Toto je druhá část mého seriálu o doporučovacích systémech. Minulý příspěvek byl úvodem do RecSys. Dnes podrobněji vysvětlím tři typy kolaborativního filtrování: Kolaborativní filtrování založené na uživateli (UB-CF) a kolaborativní filtrování založené na položkách (IB-CF).
Začněme.
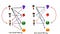
Představme si, že chceme našemu příteli Stanleymu doporučit film. Mohli bychom předpokládat, že podobní lidé budou mít podobný vkus. Předpokládejme, že jsme se Stanleym viděli stejné filmy a všechny jsme hodnotili téměř stejně. Ale Stanley neviděl „Kmotra“: Část II‘ a já ano. Pokud se mi ten film líbí, zní logicky, že se mu bude líbit také. Tím jsme vytvořili umělé hodnocení založené na naší podobnosti.
No, UB-CF používá tuto logiku a doporučuje položky tak, že najde uživatele podobné aktivnímu uživateli (kterému se snažíme doporučit film). Konkrétní aplikací tohoto postupu je algoritmus nejbližšího souseda na základě uživatele. Tento algoritmus potřebuje dvě úlohy:
1. Najít K nejbližších sousedů (KNN) k uživateli a pomocí funkce podobnosti w, která měří vzdálenost mezi jednotlivými dvojicemi uživatelů:

2.Předpovězte hodnocení, které uživatel a udělí všem položkám, které k sousedů spotřebovalo, ale a ne. Hledáme položku j s nejlepším předpovězeným hodnocením.
Jinými slovy, vytváříme matici uživatel-položka a předpovídáme hodnocení položek, které aktivní uživatel neviděl, na základě ostatních podobných uživatelů. Tato technika je založena na paměti.

PROS:
- Snadná implementace.
- Nezávislá na kontextu.
- V porovnání s jinými technikami, jako je například technika založená na obsahu, je přesnější.
PŘÍKLADY:
- Drobnost: Procento lidí, kteří hodnotí položky, je opravdu nízké.
- Škálovatelnost: Čím více K sousedů budeme brát v úvahu (pod určitou hranicí), tím lepší by měla být moje klasifikace. Nicméně čím více uživatelů bude v systému, tím větší budou náklady na nalezení nejbližších K sousedů.
- Studený start: Noví uživatelé nebudou mít žádné nebo jen málo informací o sobě, aby je bylo možné porovnat s ostatními uživateli.
- Nová položka:
Společné filtrování založené na položkách (IB-CF)
Zpět na Stanleyho: Stejně jako v minulém bodě budou nové položky postrádat hodnocení pro vytvoření solidního pořadí (více o tom v části „Jak třídit a řadit položky“). Místo toho, abychom se zaměřili na jeho přátele, mohli bychom se zaměřit na to, které položky ze všech možností jsou více podobné tomu, o čem víme, že ho baví. Toto nové zaměření se nazývá Item-Based Collaborative Filtering (IB-CF).
Mohli bychom IB-CF rozdělit na dvě dílčí úlohy:
1. Zjistěte, co je to IB-CF.Výpočet podobnosti mezi položkami:
- Podobnost založená na kosinu
- Podobnost založená na korelaci
- Podobnost upravená kosinem
- 1-Jaccardova vzdálenost
2.Výpočet predikce:
- Vážený součet
- Regrese
Rozdíl mezi UB-CF a touto metodou spočívá v tom, že v tomto případě přímo předpočítáme podobnost mezi společně hodnocenými položkami a vynecháme prohledávání K-okolí.
Slope One
Slope One je součástí rodiny Item-Based Collaborative Filtering, kterou v roce 2005 představili Daniel Lemire a Anna Maclachlan v článku Slope One Predictors for Online Rating-Based Collaborative Filtering.
Hlavní myšlenka tohoto modelu je následující:
Předpokládejme, že máme dva různé uživatele: Uživatel A ohodnotil položku I 1 hvězdičkou a položku J 1,5 hvězdičky. Pokud uživatel B ohodnotí položku I hvězdičkou 2. Můžeme předpokládat, že rozdíl mezi oběma položkami bude stejný jako u uživatele A. S ohledem na to by uživatel B ohodnotil položku J jako: 2+ (1,5-1) = 2,5

Autoři se zaměřili na 5 cílů:
1. Snadná implementace a údržba.
2. Možnost aktualizace online: nová hodnocení by měla rychle měnit předpovědi.
3. Efektivní v době konzultací: hlavním nákladem je úložiště.
4. Funguje s malou zpětnou vazbou od uživatelů.
5. Snadná implementace a údržba. Přiměřeně přesný, v určitých mezích, ve kterých malý nárůst přesnosti neznamená velkou oběť jednoduchosti a škálovatelnosti.
Recap
Viděli jsme kolaborativní filtrování založené na uživatelích a položkách. První se zaměřuje na vyplňování matice uživatel-položka a doporučování na základě uživatelů, kteří jsou aktivnímu uživateli podobnější. Na druhé straně IB-CF vyplňuje matici položka-položka a doporučuje na základě podobných položek.
Je těžké všechna tato témata stručně vysvětlit, ale jejich pochopení je prvním krokem k hlubšímu proniknutí do systému RecSys.