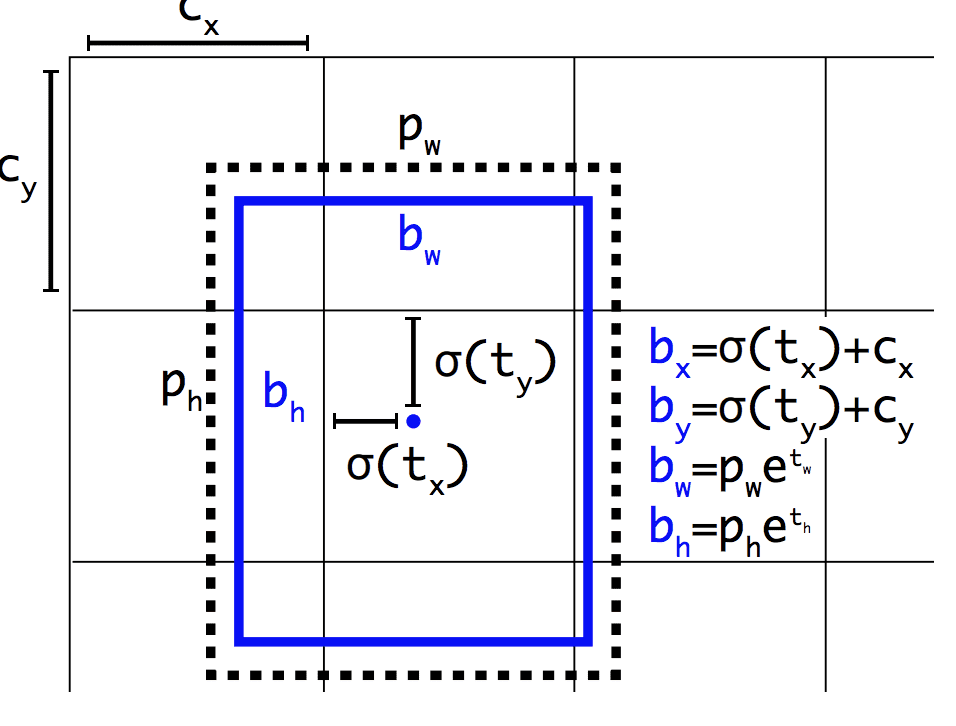
Eksempel på den repræsentation, der vælges ved forudsigelse af bounding box position og formTaget fra: YOLO9000: Better, Faster, Stronger
Flere forbedringer af modellen blev foreslået af Joseph Redmon og Ali Farhadi i deres artikel fra 2018 med titlen “YOLOv3: An Incremental Improvement”. Forbedringerne var rimeligt små, herunder et dybere feature detektor-netværk og mindre repræsentative ændringer.
Forther Reading
Dette afsnit indeholder flere ressourcer om emnet, hvis du ønsker at gå dybere ned i emnet.
Papers
- ImageNet Large Scale Visual Recognition Challenge, 2015.
R-CNN Family Papers
- Rich feature hierarchies for accurate object detection and semantic segmentation, 2013.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, 2014.
- Fast R-CNN, 2015.
- Faster R-CNN: Mod Real-Time Object Detection with Region Proposal Networks, 2016.
- Mask R-CNN, 2017.
YOLO Family Papers
- You Only Look Once: Unified, Real-Time Object Detection, 2015.
- YOLO9000: Better, Faster, Stronger, 2016.
- YOLOv3: An Incremental Improvement, 2018.
Code Projects
- R-CNN: Regions with Convolutional Neural Network Features, GitHub.
- Fast R-CNN, GitHub.
- Faster R-CNN Python Code, GitHub.
- YOLO, GitHub.
Resources
- Ross Girshick, Hjemmeside: Ross Girshick.
- Joseph Redmon, Hjemmeside.
- YOLO: Real-Time Object Detection, Hjemmeside.
Artikler
- A Brief History of CNNs in Image Segmentation: Fra R-CNN til Mask R-CNN, 2017.
- Object Detection for Dummies Part 3: R-CNN Family, 2017.
- Object Detection Part 4: Fast Detection Models, 2018.
Summary
In this post, you discovered a gentle introduction to the problem of object recognition and state-of-the-art deep learning models designed to address it.
Specifikt lærte du:
- Objektgenkendelse er henviser til en samling af relaterede opgaver til identifikation af objekter i digitale fotografier.
- Region-Based Convolutional Neural Networks, eller R-CNNs, er en familie af teknikker til løsning af objektlokaliserings- og genkendelsesopgaver, der er designet med henblik på modelydelse.
- You Only Look Once, eller YOLO, er en anden familie af teknikker til objektgenkendelse, der er designet med henblik på hastighed og realtidsbrug.
Har du spørgsmål?
Sæt dine spørgsmål i kommentarerne nedenfor, og jeg vil gøre mit bedste for at svare.
Udvikle Deep Learning-modeller til Vision i dag!

Udvikle dine egne Vision-modeller på få minutter
…med blot et par linjer python-kode
Opdag hvordan i min nye E-bog:
Deep Learning for Computer Vision
Den indeholder selvstuderende tutorials om emner som:
klassificering, objektdetektion (yolo og rcnn), ansigtsgenkendelse (vggface og facenet), datapræparation og meget mere…
Finally Bring Deep Learning to your Vision Projects
Skip akademikerne. Just Results.
Se hvad der er inde i