Die Kolmogorov-Smirnov (KS)-Statistik ist eine der wichtigsten Metriken zur Validierung von Vorhersagemodellen. Sie wird häufig im BFSI-Bereich verwendet. Wenn Sie zu einem Risiko- oder Marketing-Analyse-Team gehören, das an einem Projekt im Bankwesen arbeitet, haben Sie sicher schon von dieser Metrik gehört.
Was ist KS-Statistik?
Sie steht für Kolmogorov-Smirnov, benannt nach Andrey Kolmogorov und Nikolai Smirnov. Sie vergleicht die beiden kumulativen Verteilungen und gibt die maximale Differenz zwischen ihnen an. Es handelt sich um einen nicht-parametrischen Test, d.h. es müssen keine Annahmen in Bezug auf die Verteilung der Daten geprüft werden. Beim KS-Test besagt die Nullhypothese, dass die beiden kumulativen Verteilungen ähnlich sind. Die Ablehnung der Nullhypothese bedeutet, dass die kumulativen Verteilungen unterschiedlich sind.
In der Datenwissenschaft werden die kumulativen Verteilungen von Ereignissen und Nicht-Ereignissen verglichen, und KS ist dort, wo es einen maximalen Unterschied zwischen den beiden Verteilungen gibt. Mit einfachen Worten, es hilft uns zu verstehen, wie gut unser Vorhersagemodell in der Lage ist, zwischen Ereignissen und Nicht-Ereignissen zu unterscheiden.
Angenommen, Sie erstellen ein Propensity-Modell, dessen Ziel es ist, Interessenten zu identifizieren, die wahrscheinlich ein bestimmtes Produkt kaufen werden. In diesem Fall ist die abhängige Variable (Zielvariable) binär und hat nur zwei Ausprägungen: 0 (Nicht-Ereignis) oder 1 (Ereignis). „Ereignis“ bedeutet Personen, die das Produkt gekauft haben. „Nicht-Ereignis“ bezieht sich auf Personen, die das Produkt nicht gekauft haben. Die KS-Statistik misst, ob das Modell in der Lage ist, zwischen potenziellen und nicht potenziellen Käufern zu unterscheiden.
Zwei Möglichkeiten zur Messung der KS-Statistik
Diese Methode ist die gebräuchlichste Methode zur Berechnung der KS-Statistik für die Validierung binärer Vorhersagemodelle. Siehe die nachstehenden Schritte.
- Vor der Berechnung der KS müssen zwei Variablen vorliegen. Die eine ist die abhängige Variable, die binär sein sollte. Die zweite ist die vorhergesagte Wahrscheinlichkeitszahl, die aus dem statistischen Modell generiert wird.
- Erstellen Sie Dezile auf der Grundlage der vorhergesagten Wahrscheinlichkeitsspalten, was bedeutet, dass die Wahrscheinlichkeit in 10 Teile geteilt wird. Das erste Dezil sollte den höchsten Wahrscheinlichkeitswert enthalten.
- Berechnen Sie den kumulativen Prozentsatz von Ereignissen und Nicht-Ereignissen in jedem Dezil und berechnen Sie dann die Differenz zwischen diesen beiden kumulativen Verteilungen.
- KS ist der Wert, bei dem die Differenz am größten ist
- Wenn KS in den ersten drei Dezilen liegt und der Wert über 40 liegt, wird es als ein gutes Vorhersagemodell angesehen. Gleichzeitig ist es wichtig, das Modell zu validieren, indem auch andere Leistungskennzahlen überprüft werden, um zu bestätigen, dass das Modell nicht unter einem Overfitting-Problem leidet.
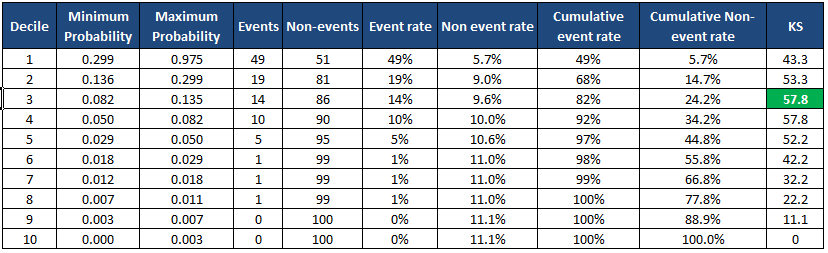
Python : KS Statistics Decile Method
Ich habe ein Datenbeispiel als Beispiel vorbereitet. Der Datensatz enthält zwei Spalten namens y und p.yist eine abhängige Variable.pbezieht sich auf die vorhergesagte Wahrscheinlichkeit.
import pandas as pdimport numpy as npdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
def ks(data=None,target=None, prob=None): data = 1 - data data = pd.qcut(data, 10) grouped = data.groupby('bucket', as_index = False) kstable = pd.DataFrame() kstable = grouped.min() kstable = grouped.max() kstable = grouped.sum() kstable = grouped.sum() kstable = kstable.sort_values(by="min_prob", ascending=False).reset_index(drop = True) kstable = (kstable.events / data.sum()).apply('{0:.2%}'.format) kstable = (kstable.nonevents / data.sum()).apply('{0:.2%}'.format) kstable=(kstable.events / data.sum()).cumsum() kstable=(kstable.nonevents / data.sum()).cumsum() kstable = np.round(kstable-kstable, 3) * 100 #Formating kstable= kstable.apply('{0:.2%}'.format) kstable= kstable.apply('{0:.2%}'.format) kstable.index = range(1,11) kstable.index.rename('Decile', inplace=True) pd.set_option('display.max_columns', 9) print(kstable) #Display KS from colorama import Fore print(Fore.RED + "KS is " + str(max(kstable))+"%"+ " at decile " + str((kstable.index==max(kstable)]))) return(kstable)
mydf = ks(data=df,target="y", prob="p")
-
databezieht sich auf einen Pandas-Datenrahmen, der sowohl die abhängige Variable als auch die Wahrscheinlichkeitswerte enthält. -
targetbezieht sich auf den Spaltennamen der abhängigen Variable -
probbezieht sich auf den Spaltennamen der vorhergesagten Wahrscheinlichkeit
Sie gibt die Informationen jedes Dezils in Tabellenform zurück und druckt auch den KS-Score unterhalb der Tabelle aus. Es erzeugt auch eine Tabelle in einem neuen Datenrahmen.
min_prob max_prob events nonevents event_rate nonevent_rate \Decile 1 0.298894 0.975404 49 51 49.00% 5.67% 2 0.135598 0.298687 19 81 19.00% 9.00% 3 0.082170 0.135089 14 86 14.00% 9.56% 4 0.050369 0.082003 10 90 10.00% 10.00% 5 0.029415 0.050337 5 95 5.00% 10.56% 6 0.018343 0.029384 1 99 1.00% 11.00% 7 0.011504 0.018291 1 99 1.00% 11.00% 8 0.006976 0.011364 1 99 1.00% 11.00% 9 0.002929 0.006964 0 100 0.00% 11.11% 10 0.000073 0.002918 0 100 0.00% 11.11% cum_eventrate cum_noneventrate KS Decile 1 49.00% 5.67% 43.3 2 68.00% 14.67% 53.3 3 82.00% 24.22% 57.8 4 92.00% 34.22% 57.8 5 97.00% 44.78% 52.2 6 98.00% 55.78% 42.2 7 99.00% 66.78% 32.2 8 100.00% 77.78% 22.2 9 100.00% 88.89% 11.1 10 100.00% 100.00% 0.0 KS is 57.8% at decile 3
Mit der Python-Bibliothekscipykönnen wir die KS-Statistik für zwei Stichproben berechnen. Sie hat zwei Parameter – data1 und data2. In data1 geben wir alle Wahrscheinlichkeitswerte ein, die den Nicht-Ereignissen entsprechen. In data2 werden die Wahrscheinlichkeitswerte für Ereignisse eingegeben.
from scipy.stats import ks_2sampdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")ks_2samp(df.loc, df.loc)
Das Ergebnis ist ein KS-Score von 0,6033 und ein p-Wert von weniger als 0,01, was bedeutet, dass die Nullhypothese zurückgewiesen werden kann und die Verteilung von Ereignissen und Nicht-Ereignissen unterschiedlich ist.
OutputKs_2sampResult(statistic=0.6033333333333333, pvalue=1.1227180680661939e-29)
Der KS-Score von Methode 2 unterscheidet sich geringfügig von Methode 1, da der zweite Score auf Zeilenebene berechnet wird und der erste nach der Konvertierung der Daten in zehn Teile berechnet wird.