Ultimo aggiornamento del 27 gennaio 2021
Può essere impegnativo per i principianti distinguere tra diversi compiti di visione artificiale correlati.
Per esempio, la classificazione delle immagini è semplice, ma le differenze tra la localizzazione e il rilevamento degli oggetti possono confondere, specialmente quando tutti e tre i compiti possono essere ugualmente denominati riconoscimento degli oggetti.
La classificazione delle immagini comporta l’assegnazione di un’etichetta di classe a un’immagine, mentre la localizzazione degli oggetti comporta il disegno di un riquadro di delimitazione intorno a uno o più oggetti in un’immagine. Il rilevamento degli oggetti è più impegnativo e combina questi due compiti e disegna un riquadro di delimitazione intorno ad ogni oggetto di interesse nell’immagine e assegna loro un’etichetta di classe. Insieme, tutti questi problemi sono indicati come riconoscimento degli oggetti.
In questo post, scoprirete una leggera introduzione al problema del riconoscimento degli oggetti e ai modelli di deep learning all’avanguardia progettati per affrontarlo.
Dopo aver letto questo post, saprete:
- Il riconoscimento degli oggetti si riferisce a un insieme di compiti correlati per identificare gli oggetti nelle fotografie digitali.
- Le Reti Neurali Convoluzionarie basate sulle regioni, o R-CNN, sono una famiglia di tecniche per affrontare i compiti di localizzazione e riconoscimento degli oggetti, progettate per le prestazioni dei modelli.
- You Only Look Once, o YOLO, è una seconda famiglia di tecniche per il riconoscimento degli oggetti progettata per la velocità e l’uso in tempo reale.
Inizia il tuo progetto con il mio nuovo libro Deep Learning for Computer Vision, che include tutorial passo dopo passo e i file di codice sorgente Python per tutti gli esempi.
Iniziamo.

A Gentle Introduction to Object Recognition With Deep Learning
Foto di Bart Everson, alcuni diritti riservati.
Panoramica
Questo tutorial è diviso in tre parti; esse sono:
- Che cos’è il riconoscimento degli oggetti?
- Famiglia di modelli R-CNN
- Famiglia di modelli YOLO
Vuoi risultati con il Deep Learning per la visione artificiale?
Prendi subito il mio corso crash gratuito di 7 giorni via email (con codice di esempio).
Clicca per iscriverti e ottenere anche una versione gratuita del corso in PDF Ebook.
Scarica il tuo mini-corso gratuito
Che cos’è il riconoscimento degli oggetti?
Riconoscimento di oggetti è un termine generale per descrivere un insieme di compiti di computer vision correlati che coinvolgono l’identificazione di oggetti in fotografie digitali.
La classificazione di immagini comporta la previsione della classe di un oggetto in un’immagine. La localizzazione dell’oggetto si riferisce all’identificazione della posizione di uno o più oggetti in un’immagine e al disegno di una scatola intorno alla loro estensione. Il rilevamento degli oggetti combina questi due compiti e localizza e classifica uno o più oggetti in un’immagine.
Quando un utente o un professionista si riferisce al “riconoscimento degli oggetti”, spesso intende “rilevamento degli oggetti”.
… useremo il termine riconoscimento di oggetti in modo ampio per comprendere sia la classificazione delle immagini (un compito che richiede un algoritmo per determinare quali classi di oggetti sono presenti nell’immagine) sia il rilevamento di oggetti (un compito che richiede un algoritmo per localizzare tutti gli oggetti presenti nell’immagine
– ImageNet Large Scale Visual Recognition Challenge, 2015.
Come tali, possiamo distinguere tra questi tre compiti di computer vision:
- Classificazione delle immagini: Prevedere il tipo o la classe di un oggetto in un’immagine.
- Input: Un’immagine con un singolo oggetto, come una fotografia.
- Output: Un’etichetta di classe (ad esempio uno o più interi che sono mappati alle etichette di classe).
- Localizzazione di oggetti: Localizzare la presenza di oggetti in un’immagine e indicare la loro posizione con un bounding box.
- Input: Un’immagine con uno o più oggetti, come una fotografia.
- Output: Uno o più riquadri di delimitazione (ad esempio definiti da un punto, larghezza e altezza).
- Rilevamento degli oggetti: Individua la presenza di oggetti con un bounding box e i tipi o le classi degli oggetti individuati in un’immagine.
- Input: Un’immagine con uno o più oggetti, come una fotografia.
- Output: Uno o più riquadri di delimitazione (ad esempio definiti da un punto, larghezza e altezza), e un’etichetta di classe per ogni riquadro di delimitazione.
Un’ulteriore estensione a questa suddivisione dei compiti di computer vision è la segmentazione degli oggetti, chiamata anche “segmentazione di istanze di oggetti” o “segmentazione semantica”, dove le istanze degli oggetti riconosciuti sono indicate evidenziando i pixel specifici dell’oggetto invece di un grossolano riquadro di delimitazione.
Da questa suddivisione, possiamo vedere che il riconoscimento degli oggetti si riferisce a una serie di impegnativi compiti di computer vision.
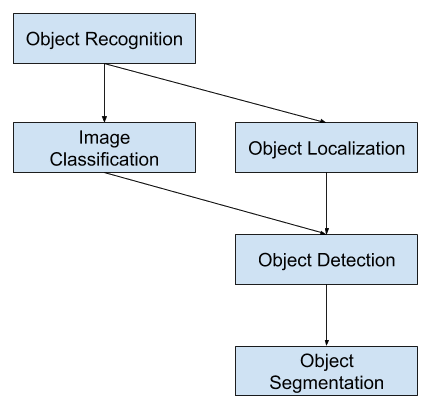
Panoramica dei compiti di visione artificiale di riconoscimento degli oggetti
La maggior parte delle recenti innovazioni nei problemi di riconoscimento delle immagini sono venute come parte della partecipazione ai compiti ILSVRC.
Si tratta di una competizione accademica annuale con una sfida separata per ciascuno di questi tre tipi di problemi, con l’intento di promuovere miglioramenti indipendenti e separati ad ogni livello che possono essere sfruttati più ampiamente. Per esempio, vedi l’elenco dei tre tipi di compito corrispondenti qui sotto, tratto dal documento di revisione ILSVRC del 2015:
- Classificazione delle immagini: Gli algoritmi producono una lista di categorie di oggetti presenti nell’immagine.
- Localizzazione di un singolo oggetto: Gli algoritmi producono una lista di categorie di oggetti presenti nell’immagine, insieme a un riquadro di delimitazione allineato all’asse che indica la posizione e la scala di un’istanza di ogni categoria di oggetti.
- Rilevamento di oggetti: Gli algoritmi producono un elenco di categorie di oggetti presenti nell’immagine insieme a un riquadro di delimitazione allineato sull’asse che indica la posizione e la scala di ogni istanza di ciascuna categoria di oggetti.
Possiamo vedere che la “localizzazione di un singolo oggetto” è una versione più semplice della più ampia “localizzazione di un oggetto”, che limita i compiti di localizzazione agli oggetti di un solo tipo all’interno di un’immagine, che possiamo supporre sia un compito più facile.
Di seguito un esempio che confronta la localizzazione di un singolo oggetto e il rilevamento di un oggetto, tratto dal documento ILSVRC. Si noti la differenza nelle aspettative di verità a terra in ogni caso.
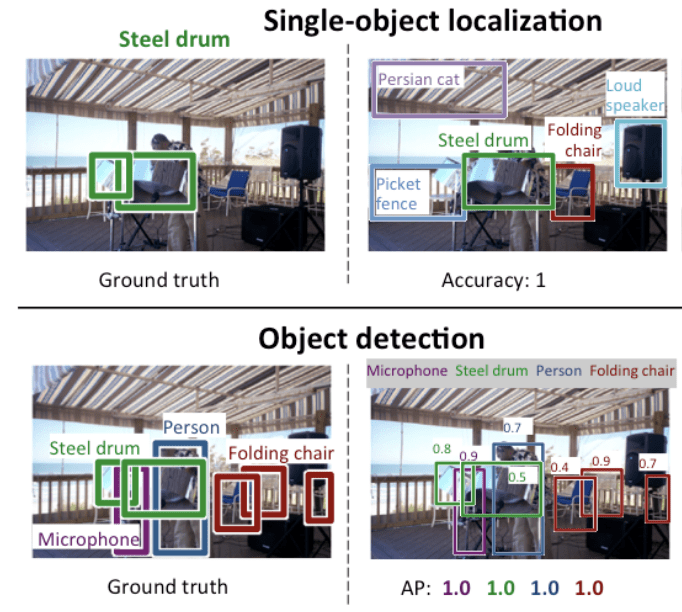
Confronto tra localizzazione di un singolo oggetto e rilevamento di un oggetto.Tratto da: ImageNet Large Scale Visual Recognition Challenge.
Le prestazioni di un modello per la classificazione delle immagini sono valutate utilizzando l’errore medio di classificazione tra le etichette di classe previste. La performance di un modello per la localizzazione di un singolo oggetto è valutata usando la distanza tra il bounding box previsto e quello previsto per la classe prevista. Mentre le prestazioni di un modello per il riconoscimento degli oggetti sono valutate utilizzando la precisione e il richiamo su ciascuno dei migliori riquadri di delimitazione corrispondenti agli oggetti noti nell’immagine.
Ora che abbiamo familiarità con il problema della localizzazione e del rilevamento degli oggetti, diamo un’occhiata ad alcuni recenti modelli di deep learning con le migliori prestazioni.
Famiglia di modelli R-CNN
La famiglia di metodi R-CNN si riferisce al R-CNN, che può stare per “Regions with CNN Features” o “Region-Based Convolutional Neural Network”, sviluppato da Ross Girshick, et al.
Questa comprende le tecniche R-CNN, Fast R-CNN, e Faster-RCNN progettate e dimostrate per la localizzazione e il riconoscimento di oggetti.
Diamo uno sguardo più da vicino ai punti salienti di ciascuna di queste tecniche a turno.
R-CNN
La R-CNN è stata descritta nel documento del 2014 di Ross Girshick, et al. della UC Berkeley intitolato “Rich feature hierarchies for accurate object detection and semantic segmentation.”
Può essere stata una delle prime grandi e riuscite applicazioni di reti neurali convoluzionali al problema della localizzazione, rilevamento e segmentazione degli oggetti. L’approccio è stato dimostrato su set di dati di riferimento, raggiungendo poi risultati allo stato dell’arte sul set di dati VOC-2012 e sul set di dati ILSVRC-2013 per il rilevamento di oggetti di 200 classi.
Il modello R-CNN proposto è composto da tre moduli, che sono:
- Modulo 1: Proposta di regione. Genera ed estrae le proposte di regioni indipendenti dalla categoria, per esempio i box di delimitazione candidati.
- Modulo 2: Estrattore di caratteristiche. Estrarre le caratteristiche da ogni regione candidata, per esempio usando una rete neurale convoluzionale profonda.
- Modulo 3: Classificatore. Classificare le caratteristiche come una delle classi conosciute, per esempio modello classificatore SVM lineare.
L’architettura del modello è riassunta nell’immagine qui sotto, presa dal documento.
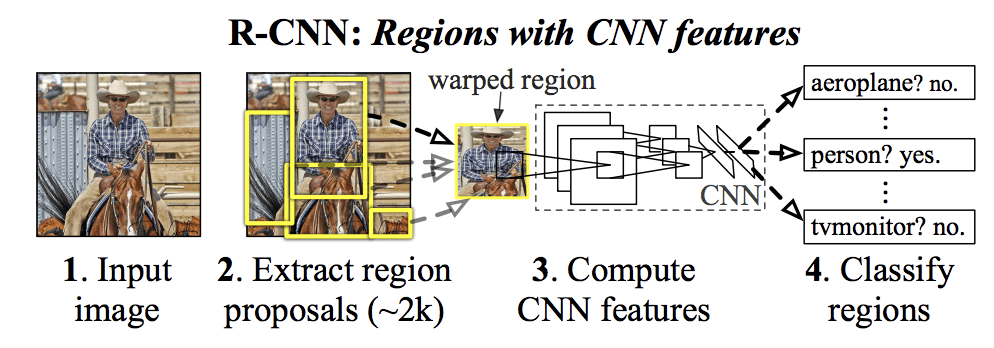
Sommario dell’architettura del modello R-CNNTratto da Ricche gerarchie di caratteristiche per un’accurata rilevazione di oggetti e segmentazione semantica.
Una tecnica di computer vision è usata per proporre regioni candidate o scatole di delimitazione di potenziali oggetti nell’immagine chiamata “ricerca selettiva”, anche se la flessibilità del design permette di usare altri algoritmi di proposta di regioni.
L’estrattore di caratteristiche usato dal modello era la CNN profonda AlexNet che ha vinto il concorso di classificazione di immagini ILSVRC-2012. L’output della CNN era un vettore di 4.096 elementi che descrive il contenuto dell’immagine che viene alimentato a un SVM lineare per la classificazione, in particolare un SVM viene addestrato per ogni classe nota.
È un’applicazione relativamente semplice e diretta delle CNN al problema della localizzazione e del riconoscimento degli oggetti. Uno svantaggio dell’approccio è che è lento, richiedendo un passaggio di estrazione delle caratteristiche basato su CNN su ciascuna delle regioni candidate generate dall’algoritmo di proposta della regione. Questo è un problema poiché l’articolo descrive il modello che opera su circa 2.000 regioni proposte per immagine al momento del test.
Il codice sorgente Python (Caffe) e MatLab per R-CNN come descritto nell’articolo è stato reso disponibile nel repository GitHub di R-CNN.
Fast R-CNN
Dato il grande successo di R-CNN, Ross Girshick, allora alla Microsoft Research, ha proposto un’estensione per affrontare i problemi di velocità di R-CNN in un documento del 2015 intitolato “R-CNN veloce.”
Il documento si apre con una rassegna dei limiti di R-CNN, che possono essere riassunti come segue:
- L’allenamento è una pipeline multistadio. Implica la preparazione e il funzionamento di tre modelli separati.
- L’addestramento è costoso nello spazio e nel tempo. Addestrare una CNN profonda su così tante proposte di regioni per immagine è molto lento.
- Il rilevamento degli oggetti è lento. Fare previsioni usando una CNN profonda su così tante proposte di regioni è molto lento.
Un lavoro precedente è stato proposto per accelerare la tecnica chiamata reti di pooling della piramide spaziale, o SPPnets, nel documento del 2014 “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”. Questo ha accelerato l’estrazione delle caratteristiche, ma essenzialmente ha utilizzato un tipo di algoritmo di caching forward pass.
Fast R-CNN è proposto come un unico modello invece di una pipeline per imparare e produrre direttamente regioni e classificazioni.
L’architettura del modello prende la fotografia una serie di proposte di regioni come input che vengono passate attraverso una rete neurale convoluzionale profonda. Una CNN pre-addestrata, come una VGG-16, è usata per l’estrazione delle caratteristiche. La fine della CNN profonda è uno strato personalizzato chiamato Region of Interest Pooling Layer, o RoI Pooling, che estrae le caratteristiche specifiche per una data regione candidata in ingresso.
L’uscita della CNN viene quindi interpretata da uno strato completamente connesso, poi il modello si biforca in due uscite, una per la previsione della classe tramite uno strato softmax, e un’altra con un’uscita lineare per il bounding box. Questo processo viene poi ripetuto più volte per ogni regione di interesse in una data immagine.
L’architettura del modello è riassunta nell’immagine qui sotto, presa dal documento.
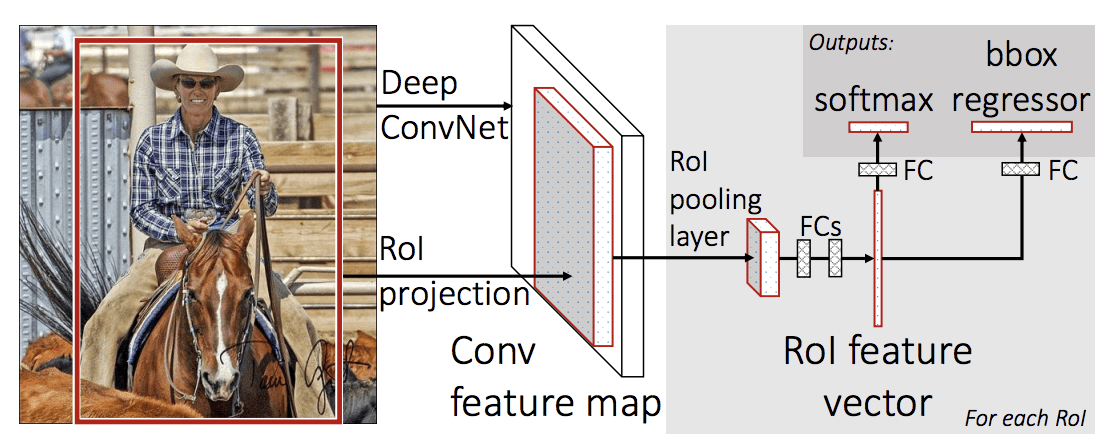
Sommario dell’architettura del modello R-CNN veloce.
Tratto da: Fast R-CNN.
Il modello è significativamente più veloce da addestrare e fare previsioni, ma richiede ancora un set di regioni candidate da proporre insieme ad ogni immagine di input.
Il codice sorgente Python e C++ (Caffe) per Fast R-CNN come descritto nel documento è stato reso disponibile in un repository GitHub.
Faster R-CNN
L’architettura del modello è stata ulteriormente migliorata sia per la velocità di addestramento che di rilevamento da Shaoqing Ren, et al. presso Microsoft Research nel documento del 2016 intitolato “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.”
L’architettura è stata la base per i risultati al primo posto ottenuti in entrambi i compiti del concorso ILSVRC-2015 e MS COCO-2015 per il riconoscimento e il rilevamento di oggetti.
L’architettura è stata progettata sia per proporre e perfezionare proposte di regioni come parte del processo di formazione, indicato come una rete di proposte di regioni, o RPN. Queste regioni sono poi utilizzate di concerto con un modello R-CNN veloce in un unico modello. Questi miglioramenti riducono il numero di proposte di regioni e accelerano il funzionamento del modello in tempo reale con prestazioni allo stato dell’arte.
… il nostro sistema di rilevamento ha un frame rate di 5 fps (comprese tutte le fasi) su una GPU, pur raggiungendo una precisione di rilevamento degli oggetti allo stato dell’arte sui dataset PASCAL VOC 2007, 2012, e MS COCO con solo 300 proposte per immagine. Nelle competizioni ILSVRC e COCO 2015, Faster R-CNN e RPN sono le basi delle proposte vincitrici del 1° posto in diverse tracce
– Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
Anche se è un unico modello unificato, l’architettura è composta da due moduli:
- Modulo 1: Rete di proposta di regioni. Rete neurale convoluzionale per proporre le regioni e il tipo di oggetto da considerare nella regione.
- Modulo 2: Fast R-CNN. Rete neurale convoluzionale per estrarre le caratteristiche dalle regioni proposte e produrre il bounding box e le etichette di classe.
Entrambi i moduli operano sullo stesso output di una CNN profonda. La rete di proposta delle regioni agisce come un meccanismo di attenzione per la rete Fast R-CNN, informando la seconda rete su dove guardare o prestare attenzione.
L’architettura del modello è riassunta nell’immagine qui sotto, tratta dal documento.
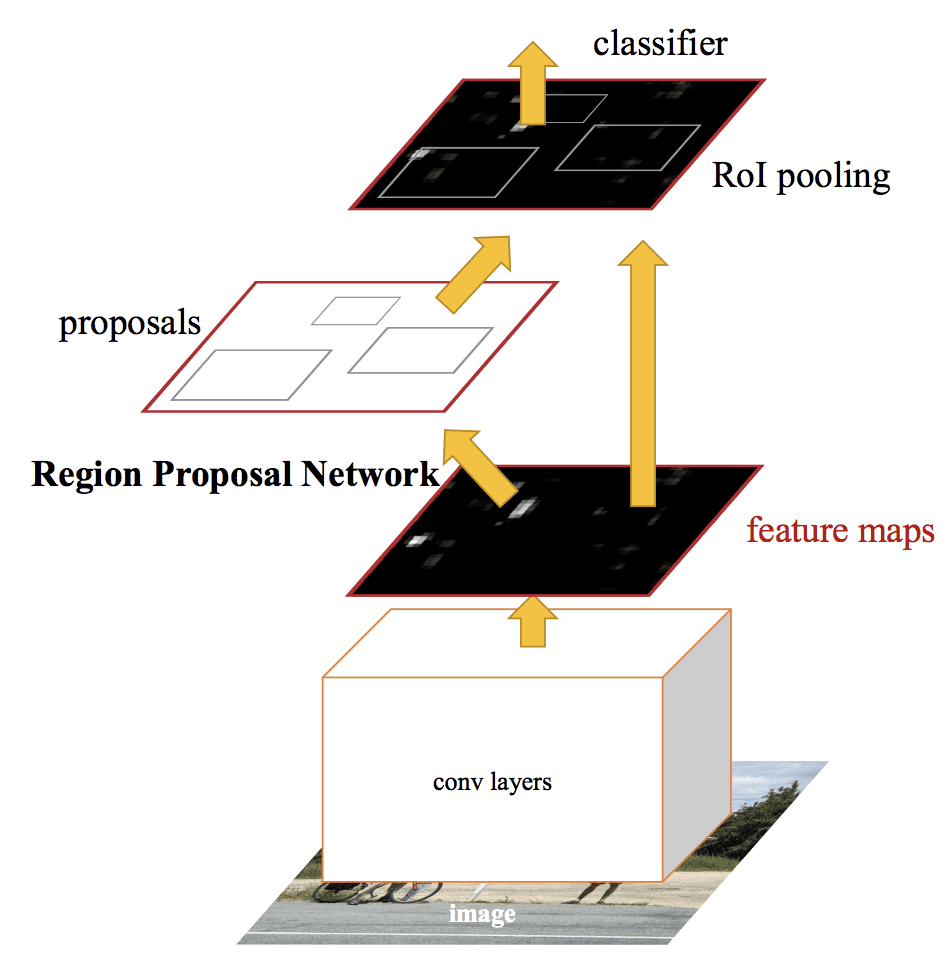
Sommario dell’architettura del modello R-CNN più veloce.Tratto da: Faster R-CNN: Towards Real-Time Object Detection With Region Proposal Networks.
La RPN funziona prendendo l’output di una CNN profonda pre-addestrata, come VGG-16, e passando una piccola rete sulla mappa delle caratteristiche e producendo più proposte di regioni e una previsione di classe per ciascuna. Le proposte di regione sono scatole di delimitazione, basate sulle cosiddette anchor box o forme predefinite progettate per accelerare e migliorare la proposta delle regioni. La predizione di classe è binaria, indicando la presenza o meno di un oggetto, la cosiddetta “objectness” della regione proposta.
Si usa una procedura di formazione alternata in cui entrambe le sottoreti sono addestrate allo stesso tempo, sebbene interleaved. Questo permette ai parametri del rilevatore di caratteristiche CNN profondo di essere adattati o messi a punto per entrambi i compiti allo stesso tempo.
Al momento della scrittura, questa architettura Faster R-CNN è l’apice della famiglia di modelli e continua a ottenere risultati quasi all’avanguardia nei compiti di riconoscimento degli oggetti. Un’ulteriore estensione aggiunge il supporto per la segmentazione delle immagini, descritta nel documento del 2017 “Mask R-CNNN.”
Il codice sorgente Python e C++ (Caffe) per Fast R-CNN come descritto nel documento è stato reso disponibile in un repository GitHub.
Famiglia di modelli YOLO
Un’altra famiglia popolare di modelli di riconoscimento degli oggetti è indicata collettivamente come YOLO o “You Only Look Once,” sviluppata da Joseph Redmon, et al.
I modelli R-CNN possono essere generalmente più accurati, tuttavia la famiglia di modelli YOLO è veloce, molto più veloce di R-CNN, raggiungendo il rilevamento degli oggetti in tempo reale.
YOLO
Il modello YOLO è stato descritto per la prima volta da Joseph Redmon, et al. nel documento del 2015 intitolato “You Only Look Once: Unified, Real-Time Object Detection.” Si noti che Ross Girshick, sviluppatore di R-CNN, era anche un autore e collaboratore di questo lavoro, allora presso Facebook AI Research.
L’approccio comporta una singola rete neurale addestrata da un capo all’altro che prende una fotografia come input e predice direttamente le caselle di delimitazione e le etichette di classe per ogni casella di delimitazione. La tecnica offre un’accuratezza predittiva inferiore (ad esempio, più errori di localizzazione), anche se opera a 45 fotogrammi al secondo e fino a 155 fotogrammi al secondo per una versione ottimizzata del modello.
La nostra architettura unificata è estremamente veloce. Il nostro modello base YOLO elabora le immagini in tempo reale a 45 fotogrammi al secondo. Una versione più piccola della rete, Fast YOLO, elabora un sorprendente 155 fotogrammi al secondo …
– You Only Look Once: Unified, Real-Time Object Detection, 2015.
Il modello funziona dividendo prima l’immagine di input in una griglia di celle, dove ogni cella è responsabile della previsione di un box di delimitazione se il centro di un box di delimitazione cade all’interno della cella. Ogni cella della griglia predice un riquadro di delimitazione che coinvolge la coordinata x, y, la larghezza e l’altezza e la confidenza. Una predizione di classe è anche basata su ogni cella.
Per esempio, un’immagine può essere divisa in una griglia 7×7 e ogni cella nella griglia può predire 2 box di delimitazione, risultando in 94 previsioni di box di delimitazione proposte. La mappa delle probabilità di classe e i riquadri di delimitazione con le confidenze sono poi combinati in un set finale di riquadri di delimitazione e di etichette di classe. L’immagine tratta dall’articolo qui sotto riassume i due output del modello.
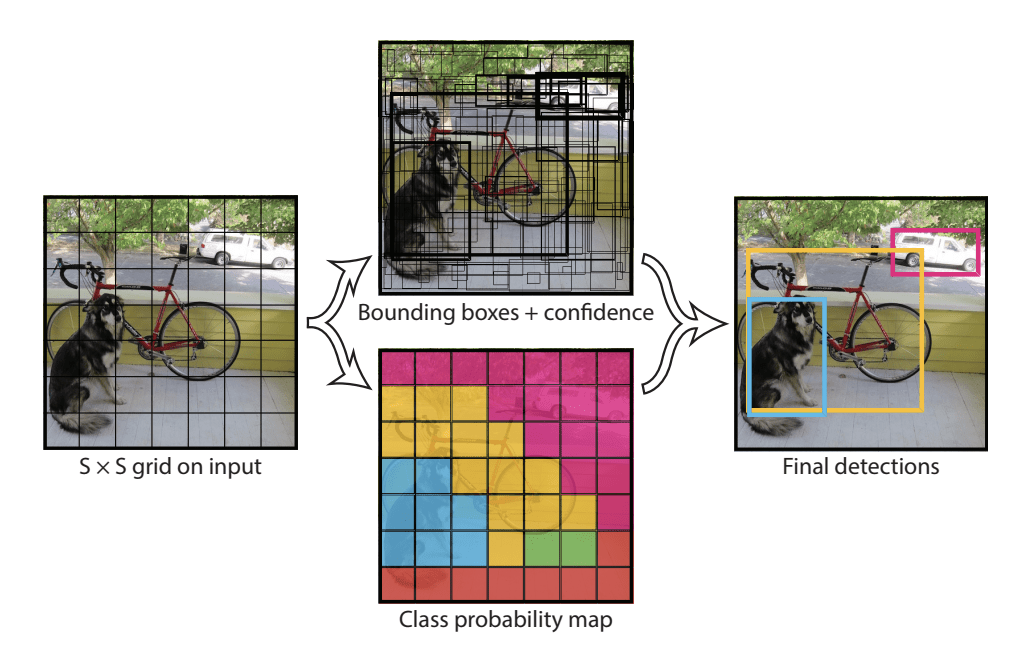
Sommario delle previsioni fatte dal modello YOLO.Tratto da: You Only Look Once: Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) e YOLOv3
Il modello è stato aggiornato da Joseph Redmon e Ali Farhadi nel tentativo di migliorarne ulteriormente le prestazioni nel loro documento del 2016 intitolato “YOLO9000: Better, Faster, Stronger.”
Anche se questa variante del modello è indicata come YOLO v2, viene descritta un’istanza del modello che è stata addestrata su due set di dati di riconoscimento degli oggetti in parallelo, in grado di prevedere 9.000 classi di oggetti, da cui il nome “YOLO9000.”
Sono state apportate diverse modifiche all’addestramento e all’architettura del modello, come l’uso della normalizzazione batch e delle immagini di input ad alta risoluzione.
Come Faster R-CNN, il modello YOLOv2 fa uso di anchor boxes, scatole di delimitazione predefinite con forme e dimensioni utili che vengono personalizzate durante l’addestramento. La scelta dei riquadri di delimitazione per l’immagine viene pre-elaborata utilizzando un’analisi k-means sul set di dati di allenamento.
Importante, la rappresentazione prevista dei riquadri di delimitazione viene modificata per consentire che piccoli cambiamenti abbiano un effetto meno drammatico sulle previsioni, risultando in un modello più stabile. Invece di prevedere direttamente la posizione e la dimensione, gli offset sono previsti per spostare e rimodellare le caselle di ancoraggio predefinite rispetto a una cella della griglia e smorzate da una funzione logistica.
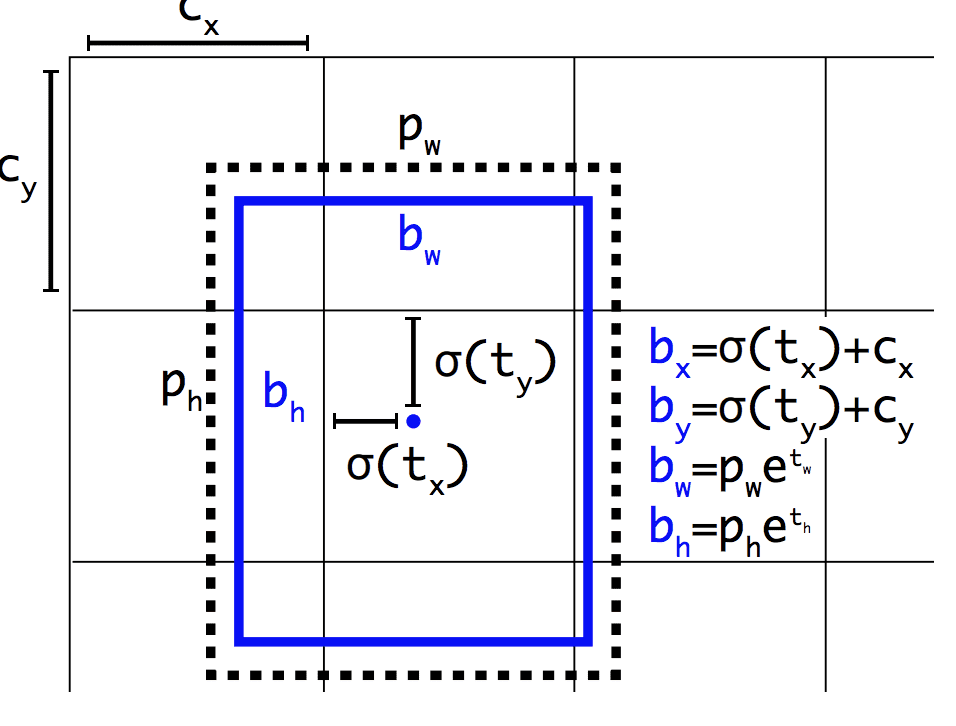
Esempio della rappresentazione scelta quando si predice la posizione e la forma del rettangolo di contornoTratto da: YOLO9000: Better, Faster, Stronger
Altri miglioramenti al modello sono stati proposti da Joseph Redmon e Ali Farhadi nel loro documento del 2018 intitolato “YOLOv3: An Incremental Improvement.” I miglioramenti erano ragionevolmente minori, tra cui una rete di rivelatori di caratteristiche più profonda e modifiche rappresentazionali minori.
Altre letture
Questa sezione fornisce ulteriori risorse sull’argomento se stai cercando di approfondire.
Papers
- ImageNet Large Scale Visual Recognition Challenge, 2015.
R-CNN Family Papers
- Rich feature hierarchies for accurate object detection and semantic segmentation, 2013.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, 2014.
- Fast R-CNN, 2015.
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
- Mask R-CNN, 2017.
YOLO Family Papers
- You Only Look Once: Unified, Real-Time Object Detection, 2015.
- YOLO9000: Better, Faster, Stronger, 2016.
- YOLOv3: An Incremental Improvement, 2018.
Code Projects
- R-CNN: Regions with Convolutional Neural Network Features, GitHub.
- R-CNN veloce, GitHub.
- Codice Python R-CNN più veloce, GitHub.
- YOLO, GitHub.
Risorse
- Ross Girshick, Homepage.
- Joseph Redmon, Homepage.
- YOLO: Real-Time Object Detection, Homepage.
Articoli
- Una breve storia delle CNN nella segmentazione delle immagini: From R-CNN to Mask R-CNN, 2017.
- Object Detection for Dummies Part 3: R-CNN Family, 2017.
- Object Detection Part 4: Fast Detection Models, 2018.
Summary
In questo post, hai scoperto una leggera introduzione al problema del riconoscimento degli oggetti e ai modelli di deep learning allo stato dell’arte progettati per affrontarlo.
In particolare, avete imparato:
- Il riconoscimento degli oggetti si riferisce a un insieme di compiti correlati per identificare gli oggetti nelle fotografie digitali.
- Le Reti Neurali Convoluzionarie Basate su Regioni, o R-CNN, sono una famiglia di tecniche per affrontare compiti di localizzazione e riconoscimento di oggetti, progettate per prestazioni da modello.
- You Only Look Once, o YOLO, è una seconda famiglia di tecniche per il riconoscimento di oggetti progettate per la velocità e l’uso in tempo reale.
Hai qualche domanda?
Poni le tue domande nei commenti qui sotto e farò del mio meglio per rispondere.
Sviluppa modelli di Deep Learning per la visione oggi!

Sviluppa i tuoi modelli di visione in pochi minuti
…con poche righe di codice python
Scopri come nel mio nuovo Ebook:
Deep Learning for Computer Vision
Fornisce tutorial autodidattici su argomenti come:
classificazione, rilevamento di oggetti (yolo e rcnn), riconoscimento di volti (vggface e facenet), preparazione dei dati e molto altro…
Finalmente porta l’apprendimento profondo ai tuoi progetti di visione
Skip the Academics. Solo risultati.
Vedi cosa c’è dentro