最終更新日:2021年1月27日
初心者にとって、異なる関連のコンピュータビジョン・タスクを区別することは困難なことかもしれません。
たとえば、画像の分類は簡単ですが、オブジェクトのローカライズとオブジェクトの検出の違いは、特に、3 つのタスクすべてがオブジェクト認識と同じように呼ばれている場合は、混乱する可能性があります。 オブジェクト検出はより困難で、これら2つのタスクを組み合わせ、画像内の関心のある各オブジェクトの周囲にバウンディングボックスを描き、それらにクラスラベルを割り当てる。
この投稿では、オブジェクト認識の問題への穏やかな導入と、それに対処するために設計された最先端のディープラーニングモデルを発見します。
私の新しい本「Deep Learning for Computer Vision」を使って、プロジェクトを始めましょう。

A Gentle Introduction to Object Recognition With Deep Learning
Photo by Bart Everson, some rights reserved.をご覧ください。
概要
このチュートリアルは3つのパートに分かれています:
- 物体認識とは?
- R-CNN Model Family
- YOLO Model Family
コンピュータビジョン向けの深層学習を使って結果を残したい方はこちら。
今すぐ7日間の無料Eメール クラッシュ コース(サンプル コード付き)を受講する。
クリックしてサインアップし、コースの無料のPDF電子書籍版も入手する。
無料のミニ コースをダウンロードする
物体認識とは何ですか?
物体認識は、デジタル写真内の物体を識別する関連するコンピューター ビジョン タスクのコレクションを表す一般用語です。
画像の分類では、画像内の 1 つの物体のクラスを予測する必要があります。 オブジェクトのローカライズは、画像内の1つまたは複数のオブジェクトの位置を特定し、その範囲の周りに囲み枠を描くことを意味します。 オブジェクト検出はこれら2つのタスクを組み合わせ、画像内の1つまたは複数のオブジェクトをローカライズおよび分類します。
ユーザーまたは実務者が「オブジェクト認識」と言う場合、多くの場合、「オブジェクト検出」を意味します。
… 我々は、画像分類(画像に存在するオブジェクト クラスを決定するアルゴリズムを必要とするタスク)とオブジェクト検出(画像に存在するすべてのオブジェクトを特定するアルゴリズムを必要とするタスク)の両方を包含する、オブジェクト認識という用語を広く使用します
– ImageNet Large Scale Visual Recognition Challenge, 2015.
このように、これらの3つのコンピュータビジョンタスクを区別することができます:
- Image Classification(画像分類)。 画像内のオブジェクトのタイプまたはクラスを予測する。
- 入力。 写真のような単一のオブジェクトを含む画像.
- 出力: クラスラベル(例えば、クラスラベルにマッピングされた1つ以上の整数)
- Object Localization: 画像中のオブジェクトの存在を特定し、その位置をバウンディングボックスで示す。
- Input: 写真のような1つ以上のオブジェクトを含む画像。
- 出力。 1つ以上のバウンディングボックス(例えば、点、幅、高さで定義)
- Object Detection: 画像内のバウンディングボックスを持つオブジェクトの存在と、位置したオブジェクトのタイプまたはクラスを検出する。
- 入力。 写真のような1つ以上のオブジェクトを含む画像。
- 出力。 コンピュータビジョンタスクのこの内訳のさらなる拡張は、「オブジェクトインスタンス分割」または「意味的分割」とも呼ばれるオブジェクト分割であり、認識されたオブジェクトのインスタンスは、粗い境界ボックスの代わりにオブジェクトの特定の画素を強調することによって示される。
この内訳から、オブジェクト認識は一連の困難なコンピュータ ビジョン タスクを指すことがわかります。
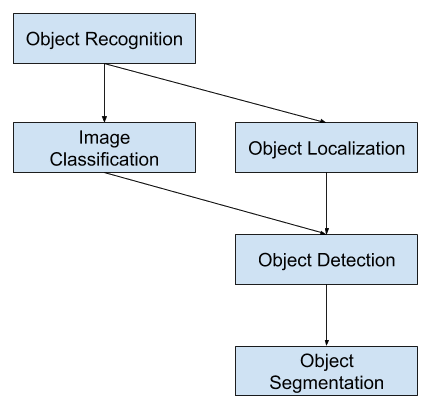
物体認識のコンピュータ ビジョン タスクの概要
画像認識問題における最近の革新のほとんどは、ILSVRC タスクへの参加の一部としてもたらされたものである。
これは、より広く活用できるように、各レベルで独立した別々の改善を促進することを意図して、これらの3つの問題タイプごとに別々の課題を持つ、毎年恒例の学術コンペティションである。 例えば、2015年のILSVRCのレビュー論文から引用した以下の3つの対応するタスクタイプのリストをご覧ください:
- Image classification: アルゴリズムは、画像内に存在するオブジェクトカテゴリのリストを生成する。
- 単一オブジェクトのローカライズ。
- オブジェクト検出:アルゴリズムは、画像内に存在するオブジェクトカテゴリのリストと、各オブジェクトカテゴリの1つのインスタンスの位置とスケールを示す軸合わせされたバウンディングボックスを生成します。 アルゴリズムは、画像内に存在するオブジェクトカテゴリのリストを、各オブジェクトカテゴリの1つのインスタンスの位置とスケールを示す軸合わせされたバウンディングボックスとともに生成する。
「単一オブジェクトのローカライズ」は、より広範な定義の「オブジェクトのローカライズ」をより単純化したもので、ローカライズ タスクを画像内の 1 種類のオブジェクトに制限しており、これはより簡単なタスクと想定できます。
以下は、ILSVRC 論文から引用した単一オブジェクト ローカライズとオブジェクト検出の比較例です。 各ケースでのグランドトゥルース期待値の違いに注意してください。
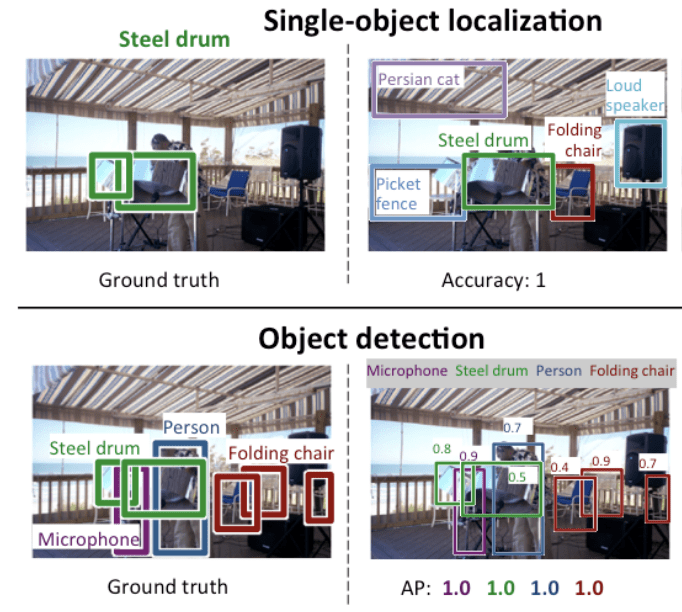
Comparison Between Single Object Localization and Object Detection.Taken From.ILSVRCの論文から抜粋。 ImageNet Large Scale Visual Recognition Challenge.
画像分類のモデルの性能は、予測されたクラスラベルの平均分類誤差を使用して評価されます。 単一オブジェクトのローカライズのためのモデルの性能は、予想されるクラスのための予想された境界ボックスと予測された境界ボックスの間の距離を使用して評価されます。 一方、オブジェクト認識のためのモデルの性能は、画像内の既知のオブジェクトに対するベストマッチング境界ボックスのそれぞれにわたる精度とリコールを使用して評価される。
さて、オブジェクトのローカライズと検出の問題に慣れてきたので、最近のトップパフォーマンスの深層学習モデルをいくつか見てみましょう。
R-CNNモデルファミリー
R-CNNファミリーの手法は、Ross Girshickらが開発した「Regions with CNN Features」または「Region-Based Convolutional Neural Network」を略したものと思われる、R-CNNを指しています。
これには、オブジェクトのローカライズおよびオブジェクト認識のために設計および実証された R-CNN、Fast R-CNN、および Faster-RCNN という手法が含まれます。
R-CNN
これらの各手法のハイライトを順に詳しく見ていきましょう。 from UC Berkeley titled “Rich feature hierarchies for accurate object detection and semantic segmentation.”
これは、オブジェクトのローカライズ、検出、セグメンテーションの問題に対する畳み込みニューラルネットワークの最初の大規模かつ成功した適用の1つであったと思われます。 このアプローチはベンチマークデータセットで実証され、VOC-2012 データセットと 200 クラスの ILSVRC-2013 オブジェクト検出データセットで当時の最先端結果を達成した。
彼らが提案した R-CNN モデルは、次の 3 つのモジュールで構成されている。 リージョンプロポーザル。 カテゴリに依存しない領域提案(例:バウンディングボックス候補)を生成・抽出する。 特徴抽出器。 各候補領域から特徴を抽出する。例えば、深い畳み込みニューラルネットワークを使用する。
モデルのアーキテクチャは、論文から引用した以下の画像にまとめられている。
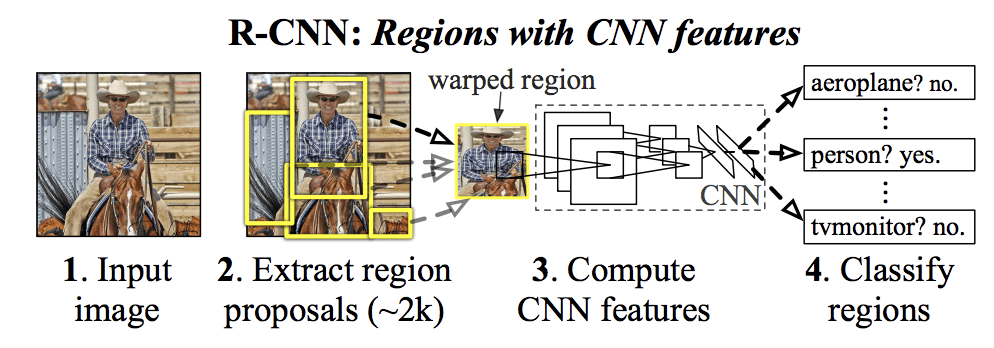
Summary of the R-CNN Model ArchitectureTaking from Rich feature hierarchies for accurate object detection and semantic segmentation.
「選択的探索」と呼ばれる画像内の潜在的なオブジェクトの候補領域または境界ボックスを提案するために、コンピューター ビジョン技術が使用されていますが、設計の柔軟性により、他の領域提案アルゴリズムも使用できます。
このモデルで使用する特徴抽出器は、ILSVRC 2012 画像分類コンテストで優勝した AlexNet 深層 CNN でした。 CNNの出力は、分類のために線形SVMに供給される画像の内容を記述する4096要素のベクトルであり、具体的には1つのSVMが既知の各クラスについて学習される。
これは、オブジェクトのローカライズと認識の問題に対するCNNの比較的単純で簡単なアプリケーションである。 このアプローチの欠点は、領域提案アルゴリズムによって生成された候補領域のそれぞれについて、CNN ベースの特徴抽出パスを必要とするため、時間がかかるということです。
論文で説明されているR-CNNのPython(Caffe)およびMatLabソースコードは、R-CNN GitHubリポジトリで公開されています。
Fast R-CNN
R-CNNの大きな成功を受け、当時Microsoft ResearchにいたRoss Girshick氏は、「Fast R-CNN」と題した2015年の論文でR-CNNの速度問題に対処する拡張機能を提案しました。”
論文は、冒頭に、以下のように要約できるR-CNNの制限を確認します:
- Training is a multi-stage pipeline. 3つの別々のモデルの準備と運用を含む。
- トレーニングは空間的にも時間的にも高価である。 画像ごとに非常に多くの領域提案に対するディープCNNのトレーニングは非常に遅い.
- オブジェクト検出が遅い.
- オブジェクト検出が遅い。 Make predictions using a deep CNN on so many region proposals is very slow.
先行研究として、2014年の論文 “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition” で空間ピラミッドプーリングネットワーク(SPPnets)という手法でスピードアップを提案しました。 これは特徴の抽出を高速化しましたが、本質的にはフォワードパスキャッシュアルゴリズムの一種を使用しました。
高速R-CNNは、地域と分類を直接学習して出力するパイプラインではなく、単一のモデルとして提案されています。
モデルのアーキテクチャは、写真を入力として地域の提案のセットを取り、それは深い畳み込みニューラルネットワークを通過しているのです。 特徴抽出には、VGG-16のような事前に学習されたCNNが使用される。 深層 CNN の最後は、Region of Interest Pooling Layer (RoI Pooling) と呼ばれるカスタム層で、与えられた入力候補領域に固有の特徴を抽出する。
CNN の出力は次に完全接続層で解釈され、モデルは、ソフトマックス層によるクラス予測用の出力と、境界ボックス用の線形出力との 2 つに二分化される。 このプロセスは、与えられた画像の関心領域ごとに複数回繰り返されます。
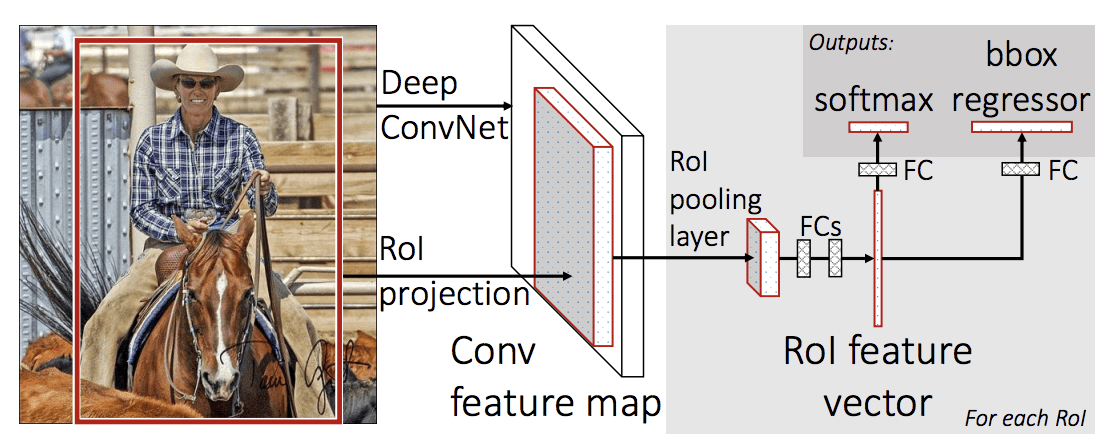
Summary of the Fast R-CNN Model Architecture(論文からの抜粋)です。
高速R-CNN。このモデルは、学習と予測を行うのが著しく高速ですが、それでも各入力画像とともに候補領域のセットが提案される必要があります。
論文に記載されているFast R-CNNのPythonおよびC++(Caffe)ソースコードは、GitHubリポジトリで公開されています。
Faster R-CNN
モデルアーキテクチャは、Microsoft ResearchのShaoqing Renらによって、「Faster R-CNN 」という2016年の論文で学習速度と検出速度両方についてさらに改善されています。 Towards Real-Time Object Detection with Region Proposal Networks」
このアーキテクチャは、ILSVRC-2015 と MS COCO-2015 オブジェクト認識および検出の競技タスクの両方で達成した 1 位の結果の基礎となりました。
このアーキテクチャは、地域提案ネットワーク、または RPN と呼ばれるトレーニング処理の一部として地域提案を提案して洗練する両方を目的としていました。 これらの領域は、その後、単一のモデル設計において、高速R-CNNモデルと協調して使用される。 これらの改善により、領域提案の数を減らし、モデルのテスト時の動作をほぼリアルタイムに加速し、その後、最先端の性能を発揮する。
… 我々の検出システムはGPUで5fpsのフレームレート(すべてのステップを含む)を持ち、一方で画像あたりわずか300提案でPASCAL VOC 2007、2012およびMS COCOデータセットで最先端のオブジェクト検出精度を達成した。 ILSVRCとCOCO 2015のコンペティションにおいて、Faster R-CNNとRPNは、いくつかのトラック
– Faster R-CNNの1位受賞作品の基礎となっている。 Towards Real-Time Object Detection with Region Proposal Networks, 2016.
単一の統一モデルであるが、アーキテクチャは2つのモジュールで構成されている:
- Module 1: 領域提案ネットワーク。 領域とその領域で考慮すべきオブジェクトの種類を提案するための畳み込みニューラルネットワーク。
- Module 2: Fast R-CNN. 提案された領域から特徴を抽出し、バウンディングボックスとクラスラベルを出力するための畳み込みニューラルネットワーク。
両方のモジュールは、深いCNNの同じ出力で動作します。 領域提案ネットワークは、Fast R-CNN ネットワークの注意メカニズムとして機能し、2 番目のネットワークにどこを見るか、または注意を払うかを知らせます。
このモデルのアーキテクチャは、論文から引用した以下の画像に要約されています。
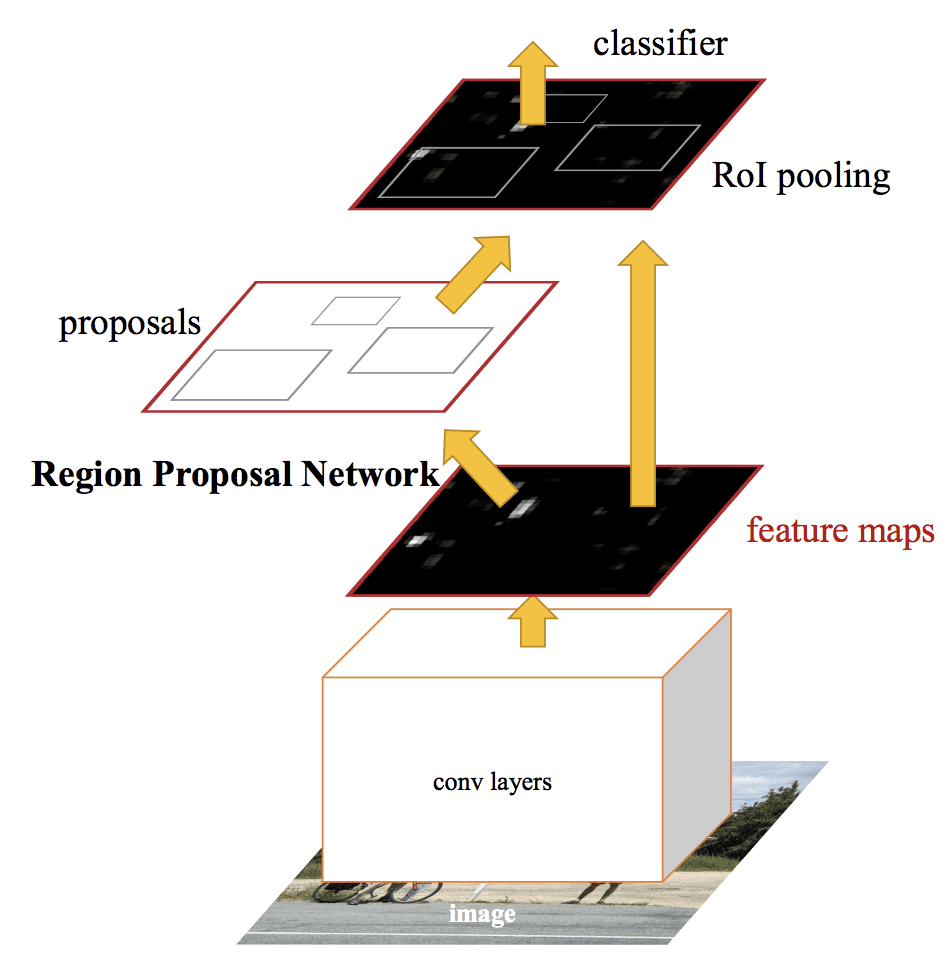
Summary of Faster R-CNN Model Architecture.Taken from: Faster R-CNN.The Faster R-CNN Model Architecture.Taken from: Faster R-CNN.The Faster R-CNN Model Architecture.Summary of Faster R-CNN: Towards Real-Time Object Detection With Region Proposal Networks.
RPNは、VGG-16などの事前学習済みの深いCNNの出力を取り、小さなネットワークを特徴マップに渡して、複数の領域提案とそれぞれに対するクラス予測を出力することで機能する。 領域提案は、いわゆるアンカーボックスや、領域の提案を高速化・向上させるために設計された事前定義された形状に基づくバウンディングボックスである。 クラス予測は2値であり、オブジェクトが存在するかどうか、提案された領域のいわゆる「オブジェクト性」を示す。
交互学習の手順が用いられ、両方のサブネットワークがインターリーブされながらも同時に学習される。 これにより、特徴検出器の深層 CNN のパラメーターは、同時に両方のタスクに対して調整または微調整される。
執筆時点では、この Faster R-CNN アーキテクチャはモデル ファミリーの頂点であり、オブジェクト認識タスクでほぼ最先端の結果を達成し続けている。 さらなる拡張により、画像分割のサポートが追加され、2017 年の論文「Mask R-CNN」で説明されています。
論文で説明されている Fast R-CNN の Python および C++ (Caffe) ソース コードは GitHub リポジトリで公開されています。
YOLO モデル ファミリー
オブジェクト認識モデルの別の人気ファミリーは YOLO または “You Only Look Once” として一括して呼ばれ、ジョセフ Redmon, et al.によって開発されました。
R-CNN モデルは一般により正確かもしれませんが、それでも YOLO モデル ファミリーは高速で、R-CNN よりはるかに速く、リアルタイムでオブジェクト検出を達成します。
YOLO
YOLO モデルは、Joseph Redmon, et al. が “You Only Look Once: Unified, Real-Time Object Detection” という 2015 年のペーパーで最初に説明したものです。 なお、R-CNN の開発者である Ross Girshick は、当時 Facebook AI Research でこの作品の著者および貢献者でもありました。
このアプローチでは、写真を入力として取り、境界ボックスと各境界ボックスのクラス ラベルを直接予測して、端から端まで学習した単一のニューラル ネットワークを使用します。 この手法では、予測精度が低くなりますが (たとえば、より多くのローカライズ エラー)、1 秒あたり 45 フレームで動作し、速度最適化バージョンのモデルでは 1 秒あたり最大 155 フレームまで動作します。 私たちのベースとなる YOLO モデルは、1 秒あたり 45 フレームでリアルタイムに画像を処理します。 ネットワークの小型バージョンである Fast YOLO は、1 秒間に 155 フレームという驚異的な速さで処理します…
– You Only Look Once: Unified, Real-Time Object Detection, 2015.7908>
モデルは、まず入力画像をセルのグリッドに分割し、各セルがバウンディング ボックスの中心がセル内に入る場合に、バウンディング ボックスを予測する責任を負うことで動作します。 各グリッドセルはx、y座標と幅、高さ、信頼度を含むバウンディングボックスを予測する。 クラス予測も各セルに基づいて行われる。
たとえば、イメージを 7×7 グリッドに分割し、グリッドの各セルは 2 つのバウンディング ボックスを予測し、その結果、94 のバウンディング ボックス予測が提案されることがある。 クラス確率マップと信頼度を持つバウンディングボックスは、その後、バウンディングボックスとクラスラベルの最終セットに結合されます。 以下の論文から引用した画像は、モデルの 2 つの出力を要約したものです。
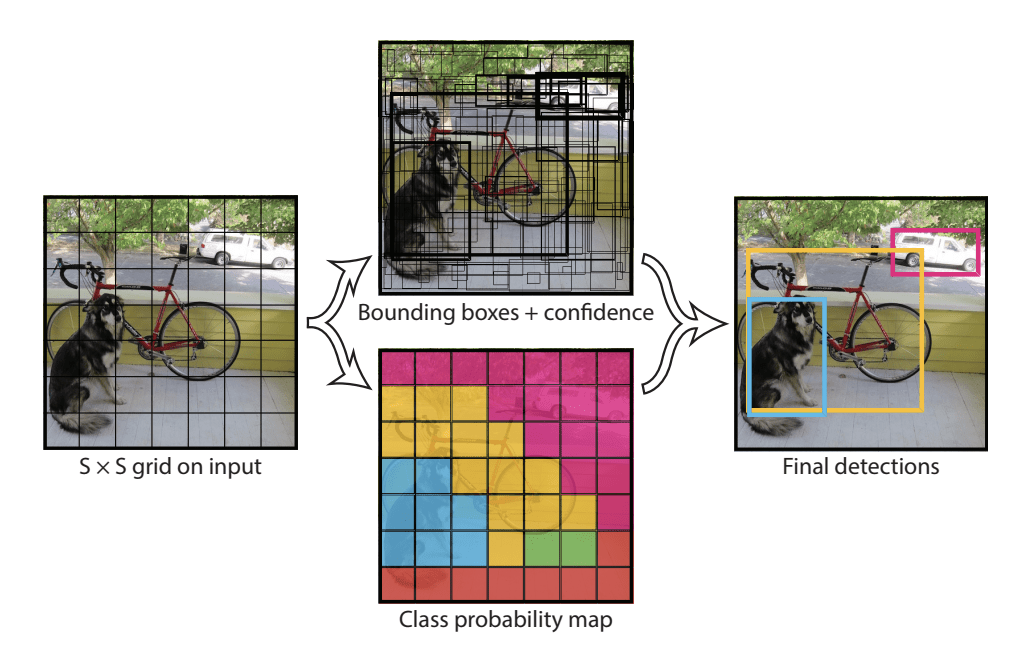
Summary of Predictions made by YOLO Model.NET(英語)。引用元: You Only Look Once: Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) and YOLOv3
このモデルは、Joseph Redmon と Ali Farhadi が、「YOLO9000: Better, Faster, Stronger」という 2016 年の論文でモデルのパフォーマンスをさらに改善しようと更新されたものです。”
このモデルのバリエーションはYOLO v2と呼ばれていますが、2つのオブジェクト認識データセットで並行して学習されたモデルのインスタンスは、9000のオブジェクトクラスを予測することができ、それゆえ「YOLO9000」という名前が付けられていることが記載されています。「
バッチ正規化や高解像度入力画像の使用など、多くの学習とアーキテクチャの変更がモデルに加えられた。
高速R-CNNと同様に、YOLOv2モデルはアンカーボックスを使用し、学習中に調整された有用な形とサイズを持つ事前定義された境界ボックスである。 画像のバウンディング ボックスの選択は、トレーニング データセットに対する k-means 分析を使用して前処理されます。
重要なのは、バウンディング ボックスの予測される表現が、小さな変化が予測にそれほど劇的な影響を与えないように変更され、より安定したモデルが得られるということです。 位置とサイズを直接予測するのではなく、グリッドセルに対して事前に定義されたアンカーボックスを移動および再形成するためのオフセットが予測され、ロジスティック関数によって減衰される。
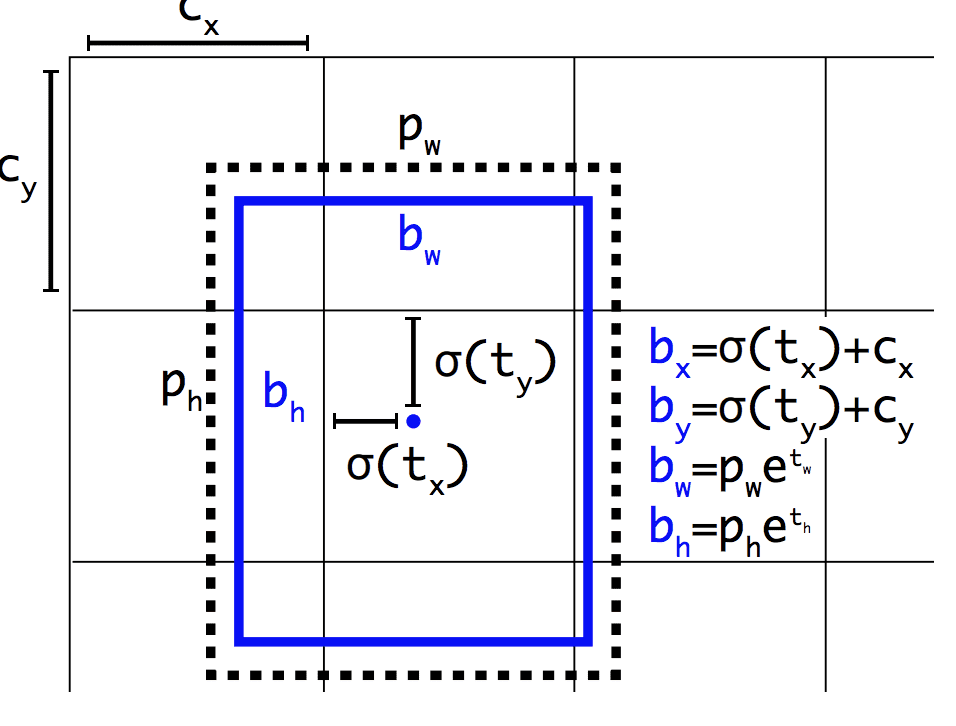
Example of the Representation Chosening Box Position and ShapeTaken from: YOLO9000: Better, Faster, Stronger
Joseph RedmonとAli Farhadiは2018年に “YOLOv3: An Incremental Improvement” という論文でモデルへのさらなる改良案を提示しました。 その改良は、より深い特徴検出ネットワークとマイナーな表現上の変更を含む、合理的にマイナーなものでした。
Further Reading
このセクションでは、より深く知りたい場合に、このトピックに関するさらなるリソースを提供します。
Papers
- ImageNet Large Scale Visual Recognition Challenge, 2015.
R-CNN Family Papers
- Rich feature hierarchies for accurate object detection and semantic segmentation, 2013.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, 2014.
- Fast R-CNN, 2015.
- Faster R-CNN.The R-CNN, 2015.R-CNN Family Papers
- Rich feature hierarchies for accurate object detection and semantic segmentation, 2013.
Papers
- Mask R-CNN, 2017.
YOLO Family Papers
- You Only Look Once: Unified, Real-Time Object Detection, 2015.
- Mask R-CNN
- YOLO9000: Better, Faster, Stronger, 2016.
- YOLOv3: An Incremental Improvement, 2018.
Mask R-CNN, 2015. Mask R-CNN, 2016.
Code Projects
- R-CNN: Regions with Convolutional Neural Network Features, GitHub.
- Fast R-CNN, GitHub.
- Faster R-CNN Python Code, GitHub.
- YOLO, GitHub.
Resources
- Ross Girshick, Homepage.NetCrunch.Inc.
- Joseph Redmon, Homepage.
- YOLO: Real-Time Object Detection, Homepage.
Articles
- A Brief History of CNNs in Image Segmentation.Overview: CNNの歴史。 From R-CNN to Mask R-CNN, 2017.
- Object Detection for Dummies Part 3: R-CNN Family, 2017.
- Object Detection Part 4: Fast Detection Models, 2018.
まとめ
この投稿で、オブジェクト認識の問題とそれに取り組むために設計された最新の深層学習モデルへの優しい紹介が見つかりました。
具体的には、次のことを学びました:
- オブジェクト認識とは、デジタル写真内のオブジェクトを識別するための関連タスクの集合を指します。
- Region-Based Convolutional Neural Networks (R-CNN) は、オブジェクトのローカライズおよび認識タスクを扱うための手法の 1 つで、モデル パフォーマンスのために設計されています。
- You Only Look Once (YOLO) は、速度とリアルタイム使用を目的にしたオブジェクト認識手法のもう 1 つのファミリです。
何か質問はありますか?
下のコメントで質問していただければ、できる限りお答えします。
Deep Learning Models for Vision Today!

数分で独自のビジョンモデルを開発
…9232>Deep Learning for Computer Vision
分類、物体検出(yolo と rcnn)、顔認識(vggface と facenet)、データ準備などのトピックに関する自習チュートリアルを提供しています。…
Finally Bring Deep Learning to your Vision Projects
Skip the Academics. Just Results.
See What’s Inside