A Kolmogorov-Smirnov (KS) statisztika az egyik legfontosabb mérőszám, amelyet a prediktív modellek validálására használnak. Széles körben használják a BFSI-tartományban. Ha Ön a banki projekteken dolgozó kockázati vagy marketingelemző csapat tagja, biztosan hallott már erről a metrikáról.
Mi az a KS-statisztika?
A Kolmogorov-Smirnov rövidítése, amely Andrej Kolmogorov és Nyikolaj Szmirnov után kapta a nevét. Összehasonlítja a két kumulatív eloszlást, és a köztük lévő maximális különbséget adja vissza. Ez egy nem parametrikus teszt, ami azt jelenti, hogy nem kell tesztelnie semmilyen, az adatok eloszlásával kapcsolatos feltételezést. A KS tesztben a nullhipotézis azt állítja, hogy a két kumulatív eloszlás hasonló. A nullhipotézis elutasítása azt jelenti, hogy a kumulatív eloszlások különböznek.
Az adattudományban összehasonlítja az események és a nem események kumulatív eloszlását, és a KS-teszt az, ahol a két eloszlás között maximális különbség van. Egyszerűbben fogalmazva, segít megérteni, hogy a prediktív modellünk mennyire képes megkülönböztetni az eseményeket és a nem eseményeket.
Tegyük fel, hogy egy hajlamossági modellt építünk, amelyben a cél az, hogy azonosítsuk azokat az érdeklődőket, akik valószínűleg megvásárolnak egy adott terméket. Ebben az esetben a függő (cél)változó bináris formában van, amelynek csak két kimenetele van : 0 (nem esemény) vagy 1 (esemény). Az “esemény” azokat jelenti, akik megvásárolták a terméket. A “nem esemény” azokra az emberekre vonatkozik, akik nem vásárolták meg a terméket. A KS statisztika azt méri, hogy a modell képes-e különbséget tenni az érdeklődők és a nem érdeklődők között.
A KS statisztika mérésének két módja
Ez a módszer a leggyakoribb módja a KS statisztika kiszámításának a bináris előrejelző modell validálásához. Lásd az alábbi lépéseket.
- A KS kiszámításához két változóra van szükség. Az egyik a függő változó, amelynek binárisnak kell lennie. A második az előre jelzett valószínűségi pontszám, amely a statisztikai modellből keletkezik.
- Készítsen tizedeket az előre jelzett valószínűségi oszlopok alapján, ami azt jelenti, hogy a valószínűséget 10 részre osztja. Az első tizednek a legmagasabb valószínűségi pontszámot kell tartalmaznia.
- Kalkulálja ki az egyes tizedekben az események és nem események kumulatív %-át, majd számítsa ki a különbséget e két kumulatív eloszlás között.
- KS az, ahol a különbség maximális
- Ha a KS az első 3 tizedben van és a pontszám 40 felett van, akkor jó előrejelző modellnek tekinthető. Ugyanakkor fontos a modell validálása más teljesítménymérők ellenőrzésével is, hogy megerősítsük, hogy a modell nem szenved túlillesztési problémától.
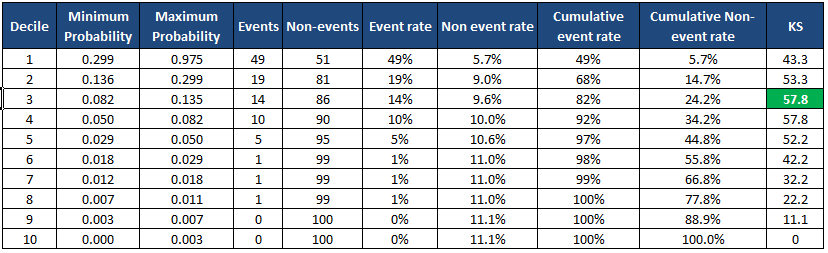
Python : KS statisztikai tizedes módszer
Elkészítettem egy mintaadatot példaként. Az adatkészlet két oszlopot tartalmaz y és p néven.yegy függő változó.paz előre jelzett valószínűségre utal.
import pandas as pdimport numpy as npdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
def ks(data=None,target=None, prob=None): data = 1 - data data = pd.qcut(data, 10) grouped = data.groupby('bucket', as_index = False) kstable = pd.DataFrame() kstable = grouped.min() kstable = grouped.max() kstable = grouped.sum() kstable = grouped.sum() kstable = kstable.sort_values(by="min_prob", ascending=False).reset_index(drop = True) kstable = (kstable.events / data.sum()).apply('{0:.2%}'.format) kstable = (kstable.nonevents / data.sum()).apply('{0:.2%}'.format) kstable=(kstable.events / data.sum()).cumsum() kstable=(kstable.nonevents / data.sum()).cumsum() kstable = np.round(kstable-kstable, 3) * 100 #Formating kstable= kstable.apply('{0:.2%}'.format) kstable= kstable.apply('{0:.2%}'.format) kstable.index = range(1,11) kstable.index.rename('Decile', inplace=True) pd.set_option('display.max_columns', 9) print(kstable) #Display KS from colorama import Fore print(Fore.RED + "KS is " + str(max(kstable))+"%"+ " at decile " + str((kstable.index==max(kstable)]))) return(kstable)
mydf = ks(data=df,target="y", prob="p")
-
dataa pandas adatkeretre utal, amely függő változót és valószínűségi pontszámokat is tartalmaz. -
targeta függő változó oszlopnevére utal -
probaz előre jelzett valószínűség oszlopnevére utal
Táblázatos formában adja vissza az egyes tizedek adatait, és a KS pontszámot is kiírja a táblázat alá. A táblázatot egy új adatkeretben is létrehozza.
min_prob max_prob events nonevents event_rate nonevent_rate \Decile 1 0.298894 0.975404 49 51 49.00% 5.67% 2 0.135598 0.298687 19 81 19.00% 9.00% 3 0.082170 0.135089 14 86 14.00% 9.56% 4 0.050369 0.082003 10 90 10.00% 10.00% 5 0.029415 0.050337 5 95 5.00% 10.56% 6 0.018343 0.029384 1 99 1.00% 11.00% 7 0.011504 0.018291 1 99 1.00% 11.00% 8 0.006976 0.011364 1 99 1.00% 11.00% 9 0.002929 0.006964 0 100 0.00% 11.11% 10 0.000073 0.002918 0 100 0.00% 11.11% cum_eventrate cum_noneventrate KS Decile 1 49.00% 5.67% 43.3 2 68.00% 14.67% 53.3 3 82.00% 24.22% 57.8 4 92.00% 34.22% 57.8 5 97.00% 44.78% 52.2 6 98.00% 55.78% 42.2 7 99.00% 66.78% 32.2 8 100.00% 77.78% 22.2 9 100.00% 88.89% 11.1 10 100.00% 100.00% 0.0 KS is 57.8% at decile 3
Azscipypython könyvtár segítségével kétmintás KS statisztikát tudunk kiszámítani. Két paramétere van – data1 és data2. A data1-ben megadjuk a nem eseményeknek megfelelő összes valószínűségi pontszámot. Az adat2-ben az eseményeknek megfelelő valószínűségi pontszámokat veszi fel.
from scipy.stats import ks_2sampdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")ks_2samp(df.loc, df.loc)
A KS pontszámot 0,6033 és 0,01-nél kisebb p-értéket ad vissza, ami azt jelenti, hogy elvethetjük a nullhipotézist, és arra következtethetünk, hogy az események és a nem események eloszlása különbözik.
OutputKs_2sampResult(statistic=0.6033333333333333, pvalue=1.1227180680661939e-29)
A 2. módszer KS pontszáma kissé eltér az 1. módszertől, mivel a második a sorok szintjén kerül kiszámításra, az elsőt pedig az adatok tíz részre történő átalakítása után számítjuk ki.