
A “Anomaly Detection with Autoencoders Made Easy” című könyvben említettem, hogy az Autoencoders széles körben alkalmazzák a dimenziócsökkentésben és a képzajcsökkentésben. Azóta sok olvasó kérdezte, hogy foglalkozom-e a képzajcsökkentés témájával az autoencoderek segítségével. Ez a motivációja ennek a bejegyzésnek.
A képi adatok modellezése speciális megközelítést igényel a neurális hálózatok világában. A legismertebb neurális hálózat a képi adatok modellezésére a Convolutional Neural Network (CNN, vagy ConvNet) vagy más néven Convolutional Autoencoder. Ebben a bejegyzésben egy szelíd bevezetéssel kezdem a képadatokhoz, mert nem minden olvasó van a képadatok területén (nyugodtan ugorja át ezt a részt, ha már ismeri). Ezután egy egyszerű szabványos neurális hálózatot írok le a képadatokhoz. Ez lehetőséget ad arra, hogy bemutassam, miért a konvolúciós autókódolók az előnyben részesített módszer a képi adatok kezelésében. Legfőképpen azt fogom bemutatni, hogy a konvolúciós autókódolók hogyan csökkentik a képben lévő zajokat. Ebben a bejegyzésben a Keras modult és az MNIST adatokat használom. A notebook elérhető ezen a linken keresztül. A Keras egy magas szintű neurális hálózatok API, Python nyelven íródott, és képes a TensorFlow tetején futni. Ez a bejegyzés a korábbi “Mi a képfelismerés?” című bejegyzésem kiterjesztése, amelyre bátorítom, hogy tekintse meg.
Úgy gondoltam, hasznos megemlíteni a három nagy adatkategóriát. A három adatkategória a következő: (1) Korrelálatlan adatok (A soros adatokkal ellentétben), (2) Soros adatok (beleértve a szöveg- és hangfolyam-adatokat) és (3) Képadatok. A mélytanulásnak három alapvető változata van az egyes adatkategóriák kezelésére: (1) a standard előrecsatolt neurális hálózat, (2) az RNN/LSTM és (3) a konvolúciós NN (CNN). Azoknak az olvasóknak, akik útmutatókat keresnek az egyes típusokhoz, ajánljuk a “Explaining Deep Learning in a Regression-Friendly Way” című cikket az (1), a “A Technical Guide for RNN/LSTM/GRU on Stock Price Prediction” című aktuális cikket a (2), valamint a “Deep Learning with PyTorch Is Not Torturing”, “What Is Image Recognition?”, “Anomaly Detection with Autoencoders Made Easy” és “Convolutional Autoencoders for Image Noise Reduction” című cikkeket a (3) esetében. A “Dataman Learning Paths – Build Your Skills, Drive Your Career” című összefoglaló cikket könyvjelzőre teheti.”
Understand Image Data
Egy kép “pixelekből” áll, ahogy az (A) ábrán látható. Egy fekete-fehér képen minden egyes pixel egy 0 és 255 közötti számmal van jelölve. A legtöbb kép manapság 24 bites vagy magasabb színt használ. Az RGB színű kép azt jelenti, hogy egy pixel színe a vörös, a zöld és a kék szín kombinációja, mindegyik szín 0-tól 255-ig terjed. Az RGB színrendszer az összes színt a vörös, a zöld és a kék szín kombinációjából állítja össze, ahogy az ezen az RGB színgenerátoron látható. Tehát egy pixel három értékből álló RGB(102, 255, 102) készletet tartalmaz, ami a #66ff66 színre utal.

Egy 800 pixel széles, 600 pixel magas kép 800 x 600 = 480 000 pixel = 0,48 megapixel (“megapixel” 1 millió pixel). Egy 1024×768-as felbontású kép egy 1024 oszlopos és 768 soros rács, amely tehát 1024 × 768 = 0,78 megapixelt tartalmaz.
MNIST
Az MNIST adatbázis (Modified National Institute of Standards and Technology adatbázis) egy nagy, kézzel írt számjegyeket tartalmazó adatbázis, amelyet általában különböző képfeldolgozó rendszerek képzéséhez használnak. A Keras képzési adathalmaza 60 000 rekordot tartalmaz, a tesztadathalmaz pedig 10 000 rekordot. Minden rekord 28 x 28 képpont méretű.
Milyenek? Használjuk a matplotlib és annak imshow() képfüggvényét az első tíz rekord megjelenítéséhez.

A képadatok halmozása a képzéshez
A neurális hálózat keretének a modellképzéshez való illesztése érdekében a 28 x 28 = 784 értéket egy oszlopba halmozhatjuk. Az első rekord halmozott oszlopa így néz ki: (x_train.reshape(1,784) használatával):

Ezután a (B) ábrán látható módon egy szabványos neurális hálózattal képezhetjük a modellt. A 784 érték mindegyike egy-egy csomópont a bemeneti rétegben. De várjunk csak, nem veszítettünk sok információt, amikor egymásra halmoztuk az adatokat? De igen. A képben lévő térbeli és időbeli összefüggéseket elvetettük. Ez nagy információveszteséget jelent. Lássuk, hogyan képesek a konvolúciós autokódolók megtartani a térbeli és időbeli információkat.

Miért alkalmasak a konvolúciós autokódolók a képi adatokhoz?
Az adatok szeletelése és egymásra helyezése során hatalmas információvesztést látunk. Az adatok egymásra halmozása helyett a konvolúciós autókódolók a bemeneti képadatok térbeli információit változatlanul megtartják, és az információt finoman kivonják az úgynevezett konvolúciós rétegben. A (D) ábra azt mutatja, hogy egy sík 2D képből egy vastag négyzetet (Conv1) vonunk ki, majd egy hosszú kocka (Conv2) és egy másik hosszabb kocka (Conv3) lesz belőle. Ennek a folyamatnak az a célja, hogy megőrizze a térbeli összefüggéseket az adatokban. Ez a kódolási folyamat egy automatikus kódolóban. Középen egy teljesen összekapcsolt autoencoder található, amelynek rejtett rétege mindössze 10 neuronból áll. Ezután következik a dekódolási folyamat, amely a kockákat laposra, majd 2D-s lapos képpé lapítja. A kódoló és a dekódoló a (D) ábrán szimmetrikus. Nem kell, hogy szimmetrikusak legyenek, de a legtöbb gyakorlati szakember csak elfogadja ezt a szabályt, amint azt az “Anomaly Detection with Autoencoders made easy” című fejezetben kifejtettük.

Hogyan működik a konvolúciós autókódoló?
A fenti adatkivonat varázslatosnak tűnik. Hogyan működik ez valójában? A következő három réteget foglalja magában: A konvolúciós réteg, a reLu réteg és a pooling réteg.

- A konvolúciós réteg
A konvolúciós lépés sok kis darabot hoz létre, amelyeket feature maps-nek vagy feature-nek nevezünk, mint az (E) ábrán látható zöld, piros vagy tengerészkék négyzeteket. Ezek a négyzetek megőrzik a bemeneti kép pixelei közötti kapcsolatot. Minden egyes jellemzőtérkép pásztázza végig az eredeti képet, mint ami az (F) ábrán látható. Ezt a folyamatot a pontszámok előállítása során szűrésnek nevezzük.
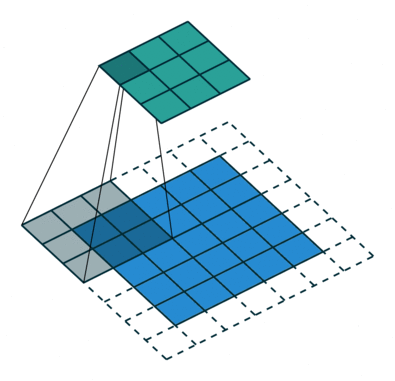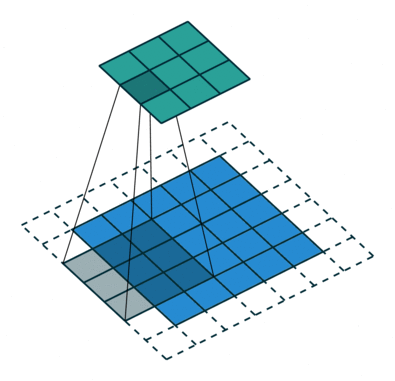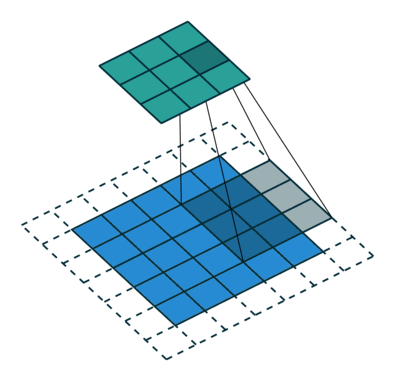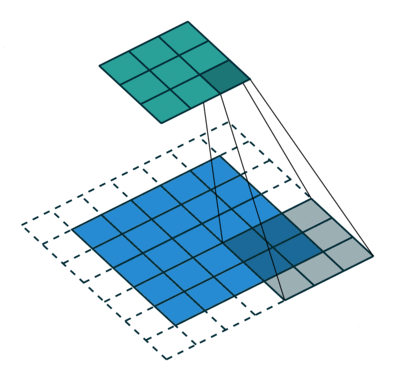
Az eredeti kép átvizsgálása után minden egyes jellemzőből egy magas és alacsony pontszámokat tartalmazó szűrt képet kapunk, amint az a (G) ábrán látható. Ha van tökéletes egyezés, akkor abban a négyzetben magas pontszám van. Ha alacsony egyezés van, vagy nincs egyezés, akkor a pontszám alacsony vagy nulla. Például a piros négyzet négy olyan területet talált az eredeti képen, amely tökéletes egyezést mutat a jellemzővel, így a pontszámok magasak erre a négy területre.

Több szűrő több olyan jellemzőt jelent, amelyet a modell ki tud nyerni. A több jellemző azonban hosszabb képzési időt jelent. Ezért azt tanácsoljuk, hogy a lehető legkevesebb szűrőt használja a jellemzők kinyeréséhez.
1.1 Padding
Hogyan határozzák meg a jellemzők az egyezést? Az egyik hiperparaméter a Padding, amely két lehetőséget kínál: (i) az eredeti kép nullákkal való feltöltése, hogy illeszkedjen a jellemzőhöz, vagy (ii) az eredeti kép nem illeszkedő részének elhagyása és az érvényes rész megtartása.
1.2 Stride
A konvolúciós réteg tartalmaz még egy paramétert: a Stride-ot. Ez a bemeneti mátrix felett eltolt pixelek száma. Ha a stride 1, a szűrők egyszerre 1 képpontot tolnak el. A Keras kódunkban hiperparaméterként fogjuk látni.
2. ReLUs lépés
A Rectified Linear Unit (ReLU) a lépés, amely megegyezik a tipikus neurális hálózatok lépésével. Minden negatív értéket nullára helyesbít, hogy garantálja a matematika helyes viselkedését.
3. Max Pooling Layer
A Pooling a kép méretét zsugorítja. A (H) ábrán egy 2 x 2 ablak, az úgynevezett pool méret, végigpásztázza az egyes szűrt képeket, és a 2 x 2 ablak maximális értékét egy új kép 1 x 1 négyzetéhez rendeli. Ahogy a (H) ábrán látható, az első 2 x 2 ablakban a maximális érték egy magas pontszám (piros színnel ábrázolva), így a magas pontszámot az 1 x 1 négyzethez rendeljük.

A maximális érték vétele mellett más, kevésbé elterjedt pooling módszerek közé tartozik az Average Pooling (az átlagérték vétele) vagy az Sum Pooling (az összeg).

A pooling után egy új, kisebb szűrt képekből álló halom jön létre. Most felosztjuk a kisebb szűrt képeket, és egy listába halmozzuk őket, ahogy a (J) ábrán látható.
Modell Kerasban
A fenti három réteg a konvolúciós neurális hálózat építőkövei. A Keras a következő két funkciót kínálja:
A Convolution Autoencoders-ben sok konvolúciós réteget építhetünk. Az (E) ábrán a kódoló részben három réteg található Conv1, Conv2 és Conv3 felirattal. Tehát ennek megfelelően fogjuk felépíteni.
- Az alábbi kód
input_img = Input(shape=(28,28,1)deklarálja, hogy a bemeneti 2D kép 28 x 28. - Ezután felépíti a három réteget Conv1, Conv2 és Conv3.
- Megjegyezzük, hogy a Conv1 a Conv2-n belül van, a Conv2 pedig a Conv3-on belül.
- A
paddingmegadja, hogy mit tegyünk, ha a szűrő nem illeszkedik jól a bemeneti képhez. Apadding='valid'a kép azon részének elhagyását jelenti, amikor a szűrő nem illeszkedik; apadding='same'nullákkal tölti ki a képet, hogy illeszkedjen a képhez.
Ezután folytatja a dekódolási folyamat hozzáadását. Tehát az alábbi decode rész tartalmazza az összes kódolást és dekódolást.
A Keras api megköveteli a modell és az optimalizációs módszer deklarálását:
-
Model(inputs= input_img,outputs= decoded): A modell tartalmazza a kimenetekdecodedkiszámításához szükséges összes rétegetinput_imgadott bemeneti adatokinput_imgmellett.compile(optimizer='adadelta',loss='binary_crossentropy'): Az optimalizáló úgy végzi az optimalizálást, mint a gradiens decent. A leggyakoribbak a sztochasztikus gradiens decent (SGD), az adaptált gradiens (Adagrad) és az Adadelta, amely az Adagrad kiterjesztése. A részletekért lásd a Keras optimalizáló dokumentációját. A veszteségfüggvények a Keras losses dokumentációban találhatók.
Az alábbiakban a modellt az x_train mint bemenet és mint kimenet segítségével képzem ki. A batch_size a minták száma, a epoch pedig az iterációk száma. Megadom a shuffle=True-et, hogy minden epocha előtt meg kelljen keverni a train adatokat.
Kinyomtathatjuk az első tíz eredeti képet és ugyanennek a tíz képnek a jóslatait.
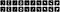
Hogyan építsünk egy képzajcsökkentő konvolúciós autókódolót?
A képzajcsökkentés lényege, hogy egy modellt képezünk ki zajos adatokkal mint bemenetekkel, és a megfelelő tiszta adatokkal mint kimenetekkel. Ez az egyetlen különbség a fenti modellhez képest. Adjunk először zajokat az adatokhoz.
Az első tíz zajos kép a következőképpen néz ki:

Ezután a modellt a zajos adatokkal mint bemenettel, a tiszta adatokkal pedig mint kimenettel képezzük ki.
Végül kiírjuk az első tíz zajos képet, valamint a megfelelő zajmentesített képeket.
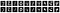
A notebook elérhető ezen a linken.
Létezik olyan előre betanított CNN kód, amit használhatok?
Igen. Ha érdekli a kód megtanulása, a Keras számos előre betanított CNN-t tartalmaz, köztük az Xception, VGG16, VGG19, ResNet50, InceptionV3, InceptionResNetV2, MobileNet, DenseNet, NASNet és MobileNetV2. Érdemes megemlíteni ezt a nagy képadatbázist, az ImageNet-et, amelyhez hozzájárulhat vagy letöltheti kutatási célokra.