
I ”Anomaly Detection with Autoencoders Made Easy” nämnde jag att autoenkoder har tillämpats i stor utsträckning för dimensionsminskning och reducering av bildbrus. Sedan dess har många läsare frågat om jag kan täcka ämnet bildbrusreduktion med hjälp av autoenkoder. Det är motivet till det här inlägget.
Modellering av bilddata kräver ett särskilt tillvägagångssätt i neurala nätverksvärlden. Det mest kända neurala nätverket för modellering av bilddata är det konvolutionella neurala nätverket (CNN, eller ConvNet) eller kallat Convolutional Autoencoder. I det här inlägget kommer jag att börja med en försiktig introduktion för bilddata eftersom inte alla läsare är inom området bilddata (du får gärna hoppa över det avsnittet om du redan är bekant med). Därefter beskriver jag ett enkelt standardneuralt nätverk för bilddata. Detta ger mig möjlighet att visa varför konvolutionella autoenkoder är den föredragna metoden när det gäller bilddata. Framför allt kommer jag att visa hur de konvolutionella autoenkoderna minskar bruset i en bild. Jag använder Keras-modulen och MNIST-data i det här inlägget. Anteckningsboken finns tillgänglig via den här länken. Keras är ett API för neurala nätverk på hög nivå, skrivet i Python och kan köras ovanpå TensorFlow. Det här inlägget är en förlängning av mitt tidigare inlägg ”What Is Image Recognition?” som jag uppmuntrar dig att ta en titt på.
Jag tyckte att det är bra att nämna de tre breda datakategorierna. De tre datakategorierna är: (1) Okorrelerade data (i motsats till seriella data), (2) Seriella data (inklusive text- och röstströmdata) och (3) bilddata. Djupinlärning har tre grundläggande varianter för att hantera varje datakategori: (1) det vanliga feedforward neurala nätverket, (2) RNN/LSTM och (3) Convolutional NN (CNN). För läsare som letar efter handledning för varje typ rekommenderas ”Explaining Deep Learning in a Regression-Friendly Way” för (1), den aktuella artikeln ”A Technical Guide for RNN/LSTM/GRU on Stock Price Prediction” för (2), och ”Deep Learning with PyTorch Is Not Torturing”, ”What Is Image Recognition?”, ”Anomaly Detection with Autoencoders Made Easy”, och ”Convolutional Autoencoders for Image Noise Reduction” för (3). Du kan lägga artikeln ”Dataman Learning Paths – Build Your Skills, Drive Your Career” som ett bokmärke.
Förstå bilddata
En bild består av ”pixlar” som visas i figur (A). I en svartvit bild representeras varje pixel av ett tal som sträcker sig från 0 till 255. De flesta bilder idag använder 24-bitars färg eller högre. En RGB-färgbild innebär att färgen i en pixel är en kombination av rött, grönt och blått, var och en av färgerna sträcker sig från 0 till 255. RGB-färgsystemet konstruerar alla färger från kombinationen av de röda, gröna och blå färgerna, vilket visas i den här RGB-färggeneratorn. Så en pixel innehåller en uppsättning av tre värden RGB(102, 255, 102) hänvisar till färgen #66ff66.

En bild med en bredd på 800 pixlar och en höjd på 600 pixlar har 800 x 600 = 480 000 pixlar = 0,48 megapixel (”megapixel” är 1 miljon pixlar). En bild med en upplösning på 1024×768 är ett rutnät med 1 024 kolumner och 768 rader, som därför innehåller 1 024 × 768 = 0,78 megapixel.
MNIST
MNIST-databasen (Modified National Institute of Standards and Technology database) är en stor databas med handskrivna siffror som vanligen används för att träna olika bildbehandlingssystem. Träningsdatasetet i Keras har 60 000 poster och testdatasetet har 10 000 poster. Varje post har 28 x 28 pixlar.
Hur ser de ut? Vi använder matplotlib och dess bildfunktion imshow() för att visa de tio första posterna.

Staplar bilddata för träning
För att passa in i ett neuralt nätverksramverk för modellträning kan vi stapla alla 28 x 28 = 784 värden i en kolumn. Den staplade kolumnen för den första posten ser ut så här: (med hjälp av x_train.reshape(1,784)):

Därefter kan vi träna modellen med ett vanligt neuralt nätverk enligt figur (B). Var och en av de 784 värdena är en nod i ingångsskiktet. Men vänta, förlorade vi inte mycket information när vi staplade data? Jo. De rumsliga och tidsmässiga sambanden i en bild har förkastats. Detta är en stor informationsförlust. Låt oss se hur de konvolutionella autoenkoderna kan behålla den spatiala och temporala informationen.

Varför lämpar sig de konvolutionella autoenkoderna för bilddata?
Vi ser en stor informationsförlust när vi skär upp och staplar data. I stället för att stapla data behåller de konvolutionella autoenkoderna den rumsliga informationen i de ingående bilddata som de är, och extraherar försiktigt information i det som kallas konvolutionslagret. Figur (D) visar att en platt 2D-bild extraheras till en tjock kvadrat (Conv1), som sedan fortsätter att bli en lång kubisk bild (Conv2) och ytterligare en längre kubisk bild (Conv3). Denna process är utformad för att bevara de rumsliga sambanden i uppgifterna. Detta är kodningsprocessen i en autokodare. I mitten finns en helt ansluten autoencoder vars dolda lager består av endast 10 neuroner. Efter det kommer med avkodningsprocessen som plattar ut kubikerna, sedan till en 2D platt bild. Kodaren och avkodaren är symmetriska i figur (D). De behöver inte vara symmetriska, men de flesta praktiker antar bara denna regel som förklaras i ”Anomaly Detection with Autoencoders made easy”.

Hur fungerar de konvolutionella autoenkoderna?
Ovanstående utvinning av data verkar magisk. Hur fungerar det egentligen? Det involverar följande tre lager: Det är följande tre skikt som används: konvolutionsskiktet, reLu-skiktet och poolningsskiktet.

- Konvolutionslagret
Konvolutionssteget skapar många små bitar som kallas funktionskartor eller funktioner som de gröna, röda eller marinblå rutorna i figur (E). Dessa rutor bevarar förhållandet mellan pixlarna i den ingående bilden. Låt varje feature skanna genom originalbilden som det som visas i figur (F). Denna process för att producera poäng kallas för filtrering.
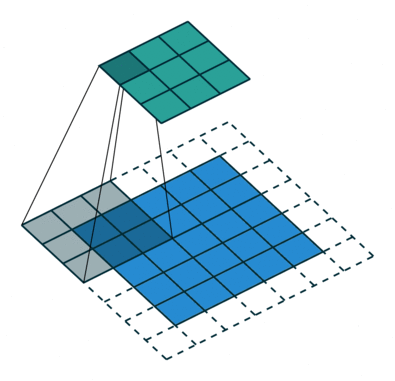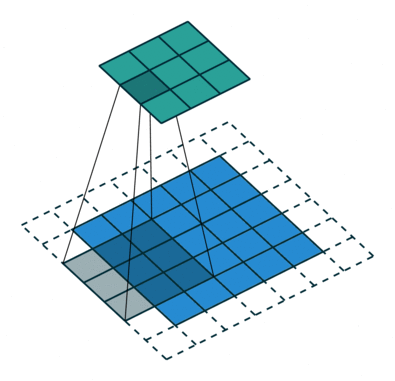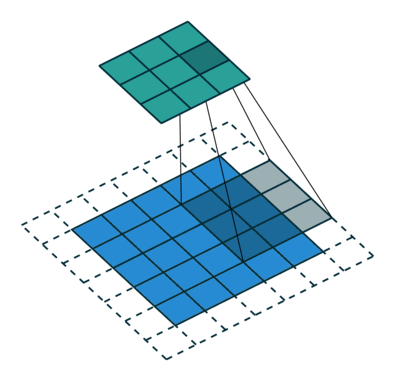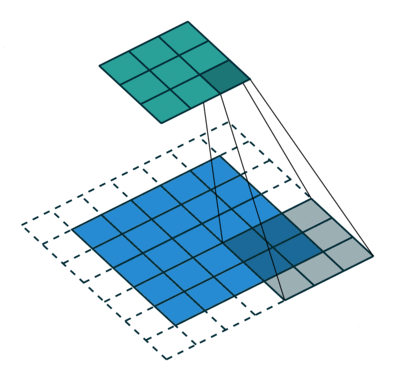
Efter att ha skannat igenom originalbilden ger varje funktion en filtrerad bild med höga poäng och låga poäng enligt figur (G). Om det finns en perfekt matchning finns det en hög poäng i den rutan. Om det finns en låg matchning eller ingen matchning är poängen låg eller noll. Till exempel hittade den röda kvadraten fyra områden i originalbilden som visar en perfekt matchning med funktionen, så poängen är höga för dessa fyra områden.

Fler filter innebär fler funktioner som modellen kan extrahera. Fler funktioner innebär dock längre utbildningstid. Så du rekommenderas att använda minsta möjliga antal filter för att extrahera egenskaperna.
1.1 Padding
Hur bestämmer egenskaperna matchningen? En hyperparameter är Padding som erbjuder två alternativ: (i) att fylla originalbilden med nollor för att passa funktionen, eller (ii) att ta bort den del av originalbilden som inte passar och behålla den giltiga delen.
1.2 Strides
Falsningslagret innehåller ytterligare en parameter: Stride. Det är antalet pixlar som förskjuts över inmatningsmatrisen. När stride är 1 skiftar filtren 1 pixel i taget. Vi kommer att se den i vår Keras-kod som en hyperparameter.
2. ReLUs steg
Den rektifierade linjära enheten (Rectified Linear Unit, ReLU) är det steg som är detsamma som steget i de typiska neurala nätverken. Det rätar upp alla negativa värden till noll för att garantera att matematiken beter sig korrekt.
3. Max Pooling Layer
Pooling krymper bildstorleken. I figur (H) skannar ett 2 x 2-fönster, som kallas poolstorlek, igenom var och en av de filtrerade bilderna och tilldelar maxvärdet i det 2 x 2-fönstret till en 1 x 1 ruta i en ny bild. Som framgår av figur (H) är maxvärdet i det första 2 x 2-fönstret ett högt värde (representerat av rött), så det höga värdet tilldelas 1 x 1-rutan.

Förutom att ta det maximala värdet finns andra mindre vanliga poolingmetoder som Average Pooling (tar medelvärdet) eller Sum Pooling (summan).

Efter pooling produceras en ny stapel med mindre filtrerade bilder. Nu delar vi upp de mindre filtrerade bilderna och staplar dem i en lista enligt figur (J).
Modell i Keras
De tre lagren ovan är byggstenarna i det neurala konvolutionsnätverket. Keras erbjuder följande två funktioner:
Du kan bygga många konvolutionslager i konvolutionsautoenkoder. I figur (E) finns det tre lager märkta Conv1, Conv2 och Conv3 i kodningsdelen. Så vi kommer att bygga därefter.
- Koden nedan
input_img = Input(shape=(28,28,1)deklarerar att den ingående 2D-bilden är 28 gånger 28. - Därefter byggs de tre lagren Conv1, Conv2 och Conv3.
- Märk väl att Conv1 ligger innanför Conv2 och att Conv2 ligger innanför Conv3.
- Den
paddingspecificerar vad som ska göras när filtret inte passar in i den ingående bilden bra.padding='valid'innebär att man släpper den del av bilden när filtret inte passar;padding='same'fyller bilden med nollor för att passa bilden.
Därefter fortsätter man att lägga till avkodningsprocessen. Så decode delen nedan har alla kodade och avkodade.
Keras api kräver deklaration av modellen och optimeringsmetoden:
-
Model(inputs= input_img,outputs= decoded): Modellen kommer att inkludera alla lager som krävs för beräkning av utdatadecodedgivet indatainput_img.compile(optimizer='adadelta',loss='binary_crossentropy'): Optimeringsmetoden utför optimering på samma sätt som gradient decent gör. De vanligaste är stochastic gradient decent (SGD), Adapted gradient (Adagrad) och Adadelta som är en förlängning av Adagrad. Se dokumentationen om Keras optimizer för detaljer. Förlustfunktionerna finns i dokumentationen om Keras förluster.
Nedan tränar jag modellen med x_train som både input och output. batch_size är antalet prov och epoch är antalet iterationer. Jag anger shuffle=True för att kräva att träningsdata ska blandas före varje epok.
Vi kan skriva ut de tio första originalbilderna och förutsägelserna för samma tio bilder.
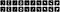
Hur man bygger en konvolutionskonvolutionskodare för reducering av brus i bilder?
Idén med reducering av brus i bilder är att träna en modell med störande data som ingångsvärden, och deras respektive klara data som utgångar. Detta är den enda skillnaden från ovanstående modell. Låt oss först lägga till brus till data.
De tio första bullriga bilderna ser ut på följande sätt:

Därefter tränar vi modellen med de störande uppgifterna som ingångsvärden och de rena uppgifterna som utgångar.
Slutligt skriver vi ut de tio första bullriga bilderna samt motsvarande avnouerade bilder.
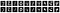
Notebooken finns tillgänglig via den här länken.
Är det någon förtränad CNN-kod som jag kan använda?
Ja. Om du är intresserad av att lära dig koden har Keras flera förtränade CNN:er, inklusive Xception, VGG16, VGG19, ResNet50, InceptionV3, InceptionResNetV2, MobileNet, DenseNet, NASNet och MobileNetV2. Det är värt att nämna denna stora bilddatabas ImageNet som du kan bidra med eller ladda ner för forskningsändamål.