
In „Anomaly Detection with Autoencoders Made Easy“ habe ich erwähnt, dass Autoencoders in der Dimensionsreduktion und der Rauschunterdrückung von Bildern weit verbreitet sind. Seitdem haben viele Leser gefragt, ob ich das Thema der Rauschunterdrückung mit Autoencodern behandeln kann. Das ist die Motivation für diesen Beitrag.
Die Modellierung von Bilddaten erfordert einen besonderen Ansatz in der Welt der neuronalen Netze. Das bekannteste neuronale Netzwerk für die Modellierung von Bilddaten ist das Convolutional Neural Network (CNN, oder ConvNet) oder auch Convolutional Autoencoder genannt. In diesem Beitrag beginne ich mit einer sanften Einführung in die Bilddaten, da nicht alle Leser auf dem Gebiet der Bilddaten tätig sind (Sie können diesen Abschnitt gerne überspringen, wenn Sie bereits damit vertraut sind). Anschließend beschreibe ich ein einfaches neuronales Standardnetzwerk für die Bilddaten. Dies gibt mir die Gelegenheit zu demonstrieren, warum Convolutional Autoencoders die bevorzugte Methode im Umgang mit Bilddaten sind. Vor allem werde ich zeigen, wie die Convolutional Autoencoders das Rauschen in einem Bild reduzieren. Ich verwende das Keras-Modul und die MNIST-Daten in diesem Beitrag. Das Notizbuch ist über diesen Link verfügbar. Keras ist eine High-Level-API für neuronale Netze, die in Python geschrieben wurde und auf TensorFlow aufsetzen kann. Dieser Beitrag ist eine Erweiterung meines früheren Beitrags „What Is Image Recognition?“, den Sie sich unbedingt ansehen sollten.
Ich hielt es für hilfreich, die drei großen Datenkategorien zu erwähnen. Die drei Datenkategorien sind: (1) unkorrelierte Daten (im Gegensatz zu seriellen Daten), (2) serielle Daten (einschließlich Text- und Sprachstromdaten) und (3) Bilddaten. Beim Deep Learning gibt es drei grundlegende Varianten für jede Datenkategorie: (1) das standardmäßige neuronale Feedforward-Netzwerk, (2) RNN/LSTM und (3) Convolutional NN (CNN). Lesern, die auf der Suche nach Tutorials für jeden Typ sind, empfehlen wir „Explaining Deep Learning in a Regression-Friendly Way“ für (1), den aktuellen Artikel „A Technical Guide for RNN/LSTM/GRU on Stock Price Prediction“ für (2) und „Deep Learning with PyTorch Is Not Torturing“, „What Is Image Recognition?“, „Anomaly Detection with Autoencoders Made Easy“ und „Convolutional Autoencoders for Image Noise Reduction“ für (3). Sie können den zusammenfassenden Artikel „Dataman Learning Paths – Build Your Skills, Drive Your Career“ als Lesezeichen speichern.
Understand Image Data
Ein Bild besteht aus „Pixeln“, wie in Abbildung (A) dargestellt. In einem Schwarz-Weiß-Bild wird jedes Pixel durch eine Zahl zwischen 0 und 255 dargestellt. Die meisten Bilder verwenden heute 24-Bit-Farben oder mehr. Ein RGB-Farbbild bedeutet, dass die Farbe in einem Pixel eine Kombination aus Rot, Grün und Blau ist, wobei jede der Farben von 0 bis 255 reicht. Das RGB-Farbsystem baut alle Farben aus der Kombination der Farben Rot, Grün und Blau auf, wie in diesem RGB-Farbgenerator gezeigt. Ein Pixel enthält also einen Satz von drei Werten RGB(102, 255, 102), der sich auf die Farbe #66ff66 bezieht.

Ein Bild mit einer Breite von 800 Pixeln und einer Höhe von 600 Pixeln hat 800 x 600 = 480.000 Pixel = 0,48 Megapixel („Megapixel“ ist 1 Million Pixel). Ein Bild mit einer Auflösung von 1024×768 ist ein Raster mit 1.024 Spalten und 768 Zeilen, das also 1.024 × 768 = 0,78 Megapixel enthält.
MNIST
Die MNIST-Datenbank (Modified National Institute of Standards and Technology database) ist eine große Datenbank mit handgeschriebenen Ziffern, die häufig zum Training verschiedener Bildverarbeitungssysteme verwendet wird. Der Trainingsdatensatz in Keras hat 60.000 Datensätze und der Testdatensatz hat 10.000 Datensätze. Jeder Datensatz hat 28 x 28 Pixel.
Wie sehen sie aus? Verwenden wir matplotlib und seine Bildfunktion imshow(), um die ersten zehn Datensätze anzuzeigen.

Stapelt die Bilddaten für das Training
Um ein neuronales Netzwerk für das Modelltraining zu verwenden, können wir alle 28 x 28 = 784 Werte in einer Spalte stapeln. Die gestapelte Spalte für den ersten Datensatz sieht wie folgt aus: (mit x_train.reshape(1,784)):

Dann können wir das Modell mit einem standardmäßigen neuronalen Netz trainieren, wie in Abbildung (B) dargestellt. Jeder der 784 Werte ist ein Knoten in der Eingabeschicht. Aber Moment mal, haben wir nicht viele Informationen verloren, als wir die Daten gestapelt haben? Ja. Die räumlichen und zeitlichen Beziehungen in einem Bild wurden verworfen. Das ist ein großer Verlust an Informationen. Sehen wir uns an, wie die Convolutional Autoencoders räumliche und zeitliche Informationen beibehalten können.

Warum sind die Convolutional Autoencoders für Bilddaten geeignet?
Wir sehen einen großen Informationsverlust, wenn wir die Daten zerschneiden und stapeln. Anstatt die Daten zu stapeln, behalten die Faltungs-Autokodierer die räumlichen Informationen der Eingangsbilddaten bei und extrahieren die Informationen sanft in der so genannten Faltungsschicht. Abbildung (D) zeigt, dass ein flaches 2D-Bild in ein dickes Quadrat (Conv1) extrahiert wird, das dann in ein langes kubisches (Conv2) und ein weiteres längeres kubisches (Conv3) übergeht. Dieses Verfahren dient dazu, die räumlichen Beziehungen in den Daten beizubehalten. Dies ist der Kodierungsprozess in einem Autoencoder. In der Mitte befindet sich ein voll verschalteter Autoencoder, dessen verborgene Schicht nur aus 10 Neuronen besteht. Danach folgt der Dekodierungsprozess, der die kubischen Elemente in ein flaches 2D-Bild umwandelt. Der Encoder und der Decoder sind in Abbildung (D) symmetrisch. Sie müssen nicht symmetrisch sein, aber die meisten Praktiker übernehmen einfach diese Regel, wie in „Anomaly Detection with Autoencoders made easy“ erläutert.

Wie funktioniert der Convolutional Autoencoder?
Die obige Datenextraktion scheint magisch. Wie funktioniert das wirklich? Sie beinhaltet die folgenden drei Schichten: Die Faltungsschicht, die reLu-Schicht und die Pooling-Schicht.

- Die Faltungsschicht
Der Faltungsschritt erzeugt viele kleine Teile, die Merkmalskarten oder Merkmale genannt werden, wie die grünen, roten oder marineblauen Quadrate in Abbildung (E). Diese Quadrate bewahren die Beziehung zwischen den Pixeln im Eingabebild. Lassen Sie jedes Merkmal durch das Originalbild scannen, wie in Abbildung (F) gezeigt. Dieser Prozess zur Erstellung der Scores wird Filterung genannt.
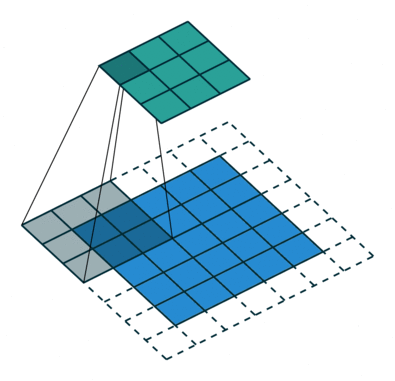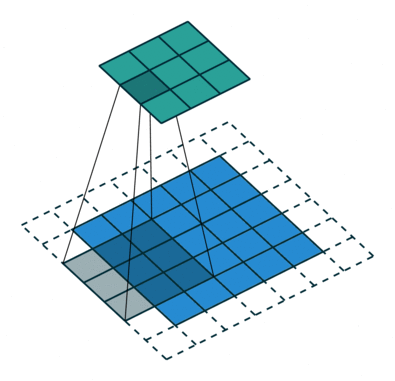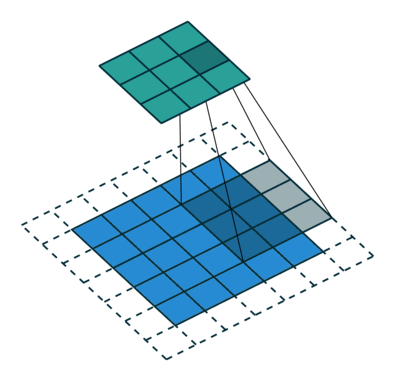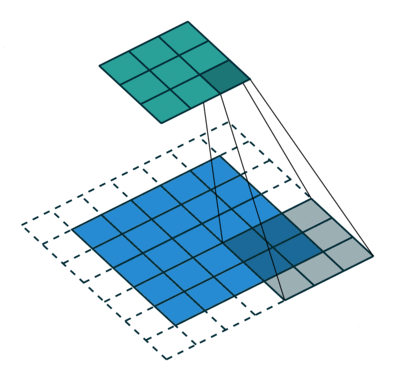
Nach dem Scannen des Originalbildes ergibt jedes Merkmal ein gefiltertes Bild mit hohen und niedrigen Punktzahlen, wie in Abbildung (G) dargestellt. Bei einer perfekten Übereinstimmung gibt es eine hohe Punktzahl in diesem Feld. Gibt es eine geringe oder keine Übereinstimmung, ist die Punktzahl niedrig oder null. Im roten Quadrat wurden beispielsweise vier Bereiche im Originalbild gefunden, die eine perfekte Übereinstimmung mit dem Merkmal aufweisen, so dass die Punktzahl für diese vier Bereiche hoch ist.

Mehr Filter bedeuten eine größere Anzahl von Merkmalen, die das Modell extrahieren kann. Mehr Merkmale bedeuten jedoch auch eine längere Trainingszeit. Es ist daher ratsam, eine möglichst geringe Anzahl von Filtern zu verwenden, um die Merkmale zu extrahieren.
1.1 Padding
Wie bestimmen die Merkmale die Übereinstimmung? Ein Hyper-Parameter ist Padding, der zwei Möglichkeiten bietet: (i) Auffüllen des Originalbildes mit Nullen, um das Merkmal anzupassen, oder (ii) Weglassen des Teils des Originalbildes, der nicht passt, und Beibehalten des gültigen Teils.
1.2 Strides
Die Faltungsschicht enthält einen weiteren Parameter: den Stride. Es ist die Anzahl der Pixel, die über die Eingabematrix verschoben werden. Wenn der Stride 1 ist, verschieben die Filter jeweils 1 Pixel auf einmal. Wir werden ihn in unserem Keras-Code als Hyper-Parameter sehen.
2. ReLUs Step
Die Rectified Linear Unit (ReLU) ist der Schritt, der dem Schritt in den typischen neuronalen Netzen entspricht. Sie korrigiert jeden negativen Wert auf Null, um zu gewährleisten, dass sich die Mathematik korrekt verhält.
3. Max Pooling Layer
Pooling verkleinert die Bildgröße. In Abbildung (H) durchläuft ein 2 x 2-Fenster, die so genannte Poolgröße, jedes der gefilterten Bilder und weist den Maximalwert dieses 2 x 2-Fensters einem 1 x 1-Quadrat in einem neuen Bild zu. Wie in Abbildung (H) dargestellt, ist der Höchstwert im ersten 2 x 2-Fenster ein hoher Wert (rot dargestellt), so dass der hohe Wert dem 1 x 1-Quadrat zugewiesen wird.

Neben dem Maximalwert gibt es noch weitere, weniger gebräuchliche Pooling-Methoden wie das Average Pooling (Durchschnittswert) oder das Sum Pooling (Summe).

Nach dem Pooling entsteht ein neuer Stapel kleinerer gefilterter Bilder. Jetzt teilen wir die kleineren gefilterten Bilder auf und stapeln sie in eine Liste, wie in Abbildung (J) gezeigt.
Modell in Keras
Die oben genannten drei Schichten sind die Bausteine im neuronalen Faltungsnetzwerk. Keras bietet die folgenden zwei Funktionen:
Sie können viele Faltungsschichten in den Faltungs-Autoencodern aufbauen. In Abbildung (E) gibt es drei Schichten mit den Bezeichnungen Conv1, Conv2 und Conv3 im Kodierungsteil. Wir bauen also entsprechend auf.
- Der Code unten
input_img = Input(shape=(28,28,1)erklärt, dass das 2D-Eingabebild 28 mal 28 ist. - Dann baut er die drei Schichten Conv1, Conv2 und Conv3 auf.
- Beachte, dass Conv1 innerhalb von Conv2 und Conv2 innerhalb von Conv3 ist.
- Der
paddinggibt an, was zu tun ist, wenn der Filter nicht gut zum Eingabebild passt.padding='valid'bedeutet, dass der Teil des Bildes weggelassen wird, wenn der Filter nicht passt;padding='same'füllt das Bild mit Nullen auf, um das Bild anzupassen.
Dann geht es weiter mit dem Dekodierungsprozess. So hat der decode Teil unten alle kodiert und dekodiert.
Die Keras api erfordert die Deklaration des Modells und der Optimierungsmethode:
-
Model(inputs= input_img,outputs= decoded): Das Modell wird alle Schichten enthalten, die für die Berechnung der Ausgabendecodedbei gegebenen Eingabedateninput_imgerforderlich sind.compile(optimizer='adadelta',loss='binary_crossentropy'): Der Optimierer führt eine Optimierung durch, wie es der Gradient Decent tut. Die gebräuchlichsten sind stochastic gradient decent (SGD), Adapted gradient (Adagrad) und Adadelta, das eine Erweiterung von Adagrad ist. Weitere Einzelheiten finden Sie in der Dokumentation zum Keras-Optimierer. Die Verlustfunktionen sind in der Keras-Verlustdokumentation zu finden.
Nachfolgend trainiere ich das Modell mit x_train als Eingabe und Ausgabe. batch_size ist die Anzahl der Stichproben und epoch ist die Anzahl der Iterationen. Ich gebe shuffle=True an, damit die Trainingsdaten vor jeder Epoche neu gemischt werden müssen.
Wir können die ersten zehn Originalbilder und die Vorhersagen für dieselben zehn Bilder ausgeben.
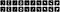
Wie baut man einen Convolution Autoencoder zur Rauschunterdrückung auf?
Die Idee der Rauschunterdrückung besteht darin, ein Modell mit verrauschten Daten als Eingaben und den entsprechenden klaren Daten als Ausgaben zu trainieren. Dies ist der einzige Unterschied zu dem obigen Modell. Fügen wir den Daten zunächst Rauschen hinzu.
Die ersten zehn verrauschten Bilder sehen wie folgt aus:

Dann trainieren wir das Modell mit den verrauschten Daten als Input und den sauberen Daten als Output.
Abschließend geben wir die ersten zehn verrauschten Bilder sowie die entsprechenden entrauschten Bilder aus.
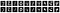
Das Notebook ist über diesen Link verfügbar.
Gibt es einen Code für vortrainierte CNNs, den ich verwenden kann?
Ja. Wenn Sie daran interessiert sind, den Code zu lernen, hat Keras mehrere vortrainierte CNNs, einschließlich Xception, VGG16, VGG19, ResNet50, InceptionV3, InceptionResNetV2, MobileNet, DenseNet, NASNet und MobileNetV2. Erwähnenswert ist auch die große Bilddatenbank ImageNet, die Sie zu Forschungszwecken beitragen oder herunterladen können.