Kolmogorov-Smirnov-statistik (KS) är en av de viktigaste mätvärdena som används för att validera prediktiva modeller. Den används ofta inom BFSI-området. Om du är en del av risk- eller marknadsanalysgruppen som arbetar med projekt inom banksektorn måste du ha hört talas om detta mått.
Vad är KS-statistik?
Det står för Kolmogorov-Smirnov som är uppkallat efter Andrey Kolmogorov och Nikolai Smirnov. Den jämför de två kumulativa fördelningarna och returnerar den största skillnaden mellan dem. Det är ett icke-parametriskt test, vilket innebär att du inte behöver testa något antagande om fördelningen av data. I KS-testet anger nollhypotesen att de båda kumulativa fördelningarna är likartade. Att förkasta nollhypotesen innebär att de kumulativa fördelningarna är olika.
I datavetenskap jämförs den kumulativa fördelningen av händelser och icke-händelser och KS är där det finns en maximal skillnad mellan de två fördelningarna. Med enkla ord hjälper det oss att förstå hur väl vår prediktiva modell kan skilja mellan händelser och icke-händelser.
Antag att du bygger en propensity-modell där målet är att identifiera potentiella kunder som sannolikt kommer att köpa en viss produkt. I det här fallet är den beroende variabeln (målvariabeln) binär och har endast två utfall: 0 (icke-händelse) eller 1 (händelse). Med ”händelse” avses personer som har köpt produkten. ”Icke-händelse” avser personer som inte köpte produkten. KS-statistiken mäter om modellen kan skilja mellan prospekt och icke-prospekt.
Två sätt att mäta KS-statistiken
Denna metod är det vanligaste sättet att beräkna KS-statistiken för att validera en binär prediktiv modell. Se stegen nedan.
- Du måste ha två variabler innan du beräknar KS. Den ena är den beroende variabeln som ska vara binär. Den andra är förutsedd sannolikhetspoäng som genereras från den statistiska modellen.
- Skapa deciler baserat på förutsedda sannolikhetskolumner vilket innebär att sannolikheten delas upp i 10 delar. Den första decilen bör innehålla den högsta sannolikhetspoängen.
- Beräkna den kumulativa procentandelen händelser och icke-händelser i varje decil och beräkna sedan skillnaden mellan dessa två kumulativa fördelningar.
- KS är den plats där skillnaden är som störst
- Om KS ligger i de tre översta decilerna och har en poäng på över 40, anses det vara en bra prediktiv modell. Samtidigt är det viktigt att validera modellen genom att även kontrollera andra prestandamått för att bekräfta att modellen inte lider av överanpassningsproblem.
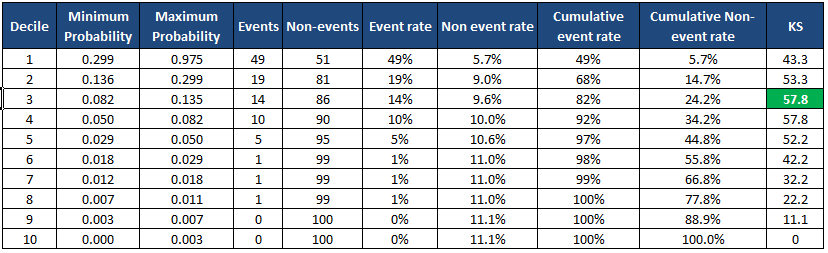
Python : KS Statistics Decile Method
Jag har förberett ett datamaterial för att visa ett exempel. Datasetet innehåller två kolumner som heter y och p.yär en beroende variabel.phänvisar till förutsedd sannolikhet.
import pandas as pdimport numpy as npdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
def ks(data=None,target=None, prob=None): data = 1 - data data = pd.qcut(data, 10) grouped = data.groupby('bucket', as_index = False) kstable = pd.DataFrame() kstable = grouped.min() kstable = grouped.max() kstable = grouped.sum() kstable = grouped.sum() kstable = kstable.sort_values(by="min_prob", ascending=False).reset_index(drop = True) kstable = (kstable.events / data.sum()).apply('{0:.2%}'.format) kstable = (kstable.nonevents / data.sum()).apply('{0:.2%}'.format) kstable=(kstable.events / data.sum()).cumsum() kstable=(kstable.nonevents / data.sum()).cumsum() kstable = np.round(kstable-kstable, 3) * 100 #Formating kstable= kstable.apply('{0:.2%}'.format) kstable= kstable.apply('{0:.2%}'.format) kstable.index = range(1,11) kstable.index.rename('Decile', inplace=True) pd.set_option('display.max_columns', 9) print(kstable) #Display KS from colorama import Fore print(Fore.RED + "KS is " + str(max(kstable))+"%"+ " at decile " + str((kstable.index==max(kstable)]))) return(kstable)
mydf = ks(data=df,target="y", prob="p")
-
datahänvisar till pandas dataframe som innehåller både beroende variabel och sannolikhetsvärden. -
targethänvisar till kolumnnamn för beroende variabel -
probhänvisar till kolumnnamn för förutsedd sannolikhet
Den returnerar information om varje decil i tabellformat och skriver även ut KS-poängen under tabellen. Den genererar också tabellen i en ny dataframe.
min_prob max_prob events nonevents event_rate nonevent_rate \Decile 1 0.298894 0.975404 49 51 49.00% 5.67% 2 0.135598 0.298687 19 81 19.00% 9.00% 3 0.082170 0.135089 14 86 14.00% 9.56% 4 0.050369 0.082003 10 90 10.00% 10.00% 5 0.029415 0.050337 5 95 5.00% 10.56% 6 0.018343 0.029384 1 99 1.00% 11.00% 7 0.011504 0.018291 1 99 1.00% 11.00% 8 0.006976 0.011364 1 99 1.00% 11.00% 9 0.002929 0.006964 0 100 0.00% 11.11% 10 0.000073 0.002918 0 100 0.00% 11.11% cum_eventrate cum_noneventrate KS Decile 1 49.00% 5.67% 43.3 2 68.00% 14.67% 53.3 3 82.00% 24.22% 57.8 4 92.00% 34.22% 57.8 5 97.00% 44.78% 52.2 6 98.00% 55.78% 42.2 7 99.00% 66.78% 32.2 8 100.00% 77.78% 22.2 9 100.00% 88.89% 11.1 10 100.00% 100.00% 0.0 KS is 57.8% at decile 3
Med hjälp avscipypythonbiblioteket kan vi beräkna KS-statistik med två prov. Den har två parametrar – data1 och data2. I data1 anger vi alla sannolikhetspoäng som motsvarar icke-händelser. I data2 kommer den att ta sannolikhetspoäng mot händelser.
from scipy.stats import ks_2sampdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")ks_2samp(df.loc, df.loc)
Den returnerar KS poäng 0,6033 och p-värde mindre än 0,01 vilket innebär att vi kan förkasta nollhypotesen och dra slutsatsen att fördelningen av händelser och icke-händelser skiljer sig åt.
OutputKs_2sampResult(statistic=0.6033333333333333, pvalue=1.1227180680661939e-29)
KS-poängen för metod 2 skiljer sig något från metod 1 eftersom den andra beräknas på radnivå och den första beräknas efter att ha konverterat data i tio delar.