Kolmogorov-Smirnovova (KS) statistika je jednou z nejdůležitějších metrik používaných pro ověřování prediktivních modelů. Je široce používána v oblasti BFSI. Pokud jste součástí týmu rizikových nebo marketingových analytiků, který pracuje na projektu v bankovnictví, určitě jste o této metrice slyšeli.
Co je to KS statistika?
Je to zkratka Kolmogorov-Smirnov, která je pojmenována podle Andreje Kolmogorova a Nikolaje Smirnova. Porovnává dvě kumulativní rozdělení a vrací maximální rozdíl mezi nimi. Jedná se o neparametrický test, což znamená, že není třeba testovat žádný předpoklad týkající se rozdělení dat. V KS testu nulová hypotéza tvrdí, že obě kumulativní rozdělení jsou podobná. Zamítnutí nulové hypotézy znamená, že se kumulativní rozdělení liší.
V datové vědě porovnává kumulativní rozdělení událostí a ne-událostí a KS je tam, kde je mezi oběma rozděleními maximální rozdíl. Zjednodušeně řečeno nám pomáhá pochopit, jak dobře je náš predikční model schopen rozlišovat mezi událostmi a ne-událostmi.
Předpokládejme, že vytváříte propensity model, v němž je cílem identifikovat potenciální zákazníky, kteří si pravděpodobně koupí určitý produkt. V tomto případě je závislá (cílová) proměnná v binárním tvaru, která má pouze dva výsledky : 0 (neudálost) nebo 1 (událost). „Událost“ znamená lidi, kteří si produkt zakoupili. „Neudálost“ označuje lidi, kteří si výrobek nekoupili. Statistika KS měří, zda je model schopen rozlišit mezi potenciálními zákazníky a zákazníky, kteří nejsou potenciálními zákazníky.
Dva způsoby měření statistiky KS
Tato metoda je nejběžnějším způsobem výpočtu statistiky KS pro ověření binárního predikčního modelu. Viz níže uvedené kroky.
- Před výpočtem KS musíte mít dvě proměnné. Jednou je závislá proměnná, která by měla být binární. Druhou je skóre predikované pravděpodobnosti, které je generováno ze statistického modelu.
- Vytvořte decily na základě sloupců predikované pravděpodobnosti, což znamená rozdělení pravděpodobnosti na 10 částí. První decil by měl obsahovat nejvyšší skóre pravděpodobnosti.
- Vypočítejte kumulativní % událostí a neudálostí v každém decilu a poté vypočítejte rozdíl mezi těmito dvěma kumulativními rozděleními.
- KS je tam, kde je rozdíl maximální
- Pokud je KS v prvních 3 decilech a skóre vyšší než 40, je považován za dobrý predikční model. Zároveň je důležité ověřit model kontrolou i dalších ukazatelů výkonnosti, aby se potvrdilo, že model netrpí problémem přílišného přizpůsobení.
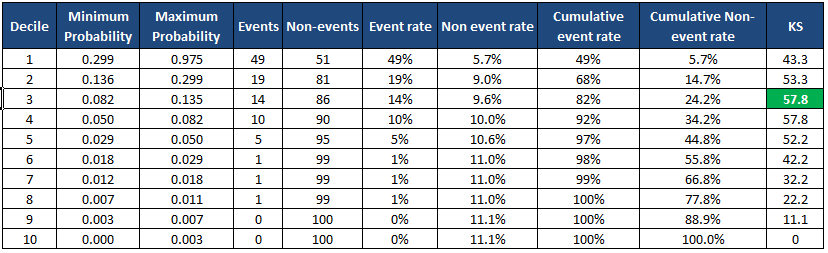
Python : KS Statistics Decile Method
Pro příklad jsem připravil ukázková data. Datová sada obsahuje dva sloupce nazvané y a p.yje závislá proměnná.podkazuje na predikovanou pravděpodobnost.
import pandas as pdimport numpy as npdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
def ks(data=None,target=None, prob=None): data = 1 - data data = pd.qcut(data, 10) grouped = data.groupby('bucket', as_index = False) kstable = pd.DataFrame() kstable = grouped.min() kstable = grouped.max() kstable = grouped.sum() kstable = grouped.sum() kstable = kstable.sort_values(by="min_prob", ascending=False).reset_index(drop = True) kstable = (kstable.events / data.sum()).apply('{0:.2%}'.format) kstable = (kstable.nonevents / data.sum()).apply('{0:.2%}'.format) kstable=(kstable.events / data.sum()).cumsum() kstable=(kstable.nonevents / data.sum()).cumsum() kstable = np.round(kstable-kstable, 3) * 100 #Formating kstable= kstable.apply('{0:.2%}'.format) kstable= kstable.apply('{0:.2%}'.format) kstable.index = range(1,11) kstable.index.rename('Decile', inplace=True) pd.set_option('display.max_columns', 9) print(kstable) #Display KS from colorama import Fore print(Fore.RED + "KS is " + str(max(kstable))+"%"+ " at decile " + str((kstable.index==max(kstable)]))) return(kstable)
mydf = ks(data=df,target="y", prob="p")
-
dataodkazuje na datový rámec pandas, který obsahuje závislou proměnnou i skóre pravděpodobnosti. -
targetodkazuje na název sloupce závislé proměnné -
probodkazuje na název sloupce predikované pravděpodobnosti
Vrátí informace o každém decilu v tabulkovém formátu a pod tabulku vypíše také KS skóre. Rovněž vygeneruje tabulku v novém datovém rámci.
min_prob max_prob events nonevents event_rate nonevent_rate \Decile 1 0.298894 0.975404 49 51 49.00% 5.67% 2 0.135598 0.298687 19 81 19.00% 9.00% 3 0.082170 0.135089 14 86 14.00% 9.56% 4 0.050369 0.082003 10 90 10.00% 10.00% 5 0.029415 0.050337 5 95 5.00% 10.56% 6 0.018343 0.029384 1 99 1.00% 11.00% 7 0.011504 0.018291 1 99 1.00% 11.00% 8 0.006976 0.011364 1 99 1.00% 11.00% 9 0.002929 0.006964 0 100 0.00% 11.11% 10 0.000073 0.002918 0 100 0.00% 11.11% cum_eventrate cum_noneventrate KS Decile 1 49.00% 5.67% 43.3 2 68.00% 14.67% 53.3 3 82.00% 24.22% 57.8 4 92.00% 34.22% 57.8 5 97.00% 44.78% 52.2 6 98.00% 55.78% 42.2 7 99.00% 66.78% 32.2 8 100.00% 77.78% 22.2 9 100.00% 88.89% 11.1 10 100.00% 100.00% 0.0 KS is 57.8% at decile 3
Pomocí knihovnyscipypython můžeme vypočítat dvouvýběrovou KS statistiku. Má dva parametry – data1 a data2. Do data1 zadáme všechna skóre pravděpodobnosti odpovídající neudálostem. V data2 bude brát skóre pravděpodobnosti odpovídající událostem.
from scipy.stats import ks_2sampdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")ks_2samp(df.loc, df.loc)
Vrátí KS skóre 0,6033 a p-hodnotu menší než 0,01, což znamená, že můžeme zamítnout nulovou hypotézu a dojít k závěru, že rozdělení událostí a ne-událostí se liší.
OutputKs_2sampResult(statistic=0.6033333333333333, pvalue=1.1227180680661939e-29)
Skóre KS metody 2 se mírně liší od metody 1, protože druhé se počítá na úrovni řádku a první se počítá po převedení dat na deset částí.