Most frissítve: 2021. január 27.
A kezdők számára kihívást jelenthet a különböző kapcsolódó számítógépes látási feladatok megkülönböztetése.
A képosztályozás például egyszerű, de az objektumlokalizáció és az objektumfelismerés közötti különbségek zavaróak lehetnek, különösen akkor, ha mindhárom feladatot ugyanúgy nevezhetjük objektumfelismerésnek is.
A képosztályozás során egy osztálycímkét rendelünk egy képhez, míg az objektumlokalizáció során egy határoló keretet rajzolunk egy vagy több objektum köré a képen. Az objektumfelismerés nagyobb kihívást jelent, és egyesíti ezt a két feladatot, és egy határoló dobozt rajzol a kép minden egyes érdekes objektuma köré, és hozzárendel egy osztálycímkét. Mindezeket a problémákat együttesen objektumfelismerésnek nevezzük.
Ezzel a bejegyzéssel felfedezhet egy szelíd bevezetést az objektumfelismerés problémájába és a legkorszerűbb mélytanulási modellekbe, amelyeket a probléma megoldására terveztek.
A bejegyzés elolvasása után tudni fogja:
- A tárgyfelismerés a digitális fényképeken lévő objektumok azonosítására szolgáló kapcsolódó feladatok gyűjteményére utal.
- A régiókon alapuló konvolúciós neurális hálózatok, vagy R-CNN-ek a tárgylokalizációs és felismerési feladatok megoldására szolgáló technikák egy családja, amelyet a modellteljesítményre terveztek.
- A You Only Look Once, vagy YOLO a tárgyfelismerési technikák egy másik családja, amelyet a sebességre és a valós idejű használatra terveztek.
Kezdje el projektjét az új könyvemmel Deep Learning for Computer Vision, amely lépésről lépésre bemutató útmutatókat és az összes példa Python forráskódfájlját tartalmazza.
Kezdjük el.

A Gentle Introduction to Object Recognition With Deep Learning
Photo by Bart Everson, some rights reserved.
Áttekintés
Ez a bemutató három részre oszlik; ezek a következők:
- Mi a tárgyfelismerés?
- R-CNN modellcsalád
- YOLO modellcsalád
Eredményeket szeretne a mély tanulással a számítógépes látáshoz?
Vegye fel a 7 napos ingyenes e-mailes gyorstalpaló tanfolyamomat most (mintakóddal).
Kattintson a feliratkozáshoz és kapja meg a tanfolyam ingyenes PDF Ebook változatát is.
Töltse le az INGYENES minitanfolyamát
Mi a tárgyfelismerés?
A tárgyfelismerés egy általános kifejezés, amely olyan kapcsolódó számítógépes látási feladatok gyűjteményét írja le, amelyek a digitális fényképeken lévő tárgyak azonosítására vonatkoznak.
A képosztályozás során egy képen lévő tárgy osztályát kell megjósolni. Az objektumlokalizáció egy vagy több objektum helyének azonosítására utal a képen, és a kiterjedésük köré egy körülhatárolt doboz rajzolására. A tárgyfelismerés e két feladatot egyesíti, és egy vagy több tárgyat lokalizál és osztályoz egy képen.
Amikor egy felhasználó vagy szakember “tárgyfelismerésre” hivatkozik, gyakran “tárgyfelismerésre” gondol.
… az objektumfelismerés kifejezést tágan használjuk, hogy magában foglalja mind a képosztályozást (egy algoritmust igénylő feladat, amely meghatározza, hogy milyen objektumosztályok vannak jelen a képen), mind az objektumfelismerést (egy algoritmust igénylő feladat, amely lokalizálja a képen jelen lévő összes objektumot
– ImageNet Large Scale Visual Recognition Challenge, 2015.
Így megkülönböztethetjük ezt a három számítógépes látási feladatot:
- Képosztályozás: Egy képen lévő objektum típusának vagy osztályának előrejelzése.
- Input: Egy kép egyetlen objektummal, például egy fénykép.
- Kimenet:
- Objektum lokalizáció: Objektumok jelenlétének lokalizálása egy képen, és a helyük megjelölése egy határoló doboz segítségével.
- Bemenet:
- Kimenet: Egy vagy több határoló doboz (pl. egy pont, szélesség és magasság által meghatározott).
- Objektumfelismerés: Objektumok jelenlétének keresése egy határoló doboz segítségével és a megtalált objektumok típusai vagy osztályai egy képen.
- Bemenet:
- Kimenet:
A számítógépes látási feladatok e felosztásának egyik további kiterjesztése az objektumszegmentálás, más néven “objektumpéldány-szegmentálás” vagy “szemantikus szegmentálás”, ahol a felismert objektumok példányait a durva határoló doboz helyett az objektum konkrét pixeleinek kiemelésével jelöljük.
Ebből a felosztásból látható, hogy a tárgyfelismerés a számítógépes látás kihívást jelentő feladatainak egy csoportjára utal.
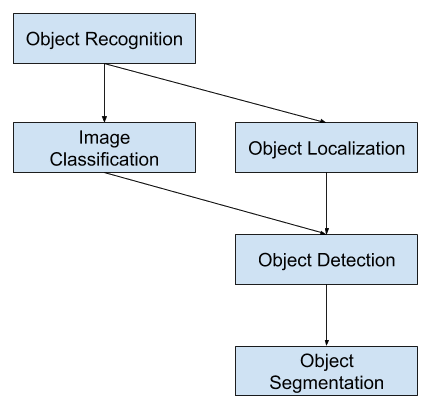
Overview of Object Recognition Computer Vision Tasks
A képfelismerési feladatokkal kapcsolatos legújabb innovációk többsége az ILSVRC feladatokban való részvétel részeként jött létre.
Ez egy évente megrendezésre kerülő akadémiai verseny, amely mindhárom problématípusra külön kihívást tartalmaz, azzal a szándékkal, hogy minden szinten független és különálló fejlesztéseket ösztönözzön, amelyek szélesebb körben is hasznosíthatók. Lásd például a három megfelelő feladattípus alábbi listáját az ILSVRC 2015-ös áttekintő dokumentumából:
- Képosztályozás: Az algoritmusok létrehozzák a képen található tárgykategóriák listáját.
- Egyetlen tárgy lokalizációja: Az algoritmusok létrehozzák a képen jelen lévő tárgykategóriák listáját, valamint az egyes tárgykategóriák egy példányának helyzetét és méretarányát jelző, tengelyhez igazított határoló keretet.
- Objektumdetektálás: Az algoritmusok létrehozzák a képen található tárgykategóriák listáját, valamint egy tengelyhez igazított határoló keretet, amely jelzi az egyes tárgykategóriák minden egyes példányának helyzetét és méretarányát.
Láthatjuk, hogy az “Egyetlen objektum lokalizáció” a tágabban értelmezett “Objektum lokalizáció” egyszerűbb változata, a lokalizációs feladatokat a képen belüli egy típusú objektumokra korlátozza, ami feltételezhetően egyszerűbb feladat.
Az alábbiakban az ILSVRC dokumentumból vett példa összehasonlítja az egyetlen objektum lokalizációt és az objektum detektálást. Figyeljük meg a különbséget az alapigazság elvárásai között az egyes esetekben.
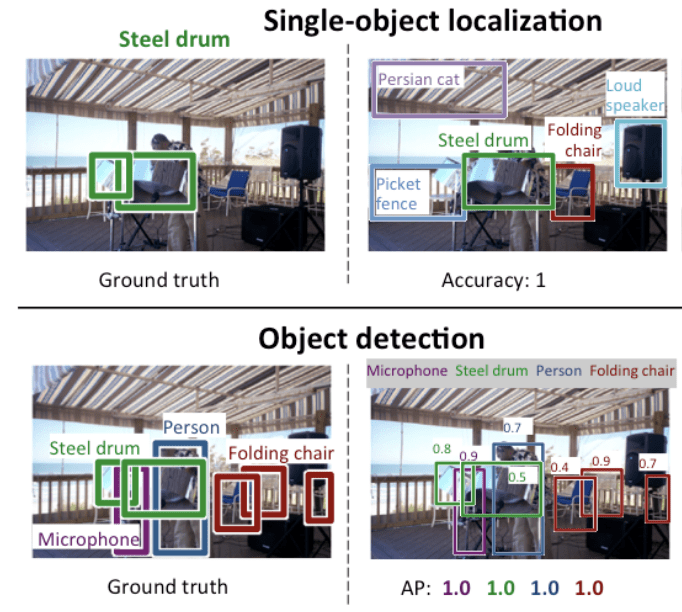
Comparison Between Single Object Localization and Object Detection.Taken From: ImageNet Large Scale Visual Recognition Challenge.
A képosztályozási modell teljesítményét a megjósolt osztálycímkék átlagos osztályozási hibája alapján értékeljük. Az egy objektum lokalizálására szolgáló modell teljesítményét a várt osztály várható és a megjósolt határoló doboza közötti távolság alapján értékeljük. Míg a tárgyfelismerésre szolgáló modell teljesítményét a képen lévő ismert tárgyakhoz legjobban illeszkedő határoló dobozok mindegyikére vonatkozó pontosság és visszahívás alapján értékeljük.
Most, hogy már ismerjük a tárgylokalizáció és -felismerés problémáját, nézzünk meg néhány, a közelmúltban legjobban teljesítő mélytanulási modellt.
R-CNN modellcsalád
Az R-CNN módszercsalád a Ross Girshick, et al. által kifejlesztett R-CNN-re utal, ami a “Regions with CNN Features” vagy “Region-Based Convolutional Neural Network” rövidítése lehet.
Ez magában foglalja az R-CNN, a Fast R-CNN és a Faster-RCNN technikákat, amelyeket objektumlokalizációra és objektumfelismerésre terveztek és mutattak be.
Nézzük meg sorban az egyes technikák legfontosabb jellemzőit.
R-CNN
Az R-CNN-t a 2014-ben megjelent Ross Girshick, et al. (UC Berkeley) “Rich feature hierarchies for accurate object detection and semantic segmentation.”
Ez lehetett a konvolúciós neurális hálózatok egyik első nagy és sikeres alkalmazása a tárgyak lokalizációjának, detektálásának és szegmentálásának problémájára. A megközelítést benchmark adathalmazokon demonstrálták, és azután a VOC-2012 adathalmazon és a 200 osztályos ILSVRC-2013 tárgyfelismerési adathalmazon a legkorszerűbb eredményeket érték el.
A javasolt R-CNN modelljük három modulból áll; ezek a következők:
- 1. modul: Regionális javaslat. Kategóriafüggetlen régiójavaslatok, pl. jelölt határoló dobozok generálása és kinyerése.
- 2. modul: Feature Extractor. Jellemzők kivonása minden egyes jelölt régióból, pl. mély konvolúciós neurális hálózat segítségével.
- 3. modul: Osztályozó. A jellemzők osztályozása az ismert osztályok egyikébe, pl. lineáris SVM osztályozó modell.
A modell architektúráját az alábbi, a cikkből vett kép foglalja össze.
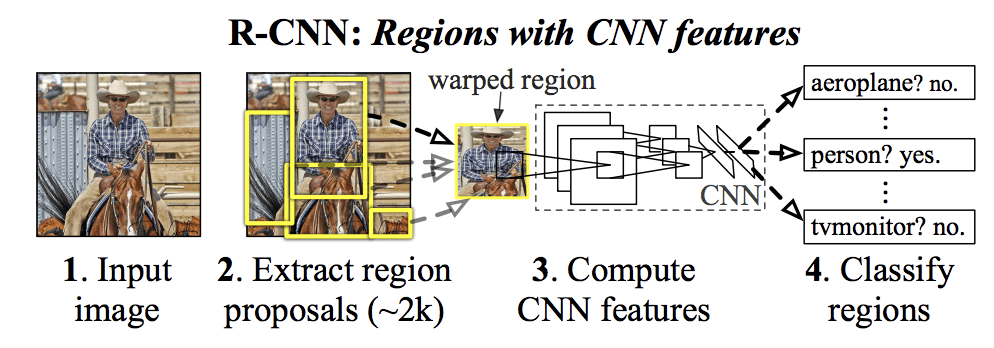
Summary of the R-CNN Model ArchitectureTaken from Rich feature hierarchies for accurate object detection and semantic segmentation.
A képen található potenciális objektumok jelölt régióinak vagy határoló dobozainak javaslására a számítógépes látás technikája, az úgynevezett “szelektív keresés” szolgál, bár a konstrukció rugalmassága lehetővé teszi más régiójavasló algoritmusok használatát is.
A modell által használt jellemző-kivonatoló az AlexNet mély CNN volt, amely megnyerte az ILSVRC-2012 képosztályozási versenyt. A CNN kimenete egy 4096 elemű, a kép tartalmát leíró vektor volt, amelyet egy lineáris SVM-hez tápláltak az osztályozáshoz, konkrétan minden ismert osztályhoz egy SVM-et képeztek ki.
A CNN-ek viszonylag egyszerű és egyszerű alkalmazása a tárgylokalizáció és -felismerés problémájára. A megközelítés hátránya, hogy lassú, mivel a régiójavaslat algoritmus által generált minden egyes jelölt régióra egy CNN-alapú jellemző-kivonási menetet igényel. Ez problémát jelent, mivel a dolgozat leírása szerint a modell tesztidőben képenként körülbelül 2000 javasolt régióval dolgozik.
A dolgozatban ismertetett R-CNNython (Caffe) és MatLab forráskódját a R-CNN GitHub tárolójában tettük elérhetővé.
Gyors R-CNN
Az R-CNN nagy sikerére való tekintettel Ross Girshick, aki akkoriban a Microsoft Researchnél dolgozott, egy 2015-ös, “Fast R-CNN” című tanulmányában egy bővítést javasolt az R-CNN sebességi problémáinak kezelésére.”
A tanulmány az R-CNN korlátainak áttekintésével kezdődik, amelyek a következőképpen foglalhatók össze:
- A képzés egy többlépcsős csővezeték. Három különálló modell elkészítését és működtetését foglalja magában.
- A képzés térben és időben költséges. A mély CNN képenként ennyi régiójavaslaton történő képzése nagyon lassú.
- A tárgyak felismerése lassú. Előrejelzések készítése egy mély CNN segítségével ennyi régiójavaslaton nagyon lassú.
Egy korábbi munka a 2014-es “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition” (Térbeli piramis-összevonó hálózatok vagy SPPnetek) című tanulmányban tett javaslatot a technika felgyorsítására. Ez valóban felgyorsította a jellemzők kinyerését, de lényegében egyfajta forward pass caching algoritmust használt.
A gyors R-CNN-t egyetlen modellként javasolják a régiók és osztályozások közvetlen tanulására és kimenetére szolgáló pipeline helyett.
A modell architektúrája a fényképet egy sor régiójavaslatot fogad el bemenetként, amelyeket egy mély konvolúciós neurális hálózaton vezetnek át. Egy előre betanított CNN-t, például egy VGG-16-ot használnak a jellemzők kinyeréséhez. A mély CNN vége egy egyéni réteg, az úgynevezett Region of Interest Pooling Layer, vagy RoI Pooling, amely egy adott bemeneti jelölt régióra specifikus jellemzőket von ki.
A CNN kimenetét ezután egy teljesen összekapcsolt réteg értelmezi, majd a modell két kimenetre bifurkálódik, az egyik az osztályjósláshoz egy softmax rétegen keresztül, a másik pedig egy lineáris kimenettel a határoló dobozhoz. Ez a folyamat ezután többször megismétlődik egy adott kép minden egyes érdekes régiójára.
A modell architektúráját a cikkből vett alábbi kép foglalja össze.
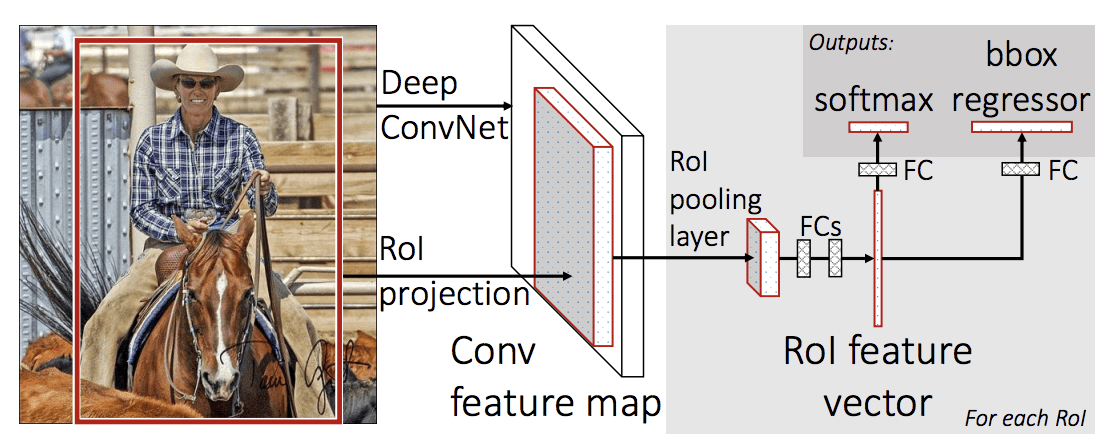
Summary of the Fast R-CNN Model Architecture.
Taken from: Gyors R-CNN.
A modellt lényegesen gyorsabban lehet betanítani és előrejelzéseket készíteni, ugyanakkor továbbra is szükséges, hogy minden egyes bemeneti képpel együtt egy sor jelölt régiót javasoljunk.
A Fast R-CNN-nek a tanulmányban leírtython és C++ (Caffe) forráskódját egy GitHub-tárban tették elérhetővé.
Faster R-CNN
A modell architektúráját Shaoqing Ren, et al. a Microsoft Research 2016-os, Faster R-CNN című tanulmányában továbbfejlesztette mind a képzés, mind a detektálás gyorsasága szempontjából: Towards Real-Time Object Detection with Region Proposal Networks.”
Az architektúra volt az alapja az ILSVRC-2015 és az MS COCO-2015 objektumfelismerési és -detektálási versenyfeladatokon elért első helyezett eredményeknek.
Az architektúrát úgy tervezték, hogy a képzési folyamat részeként régiójavaslatokat javasoljon és finomítson, amelyet régiójavaslat-hálózatnak (Region Proposal Network, RPN) neveznek. Ezeket a régiókat ezután egy gyors R-CNN modellel együtt használják fel egyetlen modelltervezésben. Ezek a fejlesztések egyrészt csökkentik a régiójavaslatok számát, másrészt a modell tesztidőszaki működését közel valós idejűvé gyorsítják, majd a legkorszerűbb teljesítményt nyújtják.
… a felderítő rendszerünk képkockasebessége 5 képkocka/mp (minden lépéssel együtt) GPU-n, miközben a legkorszerűbb tárgyfelismerési pontosságot érte el a PASCAL VOC 2007, 2012 és MS COCO adatkészleteken, képenként mindössze 300 javaslattal. Az ILSVRC és a COCO 2015 versenyeken a Faster R-CNN és az RPN több pályaműben is az 1. helyezett pályaművek alapját képezi
– Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
Bár egyetlen egységes modellről van szó, az architektúra két modulból áll:
- 1. modul: Régiós javaslathálózat. Konvolúciós neurális hálózat a régiók és a régióban figyelembe veendő objektum típusának javaslására.
- 2. modul: Fast R-CNN. Konvolúciós neurális hálózat a javasolt régiók jellemzőinek kinyerésére és a határoló doboz és az osztálycímkék kiadására.
Mindkét modul egy mély CNN azonos kimenetén működik. A régiójavaslat-hálózat a gyors R-CNN hálózat figyelemmechanizmusaként működik, tájékoztatva a második hálózatot arról, hogy hol kell keresnie vagy figyelnie.
A modell architektúráját az alábbi, a cikkből vett kép foglalja össze.
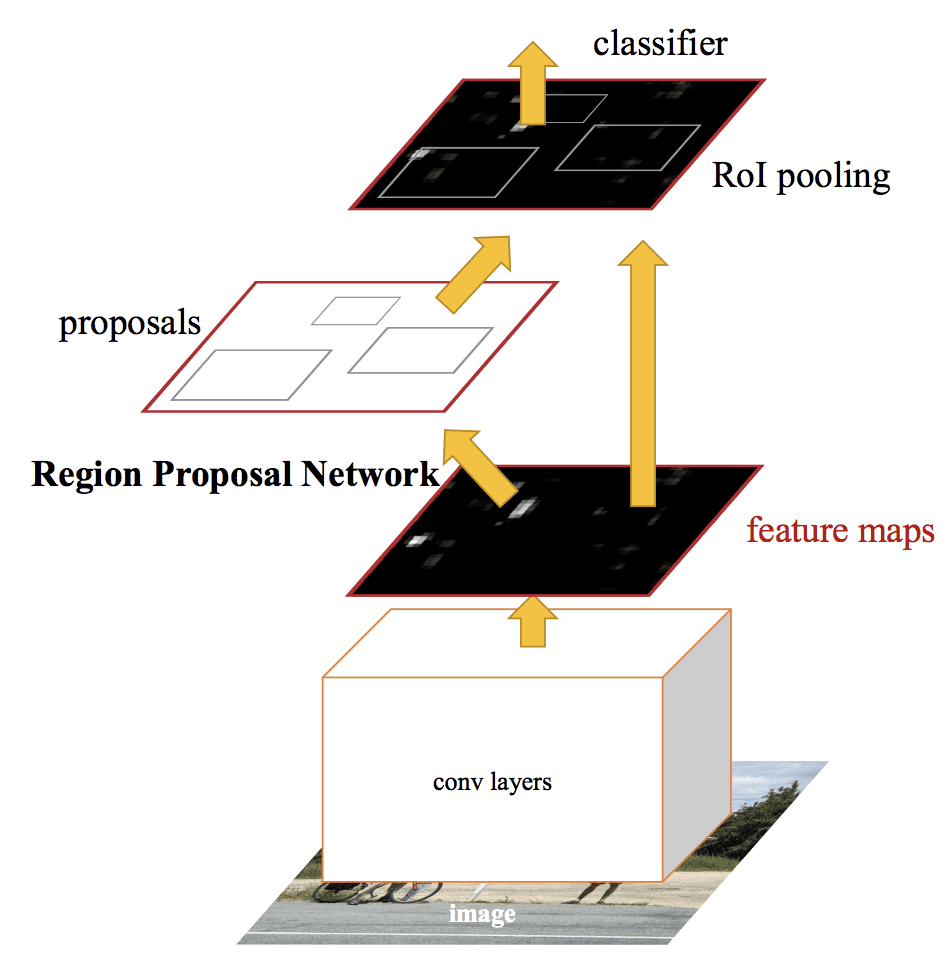
Summary of the Faster R-CNN Model Architecture.Taken from: Faster R-CNN: Towards Real-Time Object Detection With Region Proposal Networks.
Az RPN úgy működik, hogy egy előre betanított mély CNN, például a VGG-16 kimenetét veszi, és egy kis hálózatot vezet át a jellemzőtérképen, majd több régiójavaslatot és mindegyikhez egy osztályjóslatot ad ki. A régiójavaslatok olyan határoló dobozok, amelyek úgynevezett horgonydobozokon vagy előre meghatározott alakzatokon alapulnak, és amelyek célja a régiók javaslatának felgyorsítása és javítása. Az osztály-előrejelzés bináris, jelezve egy objektum jelenlétét, vagy nem jelenlétét, a javasolt régió úgynevezett “objektumosságát”.
A váltakozó képzés eljárását alkalmazzuk, ahol a két alhálózatot egyszerre, bár egymás között váltakozva képezzük. Ez lehetővé teszi, hogy a jellemződetektoros mély CNN paramétereit mindkét feladatra egyszerre szabják vagy finomhangolják.
A cikk írásakor ez a Faster R-CNN architektúra a modellcsalád csúcsa, és továbbra is közel a legkorszerűbb eredményeket ér el a tárgyfelismerési feladatokban. Egy további bővítés a képszegmentálás támogatásával egészül ki, amelyet a 2017-es “Mask R-CNN.”
Python és C++ (Caffe) forráskódja a Fast R-CNN-nek a cikkben leírtak szerint elérhetővé vált egy GitHub tárolóban.
YOLO modellcsalád
A tárgyfelismerő modellek másik népszerű családját együttesen YOLO vagy “You Only Look Once” néven emlegetik, amelyet Joseph Redmon, et al. fejlesztett ki.
Az R-CNN modellek általában pontosabbak lehetnek, mégis a YOLO modellcsalád gyors, sokkal gyorsabb, mint az R-CNN, és valós idejű tárgyfelismerést ér el.
YOLO
A YOLO modellt először Joseph Redmon, et al. írta le 2015-ben a “You Only Look Once: Unified, Real-Time Object Detection” című tanulmányában. Megjegyzendő, hogy Ross Girshick, az R-CNN fejlesztője szintén szerzője és közreműködője volt ennek a munkának, akkor a Facebook AI Research-nél.
A megközelítés egyetlen, végponttól végpontig képzett neurális hálózatot tartalmaz, amely bemenetként egy fényképet vesz, és közvetlenül megjósolja a határoló dobozokat és az egyes határoló dobozok osztálycímkéit. A technika alacsonyabb előrejelzési pontosságot kínál (pl. több lokalizációs hiba), bár 45 képkocka/másodperc sebességgel működik, a modell sebességre optimalizált változata pedig akár 155 képkocka/másodperc sebességgel is.
Egységes architektúránk rendkívül gyors. Az alap YOLO modellünk valós időben 45 képkocka/másodperc sebességgel dolgozza fel a képeket. A hálózat kisebb változata, a Fast YOLO, másodpercenként elképesztő 155 képkockát dolgoz fel …
– You Only Look Once: Unified, Real-Time Object Detection, 2015.
A modell úgy működik, hogy először a bemeneti képet cellákból álló rácsra osztja, ahol minden egyes cella felelős egy határoló doboz előrejelzéséért, ha a határoló doboz középpontja a cellába esik. Minden rácscella egy határoló dobozt jósol meg az x, y koordinátát, valamint a szélességet és a magasságot és a megbízhatóságot bevonva. Minden egyes cellán egy osztályjóslás is alapul.
Egy képet például 7×7-es rácsra lehet osztani, és a rács minden egyes cellája 2 határoló dobozt jósolhat, ami 94 javasolt határoló doboz-előrejelzést eredményez. Az osztályvalószínűségi térképet és a konfidenciákkal rendelkező határoló dobozokat ezután a határoló dobozok és az osztálycímkék végső készletévé kombináljuk. Az alábbi, a cikkből vett kép a modell két kimenetét foglalja össze.
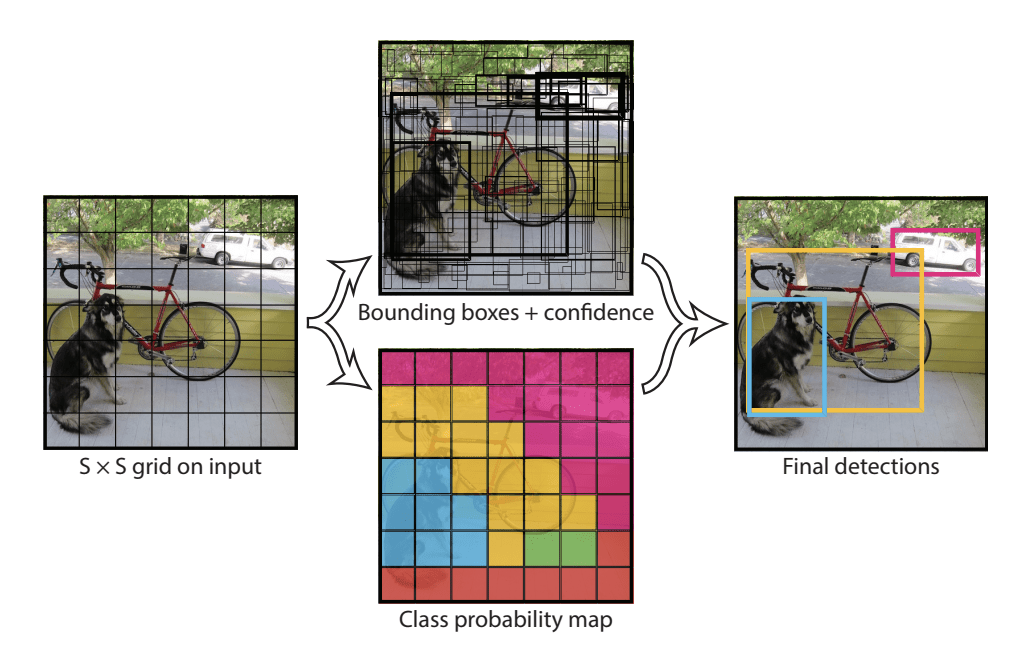
Summary of Predictions made by YOLO Model.Taken from: You Only Look Once: Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) and YOLOv3
A modellt Joseph Redmon és Ali Farhadi a modell teljesítményének további javítása érdekében frissítette a 2016-ban megjelent “YOLO9000: Better, Faster, Stronger.”
Bár a modellnek ezt a változatát YOLO v2 néven említik, a modell egy olyan példányát írják le, amelyet két tárgyfelismerési adathalmazon párhuzamosan képeztek ki, és amely 9000 tárgyosztály előrejelzésére képes, ezért kapta a “YOLO9000″ nevet.”
A modellen számos képzési és architektúrális változtatást hajtottak végre, mint például a kötegelt normalizálás és a nagy felbontású bemeneti képek használata.
A Faster R-CNN-hez hasonlóan a YOLOv2 modell is használ anchor boxokat, előre definiált, hasznos alakú és méretű határoló dobozokat, amelyeket a képzés során testre szabnak. A képhez tartozó határolódobozok kiválasztása előfeldolgozásra kerül a képzési adathalmazon végzett k-means elemzéssel.
Fontos, hogy a határolódobozok prediktált reprezentációja úgy módosul, hogy a kis változások kevésbé drámai hatással legyenek a predikciókra, ami stabilabb modellt eredményez. Ahelyett, hogy a pozíciót és a méretet közvetlenül jósolnánk meg, az előre meghatározott horgonydobozok rácscellához viszonyított mozgatásához és átformálásához az eltolódásokat jósoljuk meg, és ezeket egy logisztikus függvénnyel csillapítjuk.
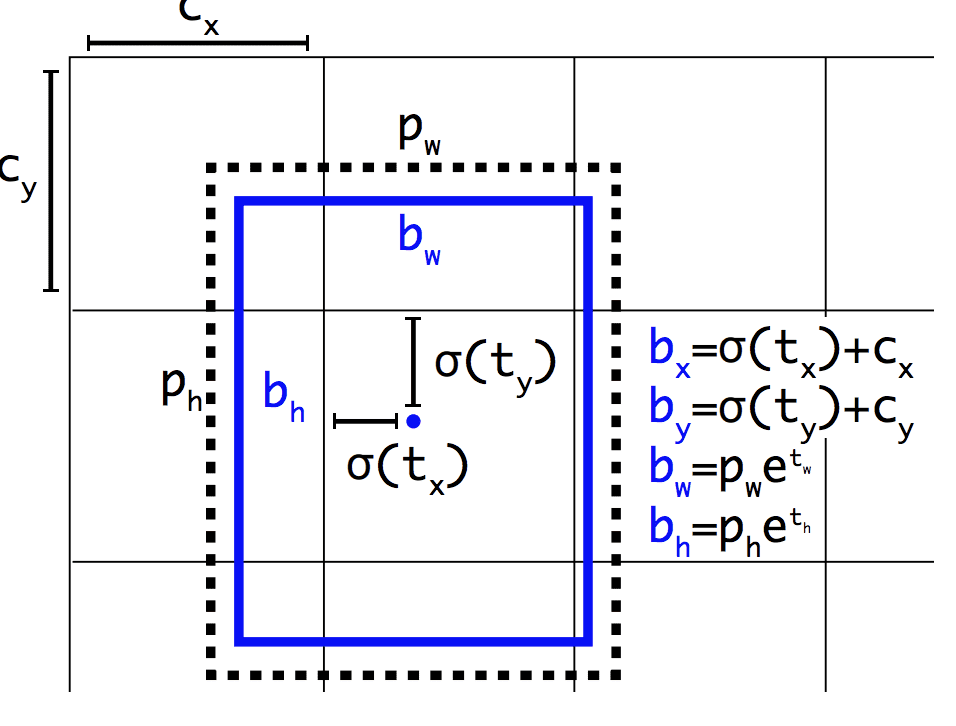
Példa a határoló dobozok pozíciójának és alakjának előrejelzésekor kiválasztott reprezentációraVétel: YOLO9000: Better, Faster, Stronger
A modell további fejlesztését Joseph Redmon és Ali Farhadi javasolta a 2018-as “YOLOv3: An Incremental Improvement” című tanulmányukban. A fejlesztések ésszerűen kisebbek voltak, beleértve egy mélyebb feature detektor hálózatot és kisebb reprezentációs változtatásokat.
Further Reading
Ez a rész további forrásokat tartalmaz a témában, ha mélyebben szeretne elmélyülni.
Papers
- ImageNet Large Scale Visual Recognition Challenge, 2015.
R-CNN Family Papers
- Rich feature hierarchies for accurate object detection and semantic segmentation, 2013.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, 2014.
- Fast R-CNN, 2015.
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
- Mask R-CNN, 2017.
YOLO Family Papers
- You Only Look Once: Unified, Real-Time Object Detection, 2015.
- YOLO9000: Better, Faster, Stronger, 2016.
- YOLOv3: An Incremental Improvement, 2018.
Code Projects
- R-CNN: Regions with Convolutional Neural Network Features, GitHub.
- Fast R-CNN, GitHub.
- Faster R-CNN Python Code, GitHub.
- YOLO, GitHub.
Resources
- Ross Girshick, Homepage.
- Joseph Redmon, Homepage.
- YOLO: Real-Time Object Detection, Homepage.
Articles
- A Short History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN, 2017.
- Object Detection for Dummies Part 3: R-CNN Family, 2017.
- Object Detection Part 4: Fast Detection Models, 2018.
Summary
Ebben a bejegyzésben egy szelíd bevezetést fedezett fel a tárgyfelismerés problémájába és az annak megoldására tervezett legkorszerűbb mélytanulási modellekbe.
Közelebbről megtanulta:
- A tárgyfelismerés a digitális fényképeken lévő tárgyak azonosítására szolgáló, egymással összefüggő feladatok gyűjteményére utal.
- A régióalapú konvolúciós neurális hálózatok, vagy R-CNN-ek a tárgylokalizációs és felismerési feladatok megoldására szolgáló technikák egy családja, amelyet a modellteljesítményre terveztek.
- A You Only Look Once, vagy YOLO a tárgyfelismerési technikák egy másik családja, amelyet a sebességre és a valós idejű használatra terveztek.
Kérdése van?
Tegye fel kérdéseit az alábbi megjegyzésekben, és igyekszem a lehető legjobban válaszolni.
Develop Deep Learning Models for Vision Today!

Develop Your Own Vision Models in Minutes
….mindössze néhány sor python kóddal
Fedezze fel, hogyan az új Ebookomban:
Deep Learning for Computer Vision
Ez önképző tananyagokat tartalmaz olyan témákban, mint:
osztályozás, tárgyfelismerés (yolo és rcnn), arcfelismerés (vggface és facenet), adatelőkészítés és még sok más…
Finally Bringing Deep Learning to your Vision Projects
Skip the Academics. Just Results.
See What’s Inside