
V článku „Anomaly Detection with Autoencoders Made Easy“ jsem se zmínil, že autoenkodéry se široce uplatňují při redukci rozměrů a redukci obrazového šumu. Od té doby se mě mnoho čtenářů ptalo, zda se mohu zabývat tématem redukce obrazového šumu pomocí autoenkodérů. To je motivací tohoto příspěvku.
Modelování obrazových dat vyžaduje ve světě neuronových sítí zvláštní přístup. Nejznámější neuronovou sítí pro modelování obrazových dat je konvoluční neuronová síť (CNN nebo ConvNet) nebo tzv. konvoluční autoenkodér. V tomto příspěvku začnu jemným úvodem pro obrazová data, protože ne všichni čtenáři se v oblasti obrazových dat pohybují (pokud jste již obeznámeni, klidně tuto část přeskočte). Poté popíšu jednoduchou standardní neuronovou síť pro obrazová data. To mi poskytne příležitost ukázat, proč jsou konvoluční autoenkodéry preferovanou metodou při práci s obrazovými daty. Především však ukážu, jak konvoluční autoenkodéry redukují šumy v obraze. V tomto příspěvku používám modul Keras a data MNIST. Zápisník je k dispozici prostřednictvím tohoto odkazu. Keras je vysokoúrovňové rozhraní API pro neuronové sítě napsané v jazyce Python a schopné běžet nad modulem TensorFlow. Tento příspěvek je rozšířením mého dřívějšího příspěvku „Co je to rozpoznávání obrazu?“, který vám doporučuji si přečíst.
Myslím, že je užitečné zmínit tři široké kategorie dat. Tyto tři kategorie dat jsou následující: (1) Nekorelovaná data (na rozdíl od sériových dat), (2) Sériová data (včetně textových a hlasových dat) a (3) Obrazová data. Hluboké učení má tři základní varianty řešení každé kategorie dat: (1) standardní dopředná neuronová síť, (2) RNN/LSTM a (3) konvoluční neuronová síť (CNN). Čtenářům, kteří hledají návody k jednotlivým typům, doporučujeme podívat se na články „Vysvětlení hlubokého učení přívětivým způsobem pro regresi“ pro (1), na aktuální článek „Technický průvodce pro RNN/LSTM/GRU na předpovídání cen akcií“ pro (2) a na články „Deep Learning with PyTorch Is Not Torturing“, „What Is Image Recognition?“, „Anomaly Detection with Autoencoders Made Easy“ a „Convolutional Autoencoders for Image Noise Reduction“ pro (3). Souhrnný článek „Dataman Learning Paths – Build Your Skills, Drive Your Career“ si můžete uložit do záložek.
Poznejte obrazová data
Obrázek se skládá z „pixelů“, jak ukazuje obrázek (A). V černobílém obrázku je každý pixel reprezentován číslem v rozmezí 0 až 255. Většina dnešních obrázků používá 24bitovou nebo vyšší barvu. Barevný obrázek RGB znamená, že barva v pixelu je kombinací červené, zelené a modré barvy, přičemž každá z těchto barev má rozsah od 0 do 255. Barevný systém RGB vytváří všechny barvy z kombinace červené, zelené a modré barvy, jak ukazuje tento generátor barev RGB. Pixel tedy obsahuje sadu tří hodnot RGB(102, 255, 102) a odkazuje na barvu #66ff66.

Obrázek široký 800 pixelů, vysoký 600 pixelů má 800 x 600 = 480 000 pixelů = 0,48 megapixelu („megapixel“ je 1 milion pixelů). Obrázek s rozlišením 1024 × 768 je mřížka s 1 024 sloupci a 768 řádky, která tedy obsahuje 1 024 × 768 = 0,78 megapixelu.
MNIST
Báze MNIST (Modifikovaná databáze Národního institutu pro standardy a technologie) je rozsáhlá databáze ručně psaných číslic, která se běžně používá pro trénování různých systémů zpracování obrazu. Tréninková datová sada v systému Keras má 60 000 záznamů a testovací datová sada má 10 000 záznamů. Každý záznam má rozměry 28 x 28 pixelů.
Jak vypadají? Pomocí matplotlib a jeho obrazové funkce imshow() zobrazíme prvních deset záznamů.

Skládá obrazová data pro trénování
Aby se nám hodil rámec neuronové sítě pro trénování modelu, můžeme všech 28 x 28 = 784 hodnot skládat do sloupce. Stohovaný sloupec pro první záznam vypadá takto: (s použitím x_train.reshape(1,784)):

Poté můžeme model trénovat pomocí standardní neuronové sítě, jak je znázorněno na obrázku (B). Každá ze 784 hodnot je uzlem ve vstupní vrstvě. Ale počkat, neztratili jsme při skládání dat mnoho informací? Ano. Prostorové a časové vztahy v obraze byly vyřazeny. To je velká ztráta informací. Podívejme se, jak mohou konvoluční autoenkodéry zachovat prostorové a časové informace.

Proč jsou konvoluční autoenkodéry vhodné pro obrazová data?
Při krájení a stohování dat vidíme obrovskou ztrátu informací. Konvoluční autoenkodéry namísto stohování dat zachovávají prostorové informace vstupních obrazových dat tak, jak jsou, a jemně extrahují informace v tzv. konvoluční vrstvě. Obrázek (D) ukazuje, že plochý 2D obraz je extrahován do tlustého čtverce (Conv1), pak pokračuje do dlouhé krychle (Conv2) a další delší krychle (Conv3). Tento proces je navržen tak, aby zachoval prostorové vztahy v datech. Jedná se o proces kódování v autoenkodéru. Uprostřed je plně propojený autoenkodér, jehož skrytá vrstva se skládá pouze z 10 neuronů. Poté přichází s procesem dekódování, který zplošťuje krychle, poté na 2D plochý obraz. Na obrázku (D) jsou kodér a dekodér symetrické. Nemusí být symetrické, ale většina praktiků právě toto pravidlo přejímá, jak je vysvětleno v článku „Anomaly Detection with Autoencoders made easy“.

Jak fungují konvoluční autoenkodéry?“
Výše uvedené získávání dat se zdá být kouzelné. Jak to doopravdy funguje? Zahrnuje následující tři vrstvy:

- Konvoluční vrstva
Krok konvoluce vytváří mnoho malých částí nazývaných mapy prvků nebo prvky, jako jsou zelené, červené nebo tmavě modré čtverce na obrázku (E). Tyto čtverce zachovávají vztahy mezi pixely ve vstupním obraze. Nechte každý rys prohledat původní obraz tak, jak je znázorněno na obrázku (F). Tento proces při vytváření skóre se nazývá filtrování.
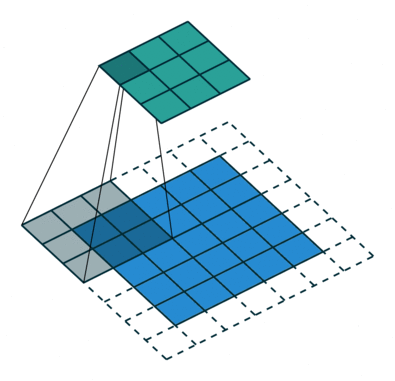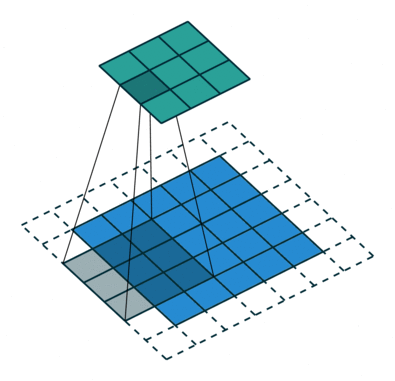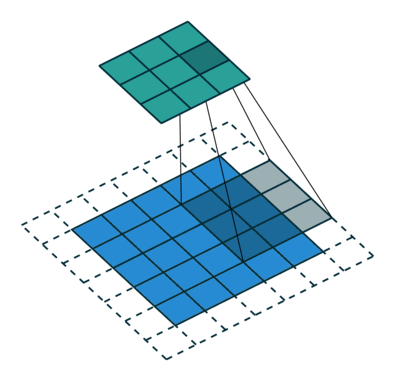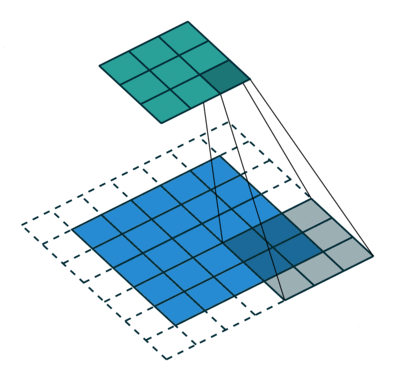
Po prohledání původního obrazu vytvoří každá funkce filtrovaný obraz s vysokým a nízkým skóre, jak je znázorněno na obrázku (G). Pokud existuje dokonalá shoda, je v daném čtverci vysoké skóre. Pokud je shoda nízká nebo žádná, je skóre nízké nebo nulové. Například červený čtverec našel v původním obrázku čtyři oblasti, které vykazují dokonalou shodu s daným prvkem, takže skóre těchto čtyř oblastí je vysoké.

Více filtrů znamená větší počet prvků, které může model extrahovat. Více rysů však znamená delší dobu trénování. Proto se doporučuje použít minimální počet filtrů pro extrakci rysů.
1.1 Padding
Jak se určuje shoda rysů? Jedním z hyperparametrů je Padding, který nabízí dvě možnosti: (i) vyplnění původního obrazu nulami, aby se přizpůsobil rysu, nebo (ii) vypuštění části původního obrazu, která se nehodí, a ponechání platné části.
1.2 Strides
Konvoluční vrstva obsahuje další parametr: Stride. Je to počet pixelů posouvajících se po vstupní matici. Když je stride 1, filtry se posouvají po 1 pixelu. V našem kódu Keras jej uvidíme jako hyperparametr.
2. Krok ReLUs
Rektifikovaná lineární jednotka (ReLU) je krok, který je stejný jako krok v typických neuronových sítích. Rektifikuje jakoukoli zápornou hodnotu na nulu, aby bylo zaručeno, že se matematika bude chovat správně.
3. Vrstva maximálního sdružování
Sdružování zmenšuje velikost obrazu. Na obrázku (H) okno 2 x 2, nazývané velikost poolu, prochází každý z filtrovaných obrázků a přiřazuje maximální hodnotu tohoto okna 2 x 2 čtverci 1 x 1 v novém obrázku. Jak je znázorněno na obrázku (H), maximální hodnota v prvním okně 2 x 2 je vysoké skóre (znázorněno červeně), takže vysoké skóre je přiřazeno čtverci 1 x 1.

Mezi další méně obvyklé metody sdružování patří sdružování podle maximální hodnoty (Average Pooling) nebo sdružování podle součtu (Sum Pooling).

Po sdružování se vytvoří nový zásobník menších filtrovaných snímků. Nyní rozdělíme menší filtrované obrázky a poskládáme je do seznamu, jak je znázorněno na obrázku (J)
Model v Keras
Výše uvedené tři vrstvy jsou stavebními kameny konvoluční neuronové sítě. Keras nabízí následující dvě funkce:
V konvolučních autoenkodérech můžete vytvořit mnoho konvolučních vrstev. Na obrázku (E) jsou v části kódování tři vrstvy označené Conv1, Conv2 a Conv3. Podle toho je tedy budeme budovat.
- Následující kód
input_img = Input(shape=(28,28,1)deklaruje, že vstupní 2D obrázek má rozměry 28 × 28. - Poté vybuduje tři vrstvy Conv1, Conv2 a Conv3.
- Všimněte si, že Conv1 je uvnitř Conv2 a Conv2 je uvnitř Conv3.
- Kód
paddingurčuje, co dělat, když filtr dobře neodpovídá vstupnímu obrázku.padding='valid'znamená vypuštění části obrazu, když se filtr nevejde;padding='same'doplní obraz nulami, aby se vešel do obrazu.
Pak pokračuje přidáním procesu dekódování. Takže v části decode níže je vše zakódováno a dekódováno.
Api Keras vyžaduje deklaraci modelu a optimalizační metody:
-
Model(inputs= input_img,outputs= decoded): Model bude obsahovat všechny vrstvy potřebné při výpočtu výstupůdecodeddaných vstupními datyinput_img.compile(optimizer='adadelta',loss='binary_crossentropy'): Optimalizátor provede optimalizaci stejně jako gradientní decentrální metoda. Nejběžnější jsou stochastický gradient decentrální (SGD), přizpůsobený gradient (Adagrad) a Adadelta, která je rozšířením Adagradu. Podrobnosti naleznete v dokumentaci k optimalizátoru Keras. Ztrátové funkce najdete v dokumentaci ke ztrátám Keras.
Níže trénuji model pomocí x_train jako vstupu i výstupu. batch_size je počet vzorků a epoch je počet iterací. Zadávám shuffle=True, abych vyžadoval zamíchání trénovacích dat před každou epochou.
Můžeme vypsat prvních deset původních obrázků a předpovědi pro stejných deset obrázků.
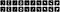
Jak sestavit konvoluční autoenkodér pro redukci šumu obrazu?“
Smyslem redukce šumu obrazu je natrénovat model, jehož vstupem jsou šumová data a výstupem jejich příslušná čistá data. To je jediný rozdíl oproti výše uvedenému modelu. Nejprve přidejme do dat šumy.
Prvních deset zašuměných obrázků vypadá následovně:

Poté natrénujeme model se zašuměnými daty jako vstupy a s čistými daty jako výstupy.
Nakonec vypíšeme prvních deset zašuměných obrázků a také odpovídající odšuměné obrázky.
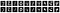
Zápisník je k dispozici prostřednictvím tohoto odkazu.
Existuje nějaký předtrénovaný kód CNN, který mohu použít?
Ano. Pokud máte zájem naučit se kód, Keras má několik předtrénovaných CNN, včetně Xception, VGG16, VGG19, ResNet50, InceptionV3, InceptionResNetV2, MobileNet, DenseNet, NASNet a MobileNetV2. Za zmínku stojí tato rozsáhlá obrazová databáze ImageNet, do které můžete přispět nebo si ji stáhnout pro výzkumné účely.
.