Kolmogorov-Smirnov (KS) -tilasto on yksi tärkeimmistä mittareista, joita käytetään ennustemallien validointiin. Sitä käytetään laajalti BFSI-alalla. Jos kuulut riski- tai markkinointianalytiikkatiimiin, joka työskentelee projektin parissa pankkialalla, olet varmasti kuullut tästä metriikasta.
Mikä on KS-tilasto?
Se on lyhenne sanoista Kolmogorov-Smirnov, joka on nimetty Andrei Kolmogorovin ja Nikolai Smirnovin mukaan. Se vertaa kahta kumulatiivista jakaumaa ja palauttaa niiden välisen suurimman eron. Se on ei-parametrinen testi, mikä tarkoittaa, että sinun ei tarvitse testata mitään tietojen jakaumaan liittyviä oletuksia. KS-testissä nollahypoteesin mukaan molemmat kumulatiiviset jakaumat ovat samanlaisia. Nollahypoteesin hylkääminen tarkoittaa, että kumulatiiviset jakaumat ovat erilaisia.
Datatieteessä sillä verrataan tapahtumien ja ei-tapahtumien kumulatiivista jakaumaa ja KS-testillä saadaan suurin ero näiden kahden jakauman välillä. Yksinkertaisesti sanottuna se auttaa meitä ymmärtämään, kuinka hyvin ennustava mallimme kykenee erottamaan tapahtumat ja ei-tapahtumat.
Es oletetaan, että olet rakentamassa taipumusmallia, jossa tavoitteena on tunnistaa potentiaaliset asiakkaat, jotka todennäköisesti ostavat tietyn tuotteen. Tässä tapauksessa riippuvainen (tavoite)muuttuja on binäärimuodossa, jolla on vain kaksi tulosta: 0 (ei-tapahtuma) tai 1 (tapahtuma). ”Tapahtuma” tarkoittaa ihmisiä, jotka ovat ostaneet tuotteen. ”Ei-tapahtuma” tarkoittaa ihmisiä, jotka eivät ostaneet tuotetta. KS-tilasto mittaa, pystyykö malli erottamaan potentiaaliset ja ei-positiiviset asiakkaat toisistaan.
Kaksi tapaa mitata KS-statistiikkaa
Tämä menetelmä on yleisin tapa laskea KS-statistiikka binäärisen ennustemallin validointia varten. Katso alla olevat vaiheet.
- Tarvitaan kaksi muuttujaa ennen KS:n laskemista. Toinen on riippuvainen muuttuja, jonka tulee olla binäärinen. Toinen on ennustettu todennäköisyyspistemäärä, joka luodaan tilastollisesta mallista.
- Luo desiilit ennustetun todennäköisyyden sarakkeiden perusteella, mikä tarkoittaa todennäköisyyden jakamista 10 osaan. Ensimmäisen desiilin tulisi sisältää korkein todennäköisyyspistemäärä.
- Lasketaan tapahtumien ja ei-tapahtumien kumulatiivinen prosenttiosuus kussakin desiilissä ja lasketaan näiden kahden kumulatiivisen jakauman välinen ero.
- KS on se, jossa ero on suurin.
- Jos KS on kolmessa ylimmässä desiilissä ja pistemäärä on yli 40, sitä pidetään hyvänä ennustemallina. Samalla on tärkeää validoida malli tarkistamalla myös muita suorituskykymittareita, jotta voidaan varmistaa, ettei malli kärsi ylisovitusongelmasta.
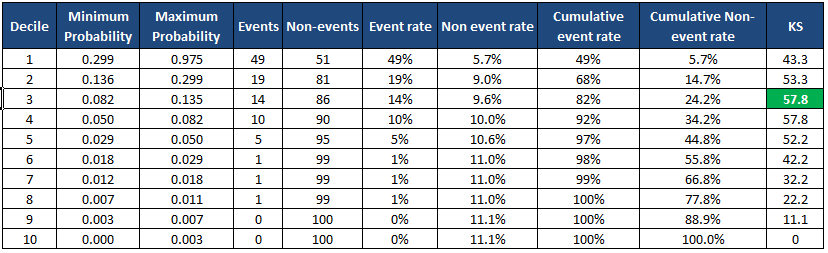
Python : KS-tilastojen desiilimenetelmä
Olen laatinut esimerkkidatan. Aineisto sisältää kaksi saraketta nimeltä y ja p.yon riippuvainen muuttuja.pviittaa ennustettuun todennäköisyyteen.
import pandas as pdimport numpy as npdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
def ks(data=None,target=None, prob=None): data = 1 - data data = pd.qcut(data, 10) grouped = data.groupby('bucket', as_index = False) kstable = pd.DataFrame() kstable = grouped.min() kstable = grouped.max() kstable = grouped.sum() kstable = grouped.sum() kstable = kstable.sort_values(by="min_prob", ascending=False).reset_index(drop = True) kstable = (kstable.events / data.sum()).apply('{0:.2%}'.format) kstable = (kstable.nonevents / data.sum()).apply('{0:.2%}'.format) kstable=(kstable.events / data.sum()).cumsum() kstable=(kstable.nonevents / data.sum()).cumsum() kstable = np.round(kstable-kstable, 3) * 100 #Formating kstable= kstable.apply('{0:.2%}'.format) kstable= kstable.apply('{0:.2%}'.format) kstable.index = range(1,11) kstable.index.rename('Decile', inplace=True) pd.set_option('display.max_columns', 9) print(kstable) #Display KS from colorama import Fore print(Fore.RED + "KS is " + str(max(kstable))+"%"+ " at decile " + str((kstable.index==max(kstable)]))) return(kstable)
mydf = ks(data=df,target="y", prob="p")
-
dataviittaa pandas dataframeen, joka sisältää sekä riippuvaisen muuttujan että todennäköisyyspisteet. -
targetviittaa riippuvan muuttujan sarakkeen nimeen -
probviittaa ennustetun todennäköisyyden sarakkeen nimeen
Se palauttaa kunkin desiilin tiedot taulukkomuodossa ja tulostaa myös KS-pistemäärän taulukon alle. Se luo myös taulukon uuteen datakehykseen.
min_prob max_prob events nonevents event_rate nonevent_rate \Decile 1 0.298894 0.975404 49 51 49.00% 5.67% 2 0.135598 0.298687 19 81 19.00% 9.00% 3 0.082170 0.135089 14 86 14.00% 9.56% 4 0.050369 0.082003 10 90 10.00% 10.00% 5 0.029415 0.050337 5 95 5.00% 10.56% 6 0.018343 0.029384 1 99 1.00% 11.00% 7 0.011504 0.018291 1 99 1.00% 11.00% 8 0.006976 0.011364 1 99 1.00% 11.00% 9 0.002929 0.006964 0 100 0.00% 11.11% 10 0.000073 0.002918 0 100 0.00% 11.11% cum_eventrate cum_noneventrate KS Decile 1 49.00% 5.67% 43.3 2 68.00% 14.67% 53.3 3 82.00% 24.22% 57.8 4 92.00% 34.22% 57.8 5 97.00% 44.78% 52.2 6 98.00% 55.78% 42.2 7 99.00% 66.78% 32.2 8 100.00% 77.78% 22.2 9 100.00% 88.89% 11.1 10 100.00% 100.00% 0.0 KS is 57.8% at decile 3
Käyttämälläscipypython-kirjastoa voimme laskea kahden otoksen KS-statistiikan. Sillä on kaksi parametria – data1 ja data2. Data1:een syötetään kaikki todennäköisyyspisteet, jotka vastaavat ei-tapahtumia. Data2:ssa se ottaa tapahtumia vastaavat todennäköisyyspisteet.
from scipy.stats import ks_2sampdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")ks_2samp(df.loc, df.loc)
Se palauttaa KS-pistemäärän 0.6033 ja p-arvon alle 0.01, mikä tarkoittaa, että voimme hylätä nollahypoteesin ja päätellä, että tapahtumien ja ei-tapahtumien jakauma on erilainen.
OutputKs_2sampResult(statistic=0.6033333333333333, pvalue=1.1227180680661939e-29)
Menetelmän 2 KS-pistemäärä poikkeaa hiukan menetelmästä 1, sillä jälkimmäinen on laskettu rivitasolla, ja ensimmäinen on laskettu sen jälkeen, kun aineisto on konvertoitu kymmeneen osaan.