Poslední aktualizace 27. ledna 2021
Pro začátečníky může být náročné rozlišit různé související úlohy počítačového vidění.
Například klasifikace obrazu je přímočará, ale rozdíly mezi lokalizací a detekcí objektů mohou být matoucí, zejména když všechny tři úlohy mohou být stejně dobře označovány jako rozpoznávání objektů.
Klasifikace obrazu zahrnuje přiřazení štítku třídy obrazu, zatímco lokalizace objektu zahrnuje vykreslení ohraničujícího rámečku kolem jednoho nebo více objektů v obraze. Rozpoznávání objektů je náročnější a kombinuje tyto dvě úlohy a kreslí ohraničující rámeček kolem každého objektu zájmu v obraze a přiřazuje jim značku třídy. Společně se všechny tyto problémy označují jako rozpoznávání objektů.
V tomto příspěvku objevíte jemný úvod do problému rozpoznávání objektů a nejmodernější modely hlubokého učení určené k jeho řešení.
Po přečtení tohoto příspěvku budete vědět:
- Rozpoznávání objektů se týká souboru souvisejících úloh pro identifikaci objektů na digitálních fotografiích.
- Regionální konvoluční neuronové sítě neboli R-CNN jsou rodinou technik pro řešení úloh lokalizace a rozpoznávání objektů, které jsou navrženy pro modelový výkon.
- You Only Look Once neboli YOLO je druhá rodina technik pro rozpoznávání objektů, která je navržena pro rychlost a použití v reálném čase.
Začněte svůj projekt s mou novou knihou Deep Learning for Computer Vision, která obsahuje výukové programy krok za krokem a zdrojové soubory jazyka Python pro všechny příklady.
Začněme.

Šetrný úvod do rozpoznávání objektů pomocí hlubokého učení
Foto: Bart Everson, některá práva vyhrazena.
Přehled
Tento výukový kurz je rozdělen do tří částí; jsou to:
- Co je to rozpoznávání objektů
- R-CNN rodina modelů
- YOLO rodina modelů
Chcete výsledky s hlubokým učením pro počítačové vidění?
Zúčastněte se nyní mého bezplatného 7denního e-mailového rychlokurzu (s ukázkovým kódem).
Klikněte pro registraci a získejte také bezplatnou verzi kurzu ve formátu PDF Ebook.
Stáhněte si svůj minikurz ZDARMA
Co je to rozpoznávání objektů?
Rozpoznávání objektů je obecný termín popisující soubor příbuzných úloh počítačového vidění, které zahrnují identifikaci objektů na digitálních fotografiích.
Klasifikace obrázků zahrnuje předpověď třídy jednoho objektu na obrázku. Lokalizace objektů se týká identifikace umístění jednoho nebo více objektů v obraze a vykreslení abounding boxu kolem jejich rozsahu. Detekce objektů kombinuje tyto dvě úlohy a lokalizuje a klasifikuje jeden nebo více objektů v obraze.
Když uživatel nebo odborník z praxe hovoří o „rozpoznávání objektů“, často tím myslí „detekci objektů“.
… budeme používat termín rozpoznávání objektů v širším smyslu, aby zahrnoval jak klasifikaci obrazu (úloha vyžadující, aby algoritmus určil, jaké třídy objektů jsou v obraze přítomny), tak detekci objektů (úloha vyžadující, aby algoritmus lokalizoval všechny objekty přítomné v obraze
– ImageNet Large Scale Visual Recognition Challenge, 2015.
Jako takové můžeme rozlišovat tyto tři úlohy počítačového vidění:
- Klasifikace obrazu:
- Vstupní údaje: Předpovídejte typ nebo třídu objektu na obrázku:
- Výstup: Obrázek s jedním objektem, například fotografií:
- Lokalizace objektu:
- Vstup: Lokalizovat přítomnost objektů v obraze a označit jejich polohu pomocí ohraničujícího rámečku:
- Výstup: Obrázek s jedním nebo více objekty, například fotografie:
- Detekce objektu: Jeden nebo více ohraničujících boxů (např. definovaných bodem, šířkou a výškou):
- Vstup: Vyhledání přítomnosti objektů s ohraničujícím rámečkem a typy nebo třídy umístěných objektů v obraze:
- Výstup: Obrázek s jedním nebo více objekty, například fotografie:
Jedním z dalších rozšíření tohoto rozdělení úloh počítačového vidění je segmentace objektů, nazývaná také „segmentace instancí objektů“ nebo „sémantická segmentace“, kde jsou instance rozpoznaných objektů označeny zvýrazněním konkrétních pixelů objektu namísto hrubého ohraničujícího boxu.
Z tohoto rozdělení vidíme, že rozpoznávání objektů se týká souboru náročných úloh počítačového vidění.
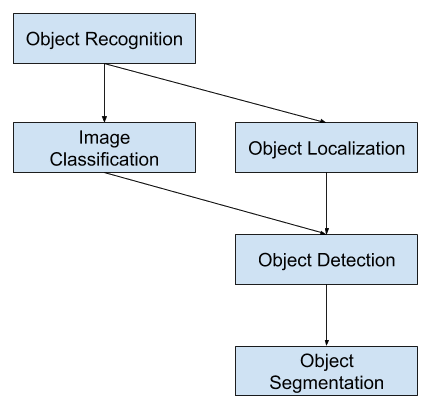
Přehled úloh počítačového vidění v oblasti rozpoznávání objektů
Většina nedávných inovací v problematice rozpoznávání obrazu přišla v rámci účasti na úlohách ILSVRC.
Jedná se o každoroční akademickou soutěž se samostatnou úlohou pro každý z těchto tří typů problémů se záměrem podpořit nezávislá a samostatná zlepšení na každé úrovni, která lze využít v širším měřítku. Viz například níže uvedený seznam tří odpovídajících typů úloh převzatý z přehledového dokumentu ILSVRC z roku 2015:
- Klasifikace obrázků: Algoritmy vytvářejí seznam kategorií objektů přítomných v obraze.
- Lokalizace jednotlivých objektů: Algoritmy vytvářejí seznam kategorií objektů přítomných v obraze spolu s osově zarovnaným ohraničujícím rámečkem udávajícím polohu a měřítko jedné instance každé kategorie objektů.
- Detekce objektů: Algoritmy vytvoří seznam kategorií objektů přítomných v obraze spolu s osově zarovnaným ohraničujícím rámečkem udávajícím polohu a měřítko každé instance každé kategorie objektů.
Vidíme, že „lokalizace jednoho objektu“ je jednodušší verzí šířeji definované „lokalizace objektu“, která omezuje úlohy lokalizace na objekty jednoho typu v rámci obrazu, což můžeme předpokládat jako jednodušší úlohu.
Níže je uveden příklad porovnání lokalizace jednoho objektu a detekce objektu, převzatý z dokumentu ILSVRC. Všimněte si rozdílu v očekávání základní pravdy v každém případě.
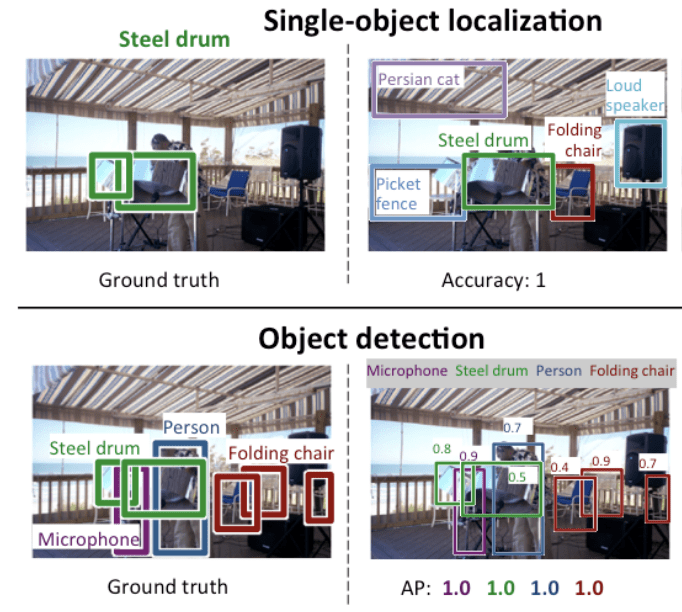
Srovnání mezi lokalizací jednoho objektu a detekcí objektu. převzato z: ImageNet Large Scale Visual Recognition Challenge.
Výkonnost modelu pro klasifikaci obrazu se hodnotí pomocí průměrné chyby klasifikace napříč předpovídanými značkami tříd. Výkonnost modelu pro lokalizaci jednoho objektu se vyhodnocuje pomocí vzdálenosti mezi očekávaným a předpovídaným ohraničujícím polem pro očekávanou třídu. Zatímco výkonnost modelu pro rozpoznávání objektů se hodnotí pomocí přesnosti a odvolávky napříč každým z nejlépe odpovídajících ohraničujících boxů pro známé objekty na obrázku.
Když jsme se seznámili s problematikou lokalizace a detekce objektů, podívejme se na některé nedávné nejvýkonnější modely hlubokého učení.
R-CNN rodina modelů
Rodina metod R-CNN odkazuje na R-CNN, což může znamenat „Regions with CNN Features“ nebo „Region-Based Convolutional Neural Network“, vyvinutý Rossem Girshickem a kol.
Jedná se o techniky R-CNN, Fast R-CNN a Faster-RCNN, které byly navrženy a demonstrovány pro lokalizaci a rozpoznávání objektů.
Podívejme se postupně na nejdůležitější prvky každé z těchto technik.
R-CNN
R-CNN byla popsána v roce 2014 v článku Rosse Girshicka a kol. z Kalifornské univerzity v Berkeley s názvem „Rich feature hierarchies for accurate object detection and semantic segmentation.“
Možná se jedná o jednu z prvních velkých a úspěšných aplikací konvolučních neuronových sítí na problém lokalizace, detekce a segmentace objektů. Přístup byl demonstrován na srovnávacích souborech dat, přičemž dosáhl tehdy nejlepších výsledků na datovém souboru VOC-2012 a datovém souboru pro detekci objektů ILSVRC-2013 o 200 třídách.
Jimi navržený model R-CNN se skládá ze tří modulů; jsou to:
- Modul 1: Návrh regionu. Generuje a extrahuje návrhy regionů nezávislé na kategorii, např. kandidátní ohraničující boxy.
- Modul 2: Extraktor prvků. Extrakce příznaků z každého kandidátského regionu, např. pomocí hluboké konvoluční neuronové sítě.
- Modul 3: Klasifikátor. Klasifikujte rysy jako jednu ze známých tříd, např. lineárním modelem klasifikátoru SVM.
Architektura modelu je shrnuta na obrázku níže, převzatém z článku.
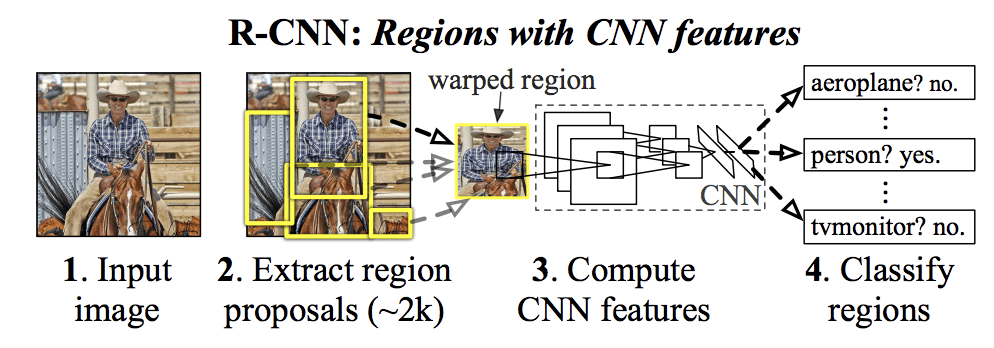
Souhrn architektury modelu R-CNNPřevzato z Bohaté hierarchie rysů pro přesnou detekci objektů a sémantickou segmentaci.
K navrhování kandidátních oblastí nebo ohraničujících boxů potenciálních objektů v obraze se používá technika počítačového vidění zvaná „selektivní vyhledávání“, ačkoli flexibilita návrhu umožňuje použít i jiné algoritmy navrhování oblastí.
Extraktor příznaků použitý modelem byl hluboký CNN AlexNet, který zvítězil v soutěži ILSVRC-2012 v klasifikaci obrazů. Výstupem CNN byl vektor o 4 096 prvcích popisující obsah obrazu, který je přiváděn do lineárního SVM pro klasifikaci, konkrétně je pro každou známou třídu natrénován jeden SVM.
Jedná se o poměrně jednoduchou a přímočarou aplikaci CNN na problém lokalizace a rozpoznávání objektů. Nevýhodou tohoto přístupu je, že je pomalý, protože vyžaduje průchod extrakce příznaků na základě CNN pro každou z kandidátních oblastí vygenerovaných algoritmem návrhu oblasti. To je problém, protože článek popisuje model pracující s přibližně 2 000 navrženými regiony na jeden obrázek v době testu.
Zdrojový kód pro R-CNN v jazycích Python (Caffe) a MatLab popsaný v článku byl zpřístupněn v repozitáři R-CNN GitHub.
Rychlý R-CNN
Vzhledem k velkému úspěchu R-CNN navrhl Ross Girshick, tehdy ve společnosti Microsoft Research, v roce 2015 v článku nazvaném „Rychlý R-CNN“ rozšíření, které by řešilo problémy s rychlostí R-CNN.
Článek začíná přehledem omezení R-CNN, která lze shrnout následovně:
- Trénování je vícestupňová pipeline. Zahrnuje přípravu a provoz tří samostatných modelů.
- Trénování je prostorově a časově nákladné. Trénování hluboké CNN na tolika návrzích oblastí na jeden obrázek je velmi pomalé.
- Detekce objektů je pomalá. Provádět předpovědi pomocí hluboké sítě CNN na tolika návrzích oblastí je velmi pomalé.
Předchozí práce navrhla zrychlení techniky zvané sítě s prostorovým pyramidovým sdružováním neboli SPPnets v článku „Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition“ z roku 2014. To sice urychlilo extrakci rysů, ale v podstatě použilo typ algoritmu cachování dopředného průchodu.
Rychlá R-CNN je navržena jako jediný model namísto potrubí pro učení a výstup regionů a klasifikací přímo.
Architektura modelu bere jako vstup fotografii sadu návrhů regionů, které procházejí hlubokou konvoluční neuronovou sítí. Pro extrakci příznaků se používá předem natrénovaná CNN, například VGG-16. Na konci hluboké CNN je vlastní vrstva nazvaná Region of Interest Pooling Layer neboli RoI Pooling, která extrahuje rysy specifické pro daný vstupní kandidátský region.
Výstup CNN je pak interpretován plně propojenou vrstvou, pak se model rozdvojí na dva výstupy, jeden pro predikci třídy prostřednictvím vrstvy softmax a druhý s lineárním výstupem pro ohraničení. Tento proces se pak opakuje několikrát pro každou oblast zájmu na daném snímku.
Architektura modelu je shrnuta na obrázku níže, převzatém z článku.
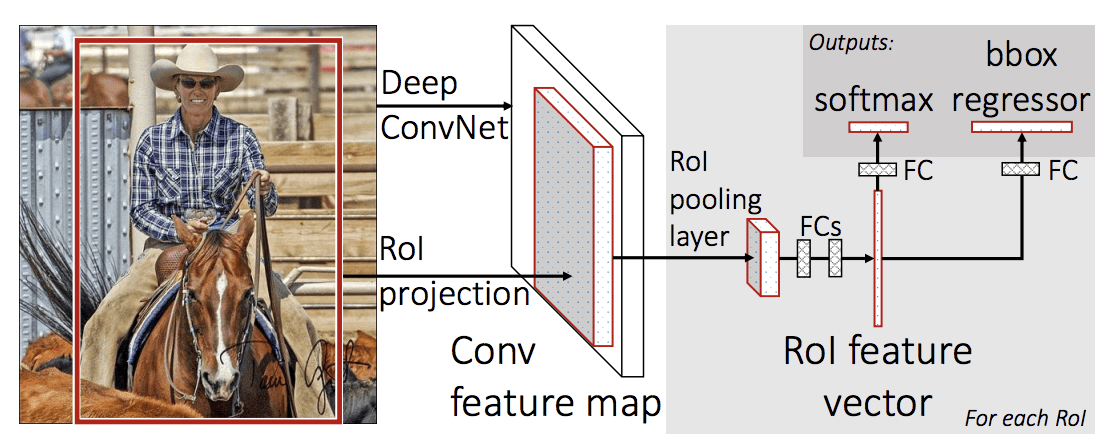
Souhrn architektury modelu Rychlá R-CNN.
Převzato z: Fast R-CNN.
Model je výrazně rychlejší při trénování a vytváření předpovědí, přesto však vyžaduje, aby byla spolu s každým vstupním obrázkem navržena sada kandidátních oblastí.
Zdrojový kód jazyka Python a C++ (Caffe) pro Fast R-CNN popsaný v článku byl zpřístupněn v repozitáři GitHub.
Faster R-CNN
Architektura modelu byla dále vylepšena z hlediska rychlosti trénování i detekce Shaoqingem Renem a kol. ze společnosti Microsoft Research v článku z roku 2016 s názvem „Faster R-CNN: Architektura byla základem pro výsledky na prvních místech dosažené v úlohách soutěže ILSVRC-2015 a MS COCO-2015 pro rozpoznávání a detekci objektů.
Architektura byla navržena tak, aby v rámci procesu trénování navrhovala i zpřesňovala návrhy regionů, označované jako Region Proposal Network neboli RPN. Tyto regiony se pak používají společně s modelem Fast R-CNN v jediném návrhu modelu. Tato vylepšení jednak snižují počet návrhů regionů, jednak zrychlují fungování modelu v testovacím čase na úroveň blízkou reálnému času s tehdejším nejlepším výkonem.
… náš detekční systém má snímkovou frekvenci 5 snímků za sekundu (včetně všech kroků) na GPU, přičemž dosahuje nejmodernější přesnosti detekce objektů na datových sadách PASCAL VOC 2007, 2012 a MS COCO s pouhými 300 návrhy na snímek. V soutěžích ILSVRC a COCO 2015 jsou Faster R-CNN a RPN základem vítězných prací na 1. místě v několika stopách
– Faster R-CNN:
Ačkoli se jedná o jeden jednotný model, architektura se skládá ze dvou modulů:
- Modul 1: Síť návrhů regionů. Konvoluční neuronová síť pro navrhování regionů a typu objektu, který se má v regionu zohlednit.
- Modul 2: Konvoluční neuronová síť pro navrhování regionů: Fast R-CNN. Konvoluční neuronová síť pro extrakci rysů z navržených regionů a výstup ohraničujícího boxu a štítků tříd.
Oba moduly pracují se stejným výstupem hluboké CNN. Síť pro navrhování regionů funguje jako mechanismus pozornosti pro síť Fast R-CNN a informuje druhou síť o tom, kam se má podívat nebo čemu má věnovat pozornost.
Architektura modelu je shrnuta na obrázku níže, převzatém z článku.
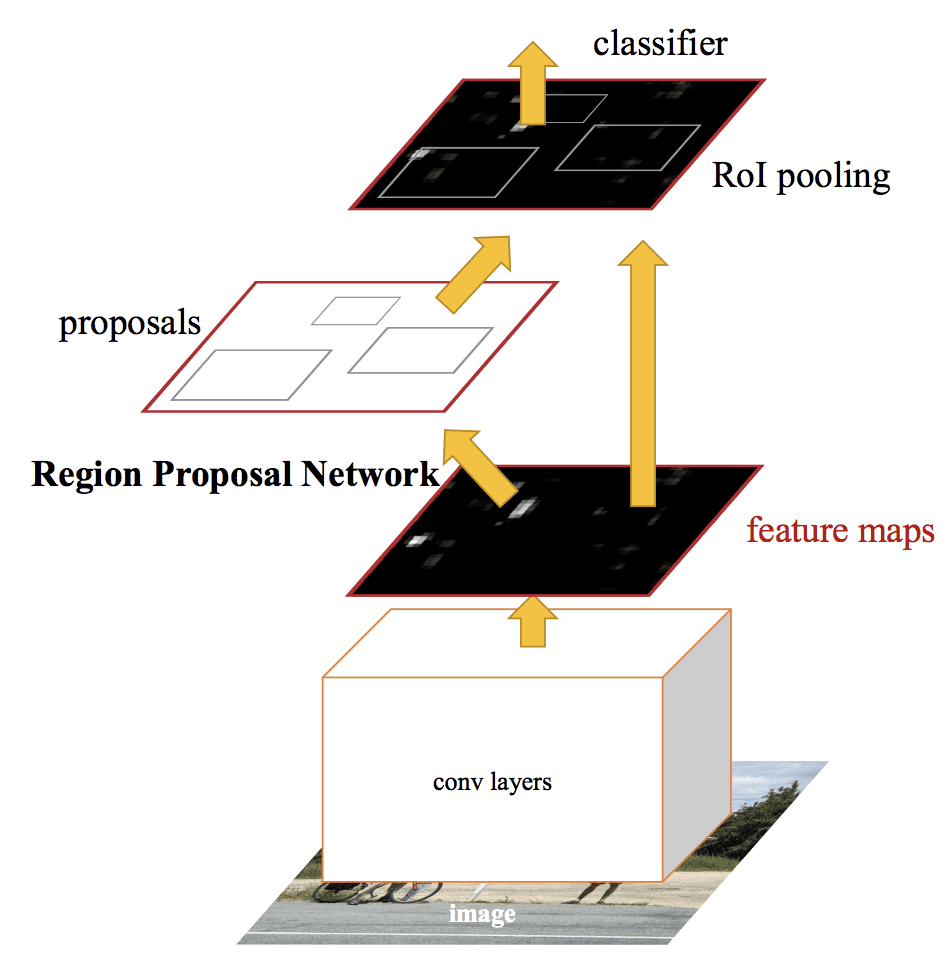
Souhrn architektury modelu Faster R-CNN.Převzato z: Faster R-CNN:
RPN funguje tak, že vezme výstup předtrénované hluboké sítě CNN, jako je VGG-16, projde mapou prvků malou sítí a na výstupu vytvoří několik návrhů oblastí a pro každou z nich předpověď třídy. Návrhy regionů jsou ohraničující boxy, založené na tzv. kotevních boxech nebo předem definovaných tvarech určených k urychlení a zlepšení návrhů regionů. Předpověď třídy je binární, udává přítomnost objektu, nebo ne, takzvanou „objektovost“ navrhovaného regionu.
Používá se postup střídavého trénování, kdy se obě dílčí sítě trénují současně, i když prokládaně. To umožňuje přizpůsobit nebo doladit parametry v hluboké síti CNN s detektorem příznaků pro obě úlohy současně.
V době psaní tohoto článku je tato architektura Faster R-CNN vrcholem rodiny modelů a nadále dosahuje téměř špičkových výsledků v úlohách rozpoznávání objektů. Další rozšíření přidává podporu segmentace obrazu, která je popsána v článku z roku 2017 „Mask R-CNN.“
Zdrojový kód jazyka Python a C++ (Caffe) pro Fast R-CNN popsaný v článku byl zpřístupněn v repozitáři GitHub.
Rodina modelů YOLO
Další populární rodina modelů pro rozpoznávání objektů je označována souhrnným názvem YOLO neboli „You Only Look Once“, kterou vyvinul Joseph Redmon a kol.
Modely R-CNN mohou být obecně přesnější, přesto je rodina modelů YOLO rychlá, mnohem rychlejší než R-CNN, a dosahuje detekce objektů v reálném čase.
YOLO
Model YOLO byl poprvé popsán Josephem Redmonem a kol. v článku z roku 2015 s názvem „You Only Look Once: Unified, Real-Time Object Detection“. Všimněte si, že autorem a přispěvatelem této práce byl také Ross Girshick, vývojář R-CNN, tehdy ve společnosti Facebook AI Research.
Přístup zahrnuje jedinou neuronovou síť natrénovanou od konce ke konci, která bere jako vstup fotografii a přímo předpovídá ohraničující boxy a štítky tříd pro každý ohraničující box. Tato technika nabízí nižší přesnost predikce (např. více lokalizačních chyb), ačkoli pracuje rychlostí 45 snímků za sekundu a až 155 snímků za sekundu u verze modelu optimalizované pro rychlost.
Naše jednotná architektura je extrémně rychlá. Náš základní model YOLO zpracovává snímky v reálném čase rychlostí 45 snímků za sekundu. Menší verze sítě, Fast YOLO, zpracovává ohromujících 155 snímků za sekundu…
– You Only Look Once: Unified, Real-Time Object Detection, 2015.
Model funguje tak, že nejprve rozdělí vstupní obraz na síť buněk, kde každá buňka je zodpovědná za předpověď ohraničujícího rámečku, pokud střed ohraničujícího rámečku spadá do této buňky. Každá buňka mřížky předpovídá ohraničující rámeček zahrnující souřadnice x, y a šířku a výšku a důvěryhodnost. Na každé buňce je také založena predikce třídy.
Například obrázek může být rozdělen do mřížky 7×7 a každá buňka v mřížce může predikovat 2 ohraničující boxy, což vede k 94 navrženým predikcím ohraničujících boxů. Mapa pravděpodobností tříd a ohraničující boxy s důvěryhodnostmi se pak spojí do konečné sady ohraničujících boxů a značek tříd. Obrázek převzatý z článku níže shrnuje dva výstupy modelu.
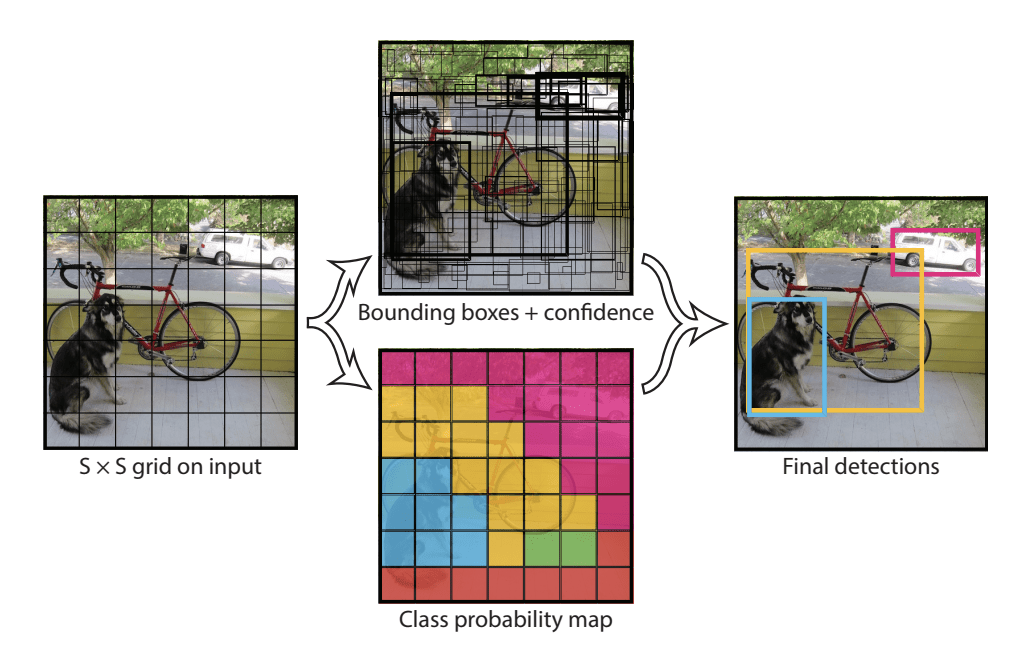
Souhrn předpovědí provedených modelem YOLO.Převzato z: You Only Look Once: Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) a YOLOv3
Model byl aktualizován Josephem Redmonem a Ali Farhadim ve snaze dále zlepšit výkon modelu v jejich článku z roku 2016 s názvem „YOLO9000: Better, Faster, Stronger.“
Ačkoli je tato varianta modelu označována jako YOLO v2, je popsána instance modelu, která byla natrénována na dvou souborech dat pro rozpoznávání objektů paralelně a byla schopna předpovídat 9 000 tříd objektů, proto dostala název „YOLO9000.“
V modelu byla provedena řada tréninkových a architektonických změn, například použití dávkové normalizace a vstupních obrázků s vysokým rozlišením.
Stejně jako Faster R-CNN využívá model YOLOv2 kotevní boxy, předem definované ohraničující boxy s užitečnými tvary a velikostmi, které jsou přizpůsobeny během trénování. Výběr ohraničujících boxů pro obrázek je předem zpracován pomocí analýzy k-means na souboru trénovacích dat.
Důležité je, že předpovídaná reprezentace ohraničujících boxů se mění, aby malé změny měly méně dramatický vliv na předpovědi, což vede ke stabilnějšímu modelu. Namísto přímého předpovídání polohy a velikosti se předpovídají posuny pro přesun a změnu tvaru předdefinovaných kotevních boxů vzhledem k buňce mřížky a tlumí se logistickou funkcí.
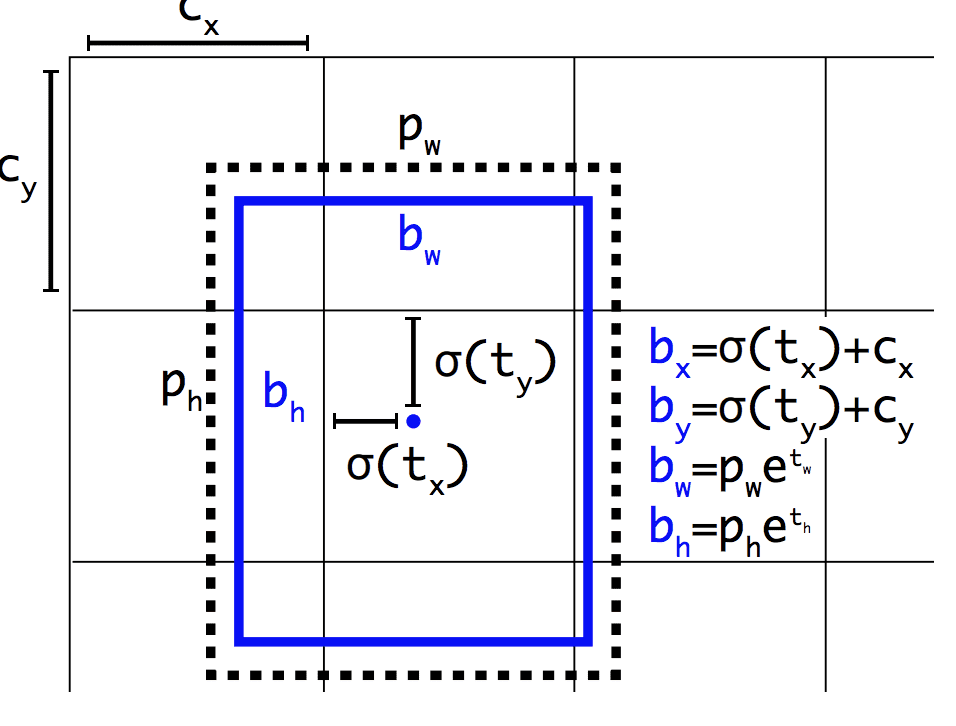
Příklad reprezentace zvolené při předpovídání polohy a tvaru ohraničujícího rámečkuPřevzato z: YOLO9000: Better, Faster, Stronger
Další vylepšení modelu navrhli Joseph Redmon a Ali Farhadi ve svém článku z roku 2018 s názvem „YOLOv3: An Incremental Improvement“. Vylepšení byla poměrně malá, zahrnovala hlubší síť detektoru příznaků a drobné reprezentační změny.
Další čtení
Tato část obsahuje další zdroje k tématu, pokud chcete jít hlouběji.
Papers
- ImageNet Large Scale Visual Recognition Challenge, 2015.
R-CNN Family Papers
- Rich feature hierarchies for accurate object detection and semantic segmentation, 2013.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, 2014.
- Fast R-CNN, 2015.
- Faster R-CNN:
- Mask R-CNN, 2017.
YOLO Family Papers
- You Only Look Once: Unified, Real-Time Object Detection, 2015.
- YOLO9000: Better, Faster, Stronger, 2016.
- YOLOv3: An Incremental Improvement, 2018.
Kódové projekty
- R-CNN: GitHub.
- Rychlá R-CNN, GitHub.
- Rychlejší kód R-CNN v jazyce Python, GitHub.
- YOLO, GitHub.
Resources
- Ross Girshick, Úvodní stránka.
- Joseph Redmon, Homepage.
- YOLO: Real-Time Object Detection, Homepage.
Articles
- A Brief History of CNNs in Image Segmentation:
- Detekce objektů pro hlupáky, část 3: Rodina R-CNN, 2017.
- Detekce objektů, část 4: Rychlé modely detekce, 2018.
Shrnutí
V tomto příspěvku jste objevili jemný úvod do problematiky rozpoznávání objektů a nejmodernější modely hlubokého učení určené k jeho řešení.
Konkrétně jste se dozvěděli:
- Rozpoznávání objektů se týká souboru souvisejících úloh pro identifikaci objektů na digitálních fotografiích.
- Regionální konvoluční neuronové sítě neboli R-CNN je rodina technik pro řešení úloh lokalizace a rozpoznávání objektů, která je navržena pro modelový výkon.
- Jen jednou se podíváš neboli YOLO je druhá rodina technik pro rozpoznávání objektů, která je navržena pro rychlost a použití v reálném čase.
Máte nějaké dotazy?
Pokládejte je v komentářích níže a já se budu snažit odpovědět.
Vyvíjejte modely hlubokého učení pro vidění ještě dnes!

Vyvíjejte vlastní modely vidění během několika minut
…s pouhými několika řádky kódu v jazyce Python
Objevte, jak na to, v mé nové elektronické knize:
Hluboké učení pro počítačové vidění
Nabízí samostudijní návody na témata jako:
klasifikace, detekce objektů (yolo a rcnn), rozpoznávání tváří (vggface a facenet), příprava dat a mnoho dalšího….
Konečně zapojte hluboké učení do svých projektů v oblasti vidění
Vynechejte akademickou půdu. Stačí výsledky.
Podívejte se, co je uvnitř
.