Last Updated on January 27, 2021
Für Anfänger kann es eine Herausforderung sein, zwischen verschiedenen verwandten Computer Vision Aufgaben zu unterscheiden.
Zum Beispiel ist die Bildklassifizierung einfach, aber die Unterschiede zwischen Objektlokalisierung und Objekterkennung können verwirrend sein, vor allem, wenn alle drei Aufgaben genauso gut als Objekterkennung bezeichnet werden können.
Bei der Bildklassifizierung geht es darum, einem Bild eine Klassenbezeichnung zuzuweisen, während bei der Objektlokalisierung ein Begrenzungsrahmen um ein oder mehrere Objekte in einem Bild gezogen wird. Die Objekterkennung ist anspruchsvoller und kombiniert diese beiden Aufgaben, indem sie einen Begrenzungsrahmen um jedes Objekt von Interesse im Bild zeichnet und ihm eine Klassenbezeichnung zuweist. Alle diese Probleme zusammen werden als Objekterkennung bezeichnet.
In diesem Beitrag finden Sie eine sanfte Einführung in das Problem der Objekterkennung und modernste Deep-Learning-Modelle, die dafür entwickelt wurden.
Nach der Lektüre dieses Beitrags werden Sie wissen:
- Objekterkennung bezieht sich auf eine Sammlung von verwandten Aufgaben zur Identifizierung von Objekten in digitalen Fotos.
- Region-Based Convolutional Neural Networks, oder R-CNNs, sind eine Familie von Techniken zur Bewältigung von Objektlokalisierungs- und -erkennungsaufgaben, die auf Modellleistung ausgelegt sind.
- You Only Look Once, oder YOLO, ist eine zweite Familie von Techniken zur Objekterkennung, die auf Geschwindigkeit und Echtzeiteinsatz ausgelegt sind.
Starten Sie Ihr Projekt mit meinem neuen Buch Deep Learning for Computer Vision, das Schritt-für-Schritt-Tutorials und die Python-Quellcode-Dateien für alle Beispiele enthält.
Lassen Sie uns beginnen.

Eine sanfte Einführung in die Objekterkennung mit Deep Learning
Foto von Bart Everson, einige Rechte vorbehalten.
Überblick
Dieses Tutorial ist in drei Teile gegliedert; sie sind:
- Was ist Objekterkennung?
- R-CNN-Modellfamilie
- YOLO-Modellfamilie
Wollen Sie Ergebnisse mit Deep Learning für Computer Vision?
Machen Sie jetzt meinen kostenlosen 7-tägigen E-Mail-Crashkurs (mit Beispielcode).
Klicken Sie, um sich anzumelden und auch eine kostenlose PDF-Ebook-Version des Kurses zu erhalten.
Laden Sie Ihren KOSTENLOSEN Mini-Kurs herunter
Was ist Objekterkennung?
Objekterkennung ist ein allgemeiner Begriff, der eine Sammlung verwandter Computer-Vision-Aufgaben beschreibt, bei denen es um die Identifizierung von Objekten in digitalen Fotografien geht.
Bildklassifizierung beinhaltet die Vorhersage der Klasse eines Objekts in einem Bild. Bei der Objektlokalisierung geht es darum, die Position eines oder mehrerer Objekte in einem Bild zu identifizieren und einen Umkreis um sie herum zu ziehen. Die Objekterkennung kombiniert diese beiden Aufgaben und lokalisiert und klassifiziert ein oder mehrere Objekte in einem Bild.
Wenn ein Anwender oder Praktiker von „Objekterkennung“ spricht, meint er oft „Objekterkennung“.
… wir werden den Begriff Objekterkennung im weiteren Sinne verwenden, um sowohl die Bildklassifizierung (eine Aufgabe, die einen Algorithmus erfordert, um zu bestimmen, welche Objektklassen im Bild vorhanden sind) als auch die Objekterkennung (eine Aufgabe, die einen Algorithmus erfordert, um alle im Bild vorhandenen Objekte zu lokalisieren
– ImageNet Large Scale Visual Recognition Challenge, 2015.
So können wir zwischen diesen drei Computer-Vision-Aufgaben unterscheiden:
- Image Classification: Vorhersage der Art oder Klasse eines Objekts in einem Bild.
- Input: Ein Bild mit einem einzelnen Objekt, z. B. ein Foto.
- Ausgabe: Eine Klassenbezeichnung (z. B. eine oder mehrere ganze Zahlen, die auf Klassenbezeichnungen abgebildet werden).
- Objektlokalisierung: Das Vorhandensein von Objekten in einem Bild lokalisieren und ihre Position mit einem Begrenzungsrahmen angeben.
- Eingabe: Ein Bild mit einem oder mehreren Objekten, z. B. ein Foto.
- Ausgabe: Ein oder mehrere Begrenzungsrahmen (z. B. definiert durch einen Punkt, eine Breite und eine Höhe).
- Objekterkennung: Das Vorhandensein von Objekten mit einer Bounding Box und Typen oder Klassen der gefundenen Objekte in einem Bild lokalisieren.
- Eingabe: Ein Bild mit einem oder mehreren Objekten, z. B. ein Foto.
- Ausgabe: Eine oder mehrere Boundingboxen (z. B. definiert durch einen Punkt, eine Breite und eine Höhe) und ein Klassenlabel für jede Boundingbox.
Eine weitere Erweiterung dieser Aufschlüsselung von Computer-Vision-Aufgaben ist die Objektsegmentierung, auch „Objektinstanzsegmentierung“ oder „semantische Segmentierung“ genannt, bei der Instanzen erkannter Objekte durch Hervorhebung der spezifischen Pixel des Objekts anstelle einer groben Boundingbox angezeigt werden.
Aus dieser Aufschlüsselung geht hervor, dass sich die Objekterkennung auf eine Reihe anspruchsvoller Computer-Vision-Aufgaben bezieht.
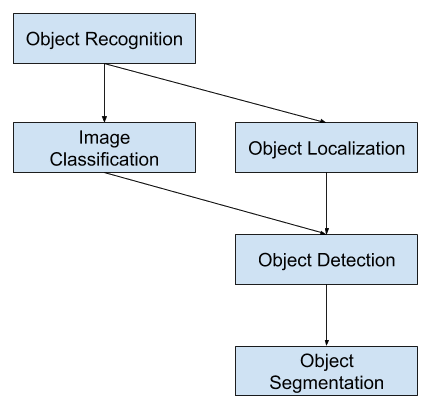
Übersicht über Aufgaben der Computer Vision zur Objekterkennung
Die meisten der jüngsten Innovationen bei Problemen der Bilderkennung sind im Rahmen der Teilnahme an den ILSVRC-Aufgaben entstanden.
Dies ist ein jährlicher akademischer Wettbewerb mit einer separaten Aufgabe für jeden dieser drei Problemtypen, mit der Absicht, unabhängige und separate Verbesserungen auf jeder Ebene zu fördern, die auf breiterer Ebene genutzt werden können. Siehe zum Beispiel die folgende Liste der drei entsprechenden Aufgabentypen aus dem ILSVRC-Review-Papier von 2015:
- Bildklassifizierung: Algorithmen erstellen eine Liste von Objektkategorien, die im Bild vorhanden sind.
- Einzelobjektlokalisierung: Algorithmen erzeugen eine Liste der im Bild vorhandenen Objektkategorien zusammen mit einem achsenausgerichteten Begrenzungsrahmen, der die Position und den Maßstab einer Instanz jeder Objektkategorie angibt.
- Objekterkennung: Algorithmen erzeugen eine Liste von Objektkategorien, die im Bild vorhanden sind, zusammen mit einem achsenausgerichteten Begrenzungsrahmen, der die Position und den Maßstab jeder Instanz jeder Objektkategorie angibt.
Wir sehen, dass die „Einzelobjektlokalisierung“ eine einfachere Version der breiter definierten „Objektlokalisierung“ ist, die die Lokalisierungsaufgaben auf Objekte eines Typs innerhalb eines Bildes beschränkt, was, wie wir annehmen können, eine einfachere Aufgabe ist.
Unten sehen Sie ein Beispiel für den Vergleich von Einzelobjektlokalisierung und Objekterkennung, das dem ILSVRC-Papier entnommen ist. Man beachte den Unterschied in den Erwartungen an die Grundwahrheit in jedem Fall.
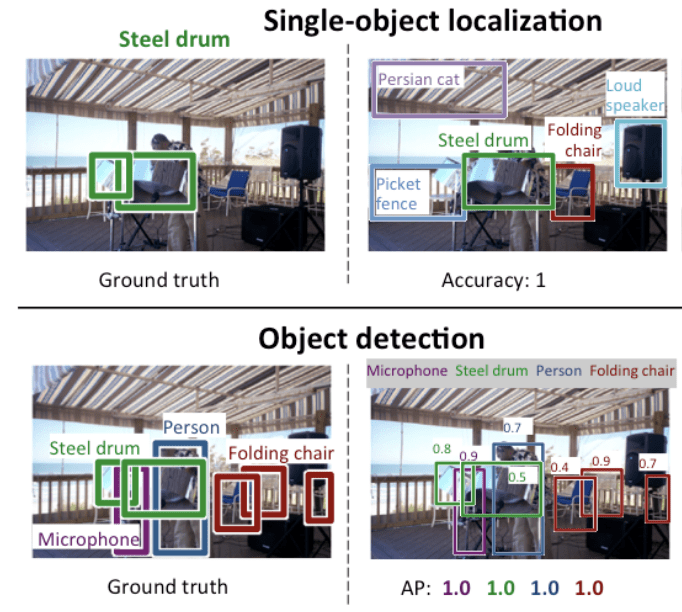
Vergleich zwischen Einzelobjektlokalisierung und Objekterkennung.Taken From: ImageNet Large Scale Visual Recognition Challenge.
Die Leistung eines Modells zur Bildklassifizierung wird anhand des mittleren Klassifizierungsfehlers über die vorhergesagten Klassenlabels bewertet. Die Leistung eines Modells für die Lokalisierung eines einzelnen Objekts wird anhand des Abstands zwischen der erwarteten und der vorhergesagten Bounding Box für die erwartete Klasse bewertet. Die Leistung eines Modells für die Objekterkennung wird anhand der Präzision und des Recalls für jede der am besten übereinstimmenden Bounding Boxen für die bekannten Objekte im Bild bewertet.
Nun, da wir mit dem Problem der Objektlokalisierung und -erkennung vertraut sind, werfen wir einen Blick auf einige aktuelle leistungsstarke Deep Learning-Modelle.
R-CNN-Modellfamilie
Die R-CNN-Methodenfamilie bezieht sich auf das R-CNN, das für „Regions with CNN Features“ oder „Region-Based Convolutional Neural Network“ stehen kann und von Ross Girshick et al. entwickelt wurde.
Dazu gehören die Techniken R-CNN, Fast R-CNN und Faster-RCNN, die für die Objektlokalisierung und Objekterkennung entwickelt und demonstriert wurden.
Lassen Sie uns einen genaueren Blick auf die Highlights jeder dieser Techniken werfen.
R-CNN
Das R-CNN wurde 2014 in der Arbeit von Ross Girshick, et al. von der UC Berkeley mit dem Titel „Rich feature hierarchies for accurate object detection and semantic segmentation“
Es könnte eine der ersten großen und erfolgreichen Anwendungen von faltigen neuronalen Netzen auf das Problem der Objektlokalisierung, -erkennung und -segmentierung gewesen sein. Der Ansatz wurde anhand von Benchmark-Datensätzen demonstriert und erzielte damals die besten Ergebnisse auf dem VOC-2012-Datensatz und dem 200-Klassen-ILSVRC-2013-Objekterkennungsdatensatz.
Das von ihnen vorgeschlagene R-CNN-Modell besteht aus drei Modulen, und zwar:
- Modul 1: Region Proposal. Erzeugt und extrahiert kategorieunabhängige Regionsvorschläge, z.B. Kandidaten-Bounding-Boxen.
- Modul 2: Feature Extractor. Extrahieren von Merkmalen aus jeder Kandidatenregion, z.B. mit Hilfe eines tiefen neuronalen Faltungsnetzwerks.
- Modul 3: Klassifikator. Klassifizierung von Merkmalen als eine der bekannten Klassen, z. B. lineares SVM-Klassifizierungsmodell.
Die Architektur des Modells ist in der folgenden Abbildung zusammengefasst, die dem Papier entnommen wurde.
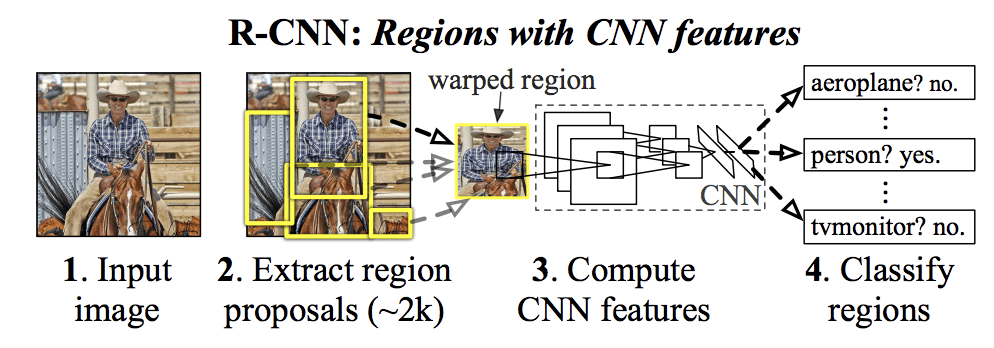
Zusammenfassung der R-CNN-ModellarchitekturEntnommen aus Reichhaltige Merkmalshierarchien für genaue Objekterkennung und semantische Segmentierung.
Eine Computer-Vision-Technik wird verwendet, um Kandidatenregionen oder Bounding-Boxen von potenziellen Objekten im Bild vorzuschlagen, die „selektive Suche“ genannt wird, obwohl die Flexibilität des Designs die Verwendung anderer Algorithmen zur Vorschlagsfindung für Regionen ermöglicht.
Der vom Modell verwendete Merkmalsextraktor war das AlexNet Deep CNN, das den ILSVRC-2012-Wettbewerb zur Bildklassifizierung gewann. Die Ausgabe des CNN war ein Vektor mit 4.096 Elementen, der den Inhalt des Bildes beschreibt und zur Klassifizierung an eine lineare SVM weitergeleitet wird, wobei für jede bekannte Klasse eine SVM trainiert wird.
Es handelt sich um eine relativ einfache und unkomplizierte Anwendung von CNNs auf das Problem der Objektlokalisierung und -erkennung. Ein Nachteil dieses Ansatzes ist, dass er langsam ist, da er eine CNN-basierte Merkmalsextraktion für jede der durch den Algorithmus für Regionenvorschläge erzeugten Kandidatenregionen erfordert. Dies ist ein Problem, da das Modell in der Arbeit mit etwa 2.000 vorgeschlagenen Regionen pro Bild zur Testzeit arbeitet.
Der Python (Caffe) und MatLab Quellcode für R-CNN, wie in der Arbeit beschrieben, wurde im R-CNN GitHub Repository zur Verfügung gestellt.
Fast R-CNN
Angesichts des großen Erfolges von R-CNN schlug Ross Girshick, damals bei Microsoft Research, in einem Papier von 2015 mit dem Titel „Fast R-CNN“ eine Erweiterung vor, um die Geschwindigkeitsprobleme von R-CNN anzugehen.
Das Papier beginnt mit einem Überblick über die Einschränkungen von R-CNN, die wie folgt zusammengefasst werden können:
- Das Training ist eine mehrstufige Pipeline. Es umfasst die Vorbereitung und den Betrieb von drei separaten Modellen.
- Das Training ist räumlich und zeitlich teuer. Das Training eines tiefen CNN auf so vielen Regionsvorschlägen pro Bild ist sehr langsam.
- Die Objekterkennung ist langsam. Vorhersagen mit einem tiefen CNN auf so vielen Regionsvorschlägen zu machen, ist sehr langsam.
Eine frühere Arbeit wurde vorgeschlagen, um die Technik namens Spatial Pyramid Pooling Networks oder SPPnets zu beschleunigen, in der 2014 Veröffentlichung „Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.“ Dies beschleunigte zwar die Extraktion von Merkmalen, verwendete aber im Wesentlichen eine Art Forward-Pass-Caching-Algorithmus.
Fast R-CNN wird als einzelnes Modell anstelle einer Pipeline vorgeschlagen, um Regionen und Klassifizierungen direkt zu erlernen und auszugeben.
Die Architektur des Modells nimmt das Foto eine Reihe von Regionsvorschlägen als Eingabe, die durch ein tiefes neuronales Faltungsnetzwerk geleitet werden. Für die Merkmalsextraktion wird ein vortrainiertes CNN, z. B. ein VGG-16, verwendet. Am Ende des tiefen CNN steht eine benutzerdefinierte Schicht mit der Bezeichnung „Region of Interest Pooling Layer“ oder „RoI Pooling“, die spezifische Merkmale für eine bestimmte Eingaberegion extrahiert.
Die Ausgabe des CNN wird dann von einer vollständig verbundenen Schicht interpretiert, und das Modell verzweigt sich in zwei Ausgaben, eine für die Klassenvorhersage über eine Softmax-Schicht und eine weitere mit einer linearen Ausgabe für die Bounding Box. Dieser Prozess wird dann mehrfach für jede Region von Interesse in einem gegebenen Bild wiederholt.
Die Architektur des Modells ist in der nachstehenden Abbildung zusammengefasst, die dem Papier entnommen wurde.
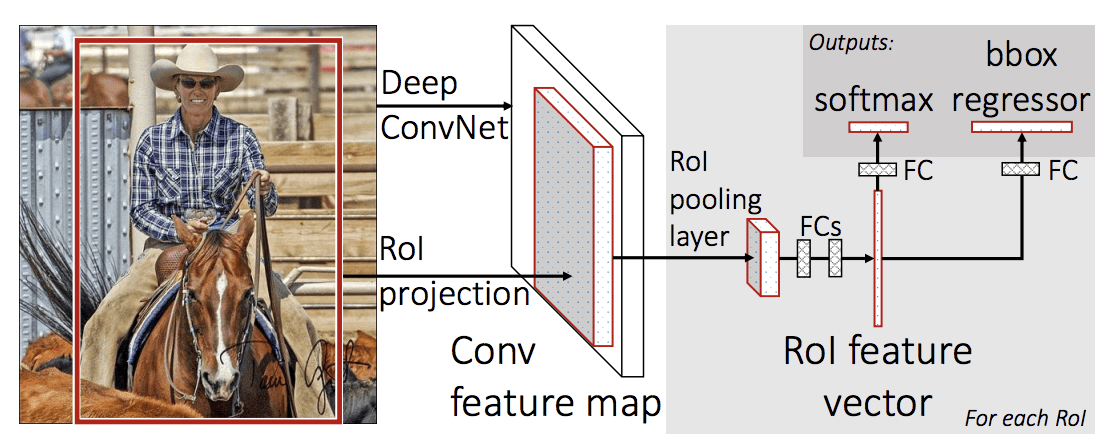
Zusammenfassung der schnellen R-CNN-Modellarchitektur.
Entnommen aus: Fast R-CNN.
Das Modell ist wesentlich schneller zu trainieren und Vorhersagen zu treffen, erfordert aber immer noch einen Satz von Kandidatenregionen, die zusammen mit jedem Eingabebild vorgeschlagen werden.
Der Python und C++ (Caffe) Quellcode für Fast R-CNN, wie in der Arbeit beschrieben, wurde in einem GitHub Repository zur Verfügung gestellt.
Faster R-CNN
Die Modellarchitektur wurde von Shaoqing Ren, et al. bei Microsoft Research in der Arbeit „Faster R-CNN“ aus dem Jahr 2016 sowohl für die Trainings- als auch für die Erkennungsgeschwindigkeit weiter verbessert: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks“
Die Architektur bildete die Grundlage für die Erstplatzierungen bei den Wettbewerben ILSVRC-2015 und MS COCO-2015 zur Objekterkennung und -detektion.
Die Architektur wurde so konzipiert, dass sie als Teil des Trainingsprozesses Regionen vorschlägt und verfeinert, was als Region Proposal Network (RPN) bezeichnet wird. Diese Regionen werden dann zusammen mit einem schnellen R-CNN-Modell in einem einzigen Modellentwurf verwendet. Durch diese Verbesserungen wird sowohl die Anzahl der Regionenvorschläge reduziert als auch der Betrieb des Modells zur Testzeit auf nahezu Echtzeit beschleunigt, so dass die Leistung dem neuesten Stand der Technik entspricht.
… unser Erkennungssystem hat eine Bildwiederholrate von 5 Bildern pro Sekunde (einschließlich aller Schritte) auf einem Grafikprozessor und erreicht gleichzeitig eine Objekterkennungsgenauigkeit auf dem neuesten Stand der Technik bei den Datensätzen PASCAL VOC 2007, 2012 und MS COCO mit nur 300 Vorschlägen pro Bild. In den ILSVRC- und COCO-Wettbewerben 2015 bilden Faster R-CNN und RPN die Grundlage für die Erstplatzierten in mehreren Tracks
– Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
Obwohl es sich um ein einziges, einheitliches Modell handelt, besteht die Architektur aus zwei Modulen:
- Modul 1: Region Proposal Network. Faltungsneuronales Netz zum Vorschlagen von Regionen und der Art des in der Region zu berücksichtigenden Objekts.
- Modul 2: Fast R-CNN. Neuronales Faltungsnetzwerk zur Extraktion von Merkmalen aus den vorgeschlagenen Regionen und zur Ausgabe des Begrenzungsrahmens und der Klassenbezeichnungen.
Beide Module arbeiten mit demselben Ausgang eines tiefen CNN. Das Netzwerk mit den Regionsvorschlägen fungiert als Aufmerksamkeitsmechanismus für das schnelle R-CNN-Netzwerk und informiert das zweite Netzwerk darüber, wo es hinschauen oder aufpassen soll.
Die Architektur des Modells ist in der nachstehenden Abbildung zusammengefasst, die aus der Veröffentlichung stammt.
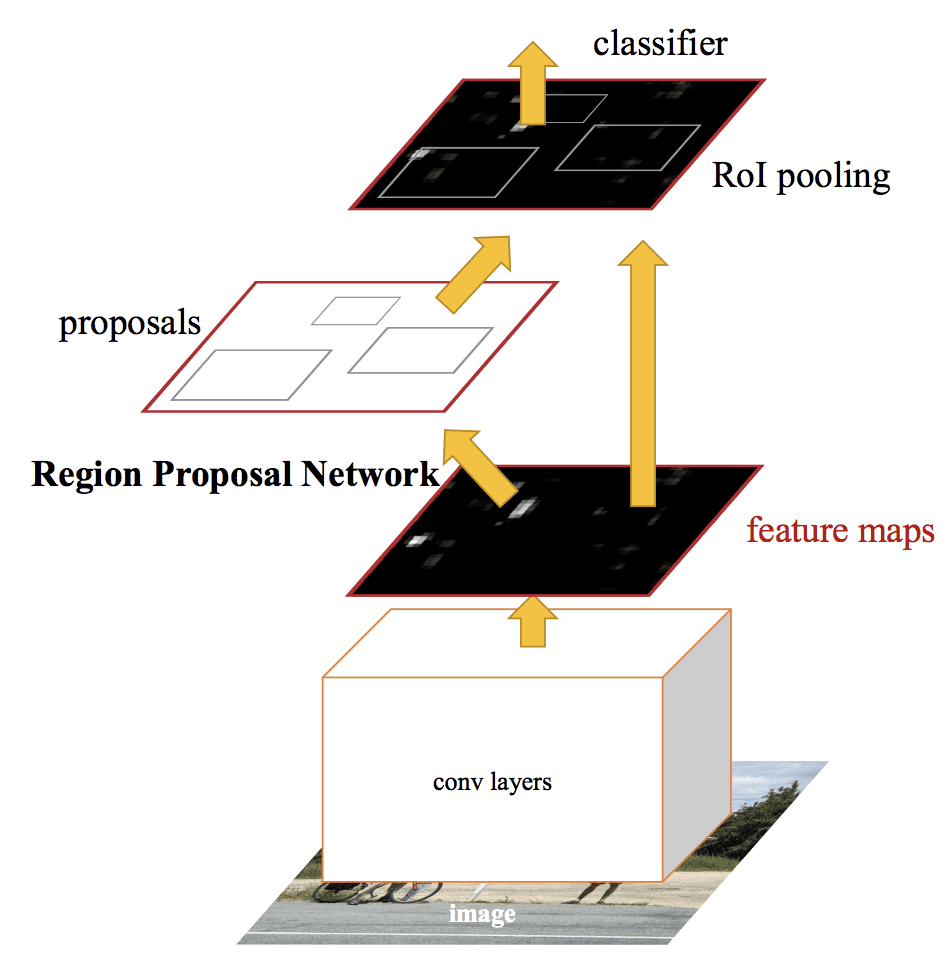
Zusammenfassung der Faster R-CNN Modellarchitektur.Aus: Faster R-CNN: Towards Real-Time Object Detection With Region Proposal Networks.
Das RPN funktioniert, indem es die Ausgabe eines vortrainierten tiefen CNN, wie VGG-16, nimmt und ein kleines Netzwerk über die Merkmalskarte führt und mehrere Regionsvorschläge und eine Klassenvorhersage für jeden ausgibt. Bei den Regionsvorschlägen handelt es sich um Begrenzungsboxen, die auf so genannten Ankerboxen oder vordefinierten Formen basieren, die das Vorschlagen von Regionen beschleunigen und verbessern sollen. Die Klassenvorhersage ist binär und gibt an, ob ein Objekt vorhanden ist oder nicht, die so genannte „Objekthaftigkeit“ der vorgeschlagenen Region.
Es wird ein Verfahren des alternierenden Trainings verwendet, bei dem beide Teilnetze gleichzeitig trainiert werden, wenn auch ineinander verschachtelt. Auf diese Weise können die Parameter im tiefen CNN des Merkmalsdetektors für beide Aufgaben gleichzeitig angepasst werden.
Zum Zeitpunkt der Erstellung dieses Berichts ist diese Faster R-CNN-Architektur die Spitze der Modellfamilie und erzielt bei Objekterkennungsaufgaben nach wie vor Ergebnisse, die nahezu dem Stand der Technik entsprechen. Eine weitere Erweiterung fügt Unterstützung für die Bildsegmentierung hinzu, die im Papier „Mask R-CNN“ von 2017 beschrieben wird.
Der Python und C++ (Caffe)-Quellcode für Fast R-CNN, wie im Papier beschrieben, wurde in einem GitHub-Repository zur Verfügung gestellt.
YOLO-Modellfamilie
Eine weitere populäre Familie von Objekterkennungsmodellen wird als YOLO oder „You Only Look Once“ bezeichnet und wurde von Joseph Redmon, et al.
Die R-CNN-Modelle mögen im Allgemeinen genauer sein, doch die YOLO-Modellfamilie ist schnell, viel schneller als R-CNN, und erreicht eine Objekterkennung in Echtzeit.
YOLO
Das YOLO-Modell wurde erstmals von Joseph Redmon, et al. in dem 2015 veröffentlichten Papier mit dem Titel „You Only Look Once: Unified, Real-Time Object Detection“ beschrieben. Ross Girshick, Entwickler von R-CNN, war ebenfalls Autor und Mitwirkender dieser Arbeit, damals bei Facebook AI Research.
Der Ansatz beinhaltet ein einzelnes neuronales Netzwerk, das von Ende zu Ende trainiert wird und ein Foto als Eingabe nimmt und Bounding Boxes und Klassenbezeichnungen für jede Bounding Box direkt vorhersagt. Die Technik bietet eine geringere Vorhersagegenauigkeit (z. B. mehr Lokalisierungsfehler), arbeitet jedoch mit 45 Bildern pro Sekunde und bis zu 155 Bildern pro Sekunde für eine geschwindigkeitsoptimierte Version des Modells.
Unsere einheitliche Architektur ist extrem schnell. Unser Basismodell YOLO verarbeitet Bilder in Echtzeit mit 45 Bildern pro Sekunde. Eine kleinere Version des Netzwerks, Fast YOLO, verarbeitet erstaunliche 155 Bilder pro Sekunde …
– You Only Look Once: Unified, Real-Time Object Detection, 2015.
Das Modell funktioniert, indem es zunächst das Eingabebild in ein Gitter von Zellen aufteilt, wobei jede Zelle für die Vorhersage einer Bounding Box verantwortlich ist, wenn der Mittelpunkt einer Bounding Box in die Zelle fällt. Jede Gitterzelle sagt einen Begrenzungsrahmen voraus, der die x- und y-Koordinaten, die Breite und Höhe sowie die Konfidenz umfasst. Eine Klassenvorhersage basiert ebenfalls auf jeder Zelle.
Zum Beispiel kann ein Bild in ein 7×7-Gitter unterteilt werden und jede Zelle im Gitter kann 2 Bounding Boxes vorhersagen, was zu 94 vorgeschlagenen Bounding Box Vorhersagen führt. Die Karte der Klassenwahrscheinlichkeiten und die Bounding Boxes mit Konfidenzwerten werden dann zu einem endgültigen Satz von Bounding Boxes und Klassenbezeichnungen kombiniert. Die Abbildung aus dem Papier unten fasst die beiden Ergebnisse des Modells zusammen.
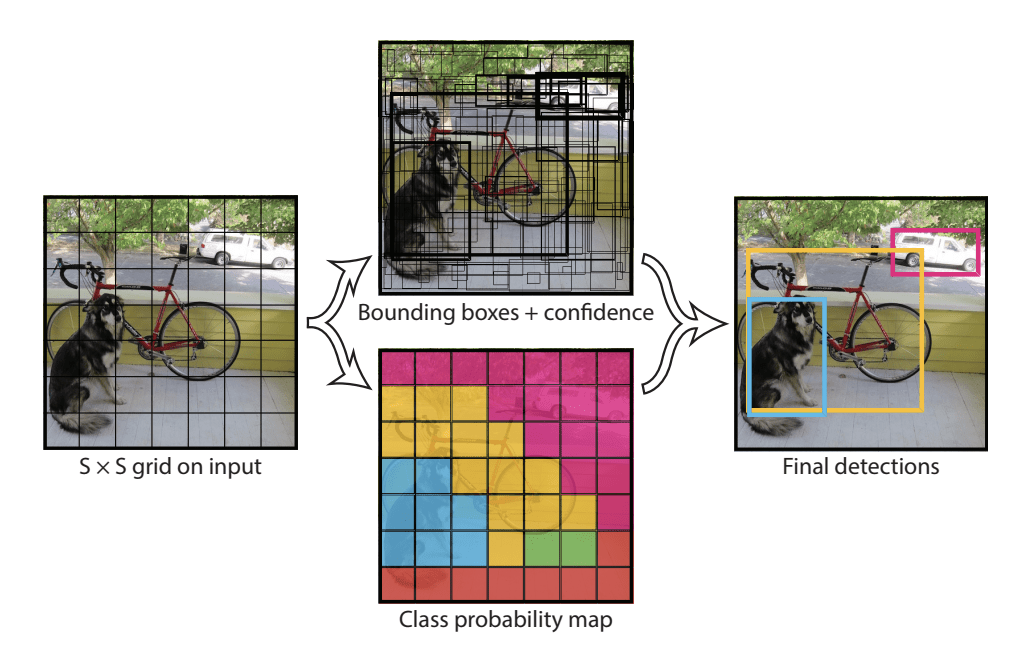
Zusammenfassung der Vorhersagen des YOLO-Modells.Entnommen aus: You Only Look Once: Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) und YOLOv3
Das Modell wurde von Joseph Redmon und Ali Farhadi in dem Bemühen aktualisiert, die Leistung des Modells in ihrem 2016 veröffentlichten Papier mit dem Titel „YOLO9000: Better, Faster, Stronger.
Obwohl diese Variante des Modells als YOLO v2 bezeichnet wird, wird eine Instanz des Modells beschrieben, die parallel auf zwei Objekterkennungsdatensätzen trainiert wurde und in der Lage ist, 9.000 Objektklassen vorherzusagen, weshalb sie den Namen „YOLO9000″ erhielt.“
Eine Reihe von Trainings- und architektonischen Änderungen wurden an dem Modell vorgenommen, wie z.B. die Verwendung von Batch-Normalisierung und hochauflösenden Eingabebildern.
Wie Faster R-CNN verwendet das YOLOv2-Modell Ankerboxen, vordefinierte Bounding-Boxen mit nützlichen Formen und Größen, die während des Trainings angepasst werden. Die Auswahl der Bounding Boxes für das Bild wird durch eine k-means-Analyse des Trainingsdatensatzes vorverarbeitet.
Wichtig ist, dass die vorhergesagte Darstellung der Bounding Boxes geändert wird, damit kleine Änderungen weniger dramatische Auswirkungen auf die Vorhersagen haben, was zu einem stabileren Modell führt. Anstatt Position und Größe direkt vorherzusagen, werden Offsets für das Verschieben und Umgestalten der vordefinierten Ankerboxen relativ zu einer Gitterzelle vorhergesagt und durch eine logistische Funktion gedämpft.
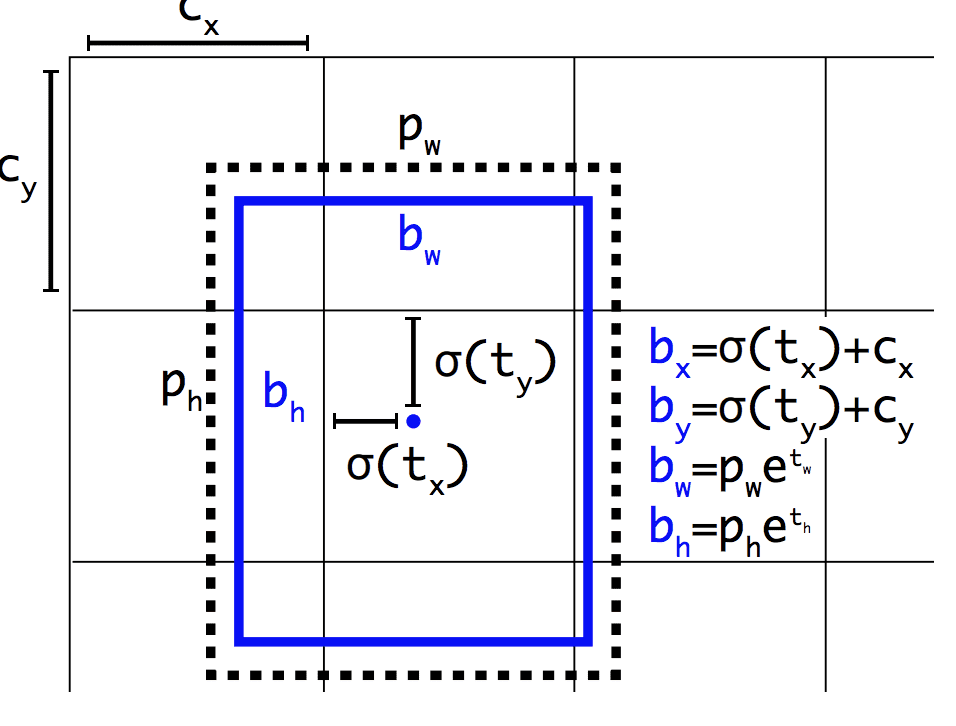
Beispiel für die gewählte Darstellung bei der Vorhersage von Position und Form der Bounding BoxAus: YOLO9000: Better, Faster, Stronger
Weitere Verbesserungen des Modells wurden von Joseph Redmon und Ali Farhadi in ihrem 2018 veröffentlichten Papier mit dem Titel „YOLOv3: An Incremental Improvement“ vorgeschlagen. Die Verbesserungen waren relativ geringfügig, einschließlich eines tieferen Merkmalsdetektornetzwerks und kleinerer Änderungen an der Darstellung.
Further Reading
Dieser Abschnitt bietet weitere Ressourcen zum Thema, wenn Sie tiefer gehen möchten.
Papers
- ImageNet Large Scale Visual Recognition Challenge, 2015.
R-CNN Family Papers
- Rich feature hierarchies for accurate object detection and semantic segmentation, 2013.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, 2014.
- Fast R-CNN, 2015.
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
- Mask R-CNN, 2017.
YOLO Family Papers
- You Only Look Once: Unified, Real-Time Object Detection, 2015.
- YOLO9000: Better, Faster, Stronger, 2016.
- YOLOv3: An Incremental Improvement, 2018.
Code Projects
- R-CNN: Regions with Convolutional Neural Network Features, GitHub.
- Fast R-CNN, GitHub.
- Faster R-CNN Python Code, GitHub.
- YOLO, GitHub.
Resources
- Ross Girshick, Homepage.
- Joseph Redmon, Homepage.
- YOLO: Real-Time Object Detection, Homepage.
Artikel
- A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN, 2017.
- Object Detection for Dummies Part 3: R-CNN Family, 2017.
- Object Detection Part 4: Fast Detection Models, 2018.
Summary
In diesem Beitrag haben Sie eine behutsame Einführung in das Problem der Objekterkennung und die modernsten Deep-Learning-Modelle entdeckt, die dafür entwickelt wurden.
Insbesondere haben Sie gelernt:
- Objekterkennung bezieht sich auf eine Sammlung verwandter Aufgaben zur Identifizierung von Objekten in digitalen Fotos.
- Regionenbasierte neuronale Faltungsnetze (R-CNNs) sind eine Familie von Techniken zur Lösung von Aufgaben der Objektlokalisierung und -erkennung, die auf Modellleistung ausgelegt sind.
- You Only Look Once (YOLO) ist eine zweite Familie von Techniken zur Objekterkennung, die auf Geschwindigkeit und Echtzeiteinsatz ausgelegt ist.
Haben Sie Fragen?
Setzen Sie sich mit Ihren Fragen in den Kommentaren unten auseinander und ich werde mein Bestes tun, um sie zu beantworten.
Entwickeln Sie noch heute Deep Learning-Modelle für die Bildverarbeitung!

Entwickeln Sie Ihre eigenen Bildverarbeitungsmodelle in wenigen Minuten
…mit nur ein paar Zeilen Python-Code
Entdecken Sie wie in meinem neuen Ebook:
Deep Learning for Computer Vision
Es bietet Tutorials zum Selbststudium zu Themen wie:
Klassifizierung, Objekterkennung (yolo und rcnn), Gesichtserkennung (vggface und facenet), Datenaufbereitung und vieles mehr….
Endlich Deep Learning für Ihre Vision-Projekte
Skip the Academics. Just Results.
See What’s Inside