La SRT a peu d’influence sur la capacité globale de reconnaissance des mots. Bien qu’il semble y avoir une hypothèse de travail ou une approche dans notre domaine (et même au sein de la communauté des chercheurs) pour utiliser le point de données de 50% pour prédire la performance maximale de traitement de la parole, il s’agit en fait d’un effort sans aucun fondement clinique ou théorique.
Est-il possible d’utiliser le seuil de reconnaissance de la parole (SRT) comme une mesure prédictive du score de reconnaissance des mots (WRS) d’un individu ? Au cours du processus de sélection d’une aide auditive, une décision doit être prise entre deux aides auditives ou entre les réglages de performance d’une seule aide auditive. Un réglage de performance donne un SRT meilleur que l’autre. Quels sont les principaux facteurs qui sous-tendent une décision clinique et qui pèsent dans l’équation des audioprothésistes d’aujourd’hui ? Lorsqu’un appareil est capable de fournir un meilleur TRS à un niveau de présentation du signal plus faible ou à un meilleur rapport signal/bruit (SNR, ou rapport S/N) par rapport à d’autres appareils, qu’est-ce que le professionnel doit attendre d’un appareil qui a un meilleur TRS ? Choisirons-nous ce dispositif parce qu’il conduirait, comme prévu dans notre jugement professionnel, à de meilleures performances de compréhension de la parole dans le monde réel ?
Lorsqu’on constate qu’un appareil auditif numérique doté d’un système directionnel est associé à des TRS légèrement meilleurs en termes de SNR, beaucoup d’entre nous choisiraient cet appareil auditif et s’attendraient à voir de meilleurs scores d’intelligibilité de la parole lorsque le système directionnel s’enclenche. De même, lorsqu’un dispositif d’aide à l’écoute (DAE), tel qu’un système FM, présente un avantage légèrement supérieur en termes de TRS par rapport à d’autres dispositifs, de nombreux cliniciens auraient également tendance à faire une déduction raisonnable que le DAE va produire des performances supérieures en matière de compréhension de la parole.1
En fait, la littérature a même essayé de prédire les performances de compréhension de la parole des sujets à partir du seuil de reconnaissance des phrases, en se basant sur la pente de la courbe de la fonction Performance-Intensité (P-I) à partir de laquelle le seuil de reconnaissance des phrases a été obtenu. Pour ne citer qu’un exemple, nous pouvons lire dans la littérature que, selon le manuel de test, une différence de 1 dB du rapport S/N équivaut à 9 points de pourcentage dans l’intelligibilité des phrases. Ainsi, une différence de 4 dB dans le rapport S/N entre les groupes implique des scores d’intelligibilité de la parole environ 36% plus faibles chez les locuteurs natifs bilingues que chez les monolingues.
Evidemment, l’hypothèse sous-jacente de toutes ces approches est que l’on peut faire une prédiction ou une estimation de la performance d’intelligibilité de la parole d’un individu à partir du SRT. Cependant, cette approche largement acceptée est-elle suffisamment précise pour une utilisation clinique ? Peut-on réellement être capable d’estimer ou de prédire le score de compréhension de la parole d’un utilisateur d’appareil auditif simplement à partir de ce point de 50 % ?
Considérations théoriques
Comme le seuil de tonalité pure (PT), qui est le niveau le plus doux auquel le signal de tonalité pure est à peine perceptible 50 % du temps, le seuil de reconnaissance de la parole (SRT) est le niveau de seuil auquel le signal de parole est à peine reconnaissable 50 % du temps3-5. Une fois encore, comme le seuil de tonalité pure qui représente la sensibilité auditive d’une personne aux signaux de tonalité pure, le SRT représente la sensibilité auditive d’une personne aux signaux de parole. Par définition et en raison de la nature de la procédure de test pour la détermination du seuil, le TRS indique une réponse de l’individu au signal vocal au niveau du seuil. Il s’agit d’une nuance importante : Le TRS indique la réponse aux signaux vocaux lorsque le signal vocal est présenté à un niveau assez faible, de sorte qu’il est tout juste presque perceptible/reconnaissable pendant environ 50 % du temps. Puisque le signal de parole est à ce niveau à peine reconnaissable et que la conjecture est naturellement impliquée pendant le test, le SRT est la réponse de niveau de seuil, se distinguant de la réponse de niveau supraliminaire de l’individu.
D’autre part, le score de reconnaissance des mots (WRS) représente toutes les réponses possibles lorsque le signal de parole est présenté à différents niveaux d’intensité sonore au-dessus du seuil des individus.3-5 Le WRS montre à quel point le patient peut entendre et traiter les signaux de parole à différents niveaux supra-seuil ; en revanche, le SRT indique à quel point la personne est sensible à l’audition des signaux de parole à des niveaux spécifiques à peine perceptibles. Par conséquent, par rapport au tracé de toutes les réponses possibles du WRS en fonction des niveaux de présentation du signal, le SRT est connu dans le domaine comme le point à 50% de la courbe Performance-Intensité. Le point à retenir ici est que le SRT est la réponse au niveau du seuil alors que le WRS est la réponse au niveau supra-seuil aux stimuli vocaux ; en aucun cas le SRT n’indique ou ne fait allusion à des réponses supra-seuil.
Examen du SRT et du WRS pour différents types de perte auditive
Pour illustrer ce qui précède, la figure 1 montre quatre SRT hypothétiques affichés comme quatre points de données en fonction du WRS (par rapport aux niveaux de présentation du signal vocal). Les quatre points de données représentent le niveau de signal le plus faible auquel le signal vocal est à peine perceptible 50 % du temps pour les personnes ayant une sensibilité auditive normale et différents degrés de perte auditive d’environ 50 dB, 70 dB et 90 dB HL. Les quatre points de données indiquent également que la performance de reconnaissance des mots est de 50% puisque les individus des quatre types d’état auditif ne peuvent reconnaître les signaux vocaux qu’avec une précision de 50% lorsque les signaux vocaux sont présentés à leurs niveaux de seuil, respectivement.
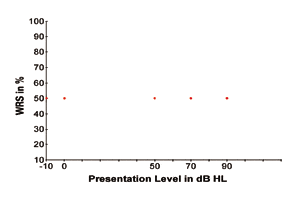 FIGURE 1. Quatre seuils hypothétiques de reconnaissance de la parole (SRT) affichés sous forme de quatre points de données pour une audition normale et divers degrés de perte auditive.
FIGURE 1. Quatre seuils hypothétiques de reconnaissance de la parole (SRT) affichés sous forme de quatre points de données pour une audition normale et divers degrés de perte auditive.
Dès lors, à quoi ressemblerait la courbe performance-intensité lorsque les signaux vocaux sont présentés à leurs niveaux supraliminaires ? Sur la base de ces quatre points de données, pouvons-nous estimer leurs scores maximaux de reconnaissance des mots lorsque les signaux vocaux sont présentés à divers niveaux supérieurs ? De même, si ces quatre points de données représentent les TRS avec une prothèse auditive adaptée en cours d’utilisation, sommes-nous en mesure de prédire le score maximal d’intelligibilité de la parole d’un sujet après avoir reçu le bénéfice d’une prothèse auditive ?
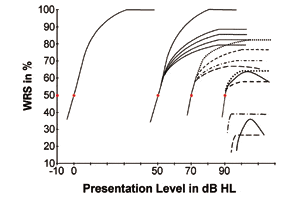 FIGURE 2. Courbes hypothétiques Performance-Intensité affichant divers scores maximaux de reconnaissance des mots (axe des ordonnées) pour les quatre seuils hypothétiques de reconnaissance de la parole (SRT), comme indiqué dans la figure 1qui représente le niveau de présentation dans lequel la parole est à peine reconnaissable 50 % du temps. Il convient de noter que les courbes présentées ici ne représentent qu’une partie limitée de la famille de toutes les performances de traitement de la parole possibles avec les différents degrés de perte auditive.
FIGURE 2. Courbes hypothétiques Performance-Intensité affichant divers scores maximaux de reconnaissance des mots (axe des ordonnées) pour les quatre seuils hypothétiques de reconnaissance de la parole (SRT), comme indiqué dans la figure 1qui représente le niveau de présentation dans lequel la parole est à peine reconnaissable 50 % du temps. Il convient de noter que les courbes présentées ici ne représentent qu’une partie limitée de la famille de toutes les performances de traitement de la parole possibles avec les différents degrés de perte auditive.
La figure 2 peut servir à répondre à ces questions. Sur la base d’expériences cliniques et de considérations théoriques, des exemples de certaines courbes hypothétiques Performance-Intensité (P-I) ont été tracées pour démontrer l’interrelation et le modèle de réponse des scores de reconnaissance des mots des sujets pour les individus ayant un statut d’audition normale et divers degrés de pertes auditives.
Pour un statut d’audition normale. Dans la figure 2, la courbe située à l’extrême gauche (par exemple, passant le niveau de présentation de 0 dB) peut être utilisée comme la courbe représentant les individus ayant une audition normale. C’est celle que l’on voit fréquemment dans les manuels indiquant que la performance augmente avec l’augmentation du niveau de présentation du signal avec une pente fixe, si elle est mesurée avec une procédure de test fixe et un matériel de test de la parole donné. La performance atteint le SRT maximum à environ 40 dB de niveau de sensation (SL) au-dessus du SRT.
Pour des pertes auditives de 50 dB. Dans la figure 2, à droite de la courbe des individus normo-entendants, un groupe de courbes passant par le niveau de présentation de 50 dB représente les réponses typiques sur le SRT pour la catégorie d’auditeurs ayant une perte auditive de 50 dB. Parmi cette catégorie de perte auditive de 50 dB (5 courbes en trait plein), la courbe de gauche montre la fonction P-I lorsque la perte auditive de 50 dB est une perte auditive de nature conductive. On notera que la courbe présente exactement la même pente et atteint le même WRS maximal que celle des sujets normo-entendants car la surdité de transmission est, par nature, une perte de sensibilité n’impliquant aucune pathologie de l’oreille interne et des structures supérieures.
Lorsque la perte auditive de 50 dB implique une perte auditive mixte par nature (par exemple, une légère composante de perte auditive neurosensorielle), alors la capacité de traitement du signal des sujets est réduite. Leurs courbes P-I (les 4 autres courbes pleines dans ce groupe de courbes) pourraient encore monter, mais avec une pente plus raide et s’aplatir à un SRW maximum plus faible, par rapport à la courbe des sujets normo-entendants ou de la perte auditive conductive.
D’après cette catégorie de perte auditive de 50 dB, on peut voir que toutes les courbes montrent le même SRT mais avec une grande différence individuelle dans le SRM maximum allant éventuellement de près de 70% à 100%.
Pour les pertes auditives de 70 dB. Plus à droite sur la figure 2, il y a 4 courbes en pointillés passant par le point de données SRT de 70 dB, culminant un SRT maximum différent. Elles représentent les modèles de réponse possibles et les différences individuelles sur la fonction P-I pour la catégorie de perte auditive de 70 dB. La catégorie de perte auditive autour de 70 dB SRT est généralement la majorité de la population de clients rencontrés dans la clinique d’aide auditive typique.
Il devrait être immédiatement évident que de plus grandes variations dans le SRT maximal, comme le montre la figure 2, peuvent résulter de ce type de perte. Il est également intéressant de noter que certaines courbes en pointillés atteignent une performance WRS supérieure à celles de la catégorie de perte auditive de 50 dB, tandis que d’autres montrent une performance qui est, en général, inférieure. Une courbe (la courbe en pointillés du bas) montre un petit degré de phénomène de renversement : un SRM plus faible à des niveaux de présentation plus élevés une fois que le SRM le plus élevé est atteint.
La grande quantité de variation individuelle révélée par les courbes P-I est souvent liée à une perte auditive neurosensorielle (SNHL) avec une pathologie des cellules ciliées et des fibres neurales impliquée. Ces pertes se caractérisent souvent par une perte de sensibilité et une perte de clarté, la perte de clarté des signaux vocaux variant considérablement en fonction de facteurs tels que, mais sans s’y limiter, le degré de la perte auditive, la forme de la perte auditive, l’étiologie de la perte auditive, l’état pathologique de la structure oreille-cerveau, l’étendue des dommages causés aux cellules ciliées externes et/ou aux cellules ciliées internes, les dommages et les effets sur l’amplification cochléaire active, la fonction résiduelle des cellules ciliées internes, l’endommagement des fibres nerveuses rétrocochléaires, l’effet sur la synchronisation des décharges neuronales, la proportion de lésions rétrocochléaires par rapport aux lésions cochléaires, l’effet de la réorganisation tonotopique du cortex auditif, la durée de la perte auditive, l’historique de l’utilisation d’appareils auditifs, le temps associé à une stimulation auditive (in)adéquate, les cas prélinguaux par rapport aux cas postlinguaux, le style de vie et le cadre de vie, et les capacités linguistiques de l’individu (voir l’encadré, Existe-t-il une perte auditive typique de 70 dB ?).
Il est clair qu’une myriade de facteurs, tels que discutés dans l’encadré, y compris ceux des domaines pathologiques et linguistiques, interagissent les uns avec les autres en tant que mécanismes sous-jacents influençant les performances du traitement du signal vocal. Par conséquent, de grandes différences individuelles sur le modèle de réponse du traitement du signal vocal, la pente de la courbe P-I, et le WRS maximum, devraient être raisonnablement attendues parmi les sujets. Pour la catégorie de perte auditive de 70dB de SNHL, ce qui est affiché dans la figure 2 n’est qu’une partie des fonctions P-I possibles avec différents WRS maximaux atteints tous avec un même SRT.
Par conséquent, la figure 2 et le bon sens suggèrent que prédire le SRT maximum possible à partir du SRT est une approche téméraire sans mises en garde appropriées.
Pour les pertes auditives de 90 dB. Lorsque le degré de perte auditive passe à la catégorie des pertes auditives de 90 dB, le SNHL devrait normalement impliquer la composante neuronale pour compléter la composante sensorielle, produisant des pertes beaucoup plus importantes de la clarté du signal ainsi qu’une perte de sensibilité. Ces types de pertes suggèrent des dommages plus importants dans la région rétrocochléaire et d’autres stations relais neurales le long des voies auditives supérieures. Ainsi, des déficiences neurologiques plus importantes sur les voies supérieures, avec une plus grande probabilité de dys-synchronie des décharges neurales et de troubles du traitement auditif, peuvent devenir une possibilité et révéler des performances de traitement du signal encore plus faibles (par rapport à la catégorie de perte auditive de 70 dB). Tous les facteurs discutés ci-dessus, tels que le degré réel de la perte auditive à travers les fréquences, l’étiologie particulière, l’emplacement et la gravité des dommages dans l’oreille interne et les voies auditives, la réorganisation tonotopique, les capacités linguistiques individuelles, etc. pourraient interagir les uns avec les autres et entraîner des modèles de réponse et des pentes de la courbe P-I différents. Là encore, de grandes variations dans les performances maximales de traitement du signal vocal seraient attendues.
Dans la figure 2, trois courbes (deux courbes en pointillés et une courbe en trait plein passant par le point de données de 90 dB) ont été tracées pour montrer des pentes variables avec divers SRT maximum qui peuvent être atteints par les individus dans cette catégorie de perte auditive. La courbe en trait plein montre un phénomène de roll-over encore plus important par rapport à celui de la catégorie de perte auditive de 70 dB. Ces trois courbes sont placées de manière à montrer que leur WRS maximal est susceptible d’être inférieur à celui de la catégorie de perte auditive de 70 dB.
Bien sûr, nous savons que certains sujets ayant une perte auditive d’environ 90 dB présenteraient un WRS extrêmement et exceptionnellement bon par rapport à ceux ayant une perte auditive même légère. Ce type d’exception n’est pas tout à fait rare ; il confirme la grande variabilité des fonctions de performance du traitement du signal et du système auditif. Le point unique de discussion ici est que toutes ces courbes passent par le même point de données SRT de 90 dB et donnent un WRS maximum radicalement différent. Comme pour le groupe de perte de 70 dB, il existe de grandes différences individuelles.
Dans le coin inférieur droit de la figure 2, trois autres courbes sont affichées, montrant quelques courbes P-I possibles pour les personnes ayant une perte auditive supérieure à 90 dB HL. Avec ce degré profond de perte auditive et les facteurs de confusion (comme discuté ci-dessus), de grandes différences individuelles dans la pente de la courbe de réponse et le WRS maximum devraient être anticipées.
La singularité de ces trois courbes est que la performance ascendante de reconnaissance vocale des sujets peut même ne pas être en mesure d’atteindre le point de 50%. De plus, le SRM maximum et le phénomène de renversement peuvent être encore plus faibles ou plus prononcés, respectivement, que les pertes de 70 dB.
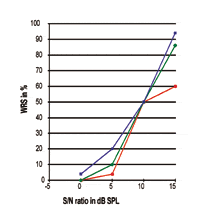 FIGURE 3. Trois courbes individuelles Performance-Intensité exprimées en rapport S/N. Notez que le point de 50 % est exactement à 10 dB SPL alors que la pente et les performances maximales de traitement de la parole sont clairement différentes.
FIGURE 3. Trois courbes individuelles Performance-Intensité exprimées en rapport S/N. Notez que le point de 50 % est exactement à 10 dB SPL alors que la pente et les performances maximales de traitement de la parole sont clairement différentes.
Preuves cliniques
Certaines données cliniques empiriques peuvent être utiles pour démontrer ce qui précède. Dans le but d’étudier l’effet du seuil de compression sur l’intelligibilité de la parole, 12 sujets présentant une LNH légère à sévère supérieure à 2 kHz ont écouté les phrases cibles du test Speech In Noise (SIN) à l’aide d’une aide auditive programmable. Des exemples de la performance de traitement de la parole de ces sujets ont été sélectionnés et tracés sous forme de courbes P-I par rapport au SNR (figures 3-6).
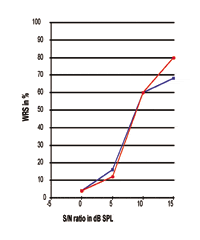 FIGURE 4. Deux courbes individuelles de performance-intensité exprimées en rapport S/N. Notez que le point de 50% se situe autour de 9,06 dB SPL alors que la pente et les performances maximales de traitement de la parole sont clairement différentes.
FIGURE 4. Deux courbes individuelles de performance-intensité exprimées en rapport S/N. Notez que le point de 50% se situe autour de 9,06 dB SPL alors que la pente et les performances maximales de traitement de la parole sont clairement différentes.
En se référant aux figures 3-5, il est clair que les performances du SRT de différents sujets peuvent être exactement les mêmes au point de 50%, alors que la pente de la courbe et les performances maximales sont complètement différentes les unes des autres. Toutes ces courbes montrent que le SRT n’est, en effet, que le point de données à 50 % le long de la courbe de réponse ; de grandes différences concernant la pente de la courbe et la performance maximale de traitement existent dans le monde réel. Les chiffres indiquent que le point de données de 50 % n’a pas de relation étroite avec la performance de traitement maximale qui serait accomplie par les individus. Ainsi, le SRT ne devrait pas être utilisé comme étant représentatif des réponses d’intensité de performance.
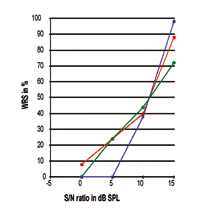 FIGURE 5. Trois courbes d’intensité de performance individuelle exprimées en rapport S/N. Notez que le point de 50% se situe autour de 10,75 dB SPL alors que la pente et les performances maximales de traitement de la parole sont clairement différentes.
FIGURE 5. Trois courbes d’intensité de performance individuelle exprimées en rapport S/N. Notez que le point de 50% se situe autour de 10,75 dB SPL alors que la pente et les performances maximales de traitement de la parole sont clairement différentes.
Ces informations suggèrent également que, lors du conseil aux étudiants diplômés et de la formulation de projets de recherche, il peut ne pas être judicieux d’utiliser le SRT comme critère principal de l’étude. Bien que de nombreux tests soient maintenant conçus pour trouver le point de 50% de la performance de traitement de la parole des sujets, l’interprétation du point de 50% ou du SRT, exprimé en termes de niveau de présentation ou de SNR, doit être faite avec prudence. La performance du traitement de la parole est un phénomène plus complexe.
Dans la figure 6, les trois courbes P-I individuelles ont un point de 50% totalement différent. La courbe rouge représente un individu présentant une LNH haute fréquence légère, tandis que les deux autres courbes ont été obtenues chez des individus présentant une LNH haute fréquence modérée à sévère. En fait, la forte pente et les performances de traitement de la parole quasi parfaites démontrées par la courbe rouge sont similaires aux réponses obtenues par des sujets normo-entendants.
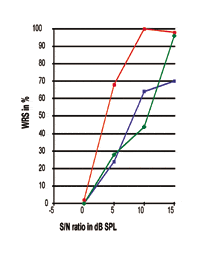 FIGURE 6. Trois courbes individuelles d’intensité de performance avec leurs points de 50% à 3,35, 8,51 et 9,83 dB SPL respectivement. La courbe rouge avec le cercle rempli, dont la pente et la performance maximale de traitement de la parole sont similaires à celles atteintes par des sujets normo-entendants, est accomplie par un individu avec une perte auditive neurosensorielle légère dans les hautes fréquences, tandis que les deux autres courbes sont obtenues à partir d’individus avec une perte auditive neurosensorielle modérée à sévère dans les hautes fréquences.
FIGURE 6. Trois courbes individuelles d’intensité de performance avec leurs points de 50% à 3,35, 8,51 et 9,83 dB SPL respectivement. La courbe rouge avec le cercle rempli, dont la pente et la performance maximale de traitement de la parole sont similaires à celles atteintes par des sujets normo-entendants, est accomplie par un individu avec une perte auditive neurosensorielle légère dans les hautes fréquences, tandis que les deux autres courbes sont obtenues à partir d’individus avec une perte auditive neurosensorielle modérée à sévère dans les hautes fréquences.
Cela pourrait être attendu, puisque les sujets avec une perte auditive neurosensorielle légère peuvent souffrir de moins de dommages dans le système oreille-cerveau. Pour les courbes obtenues à partir de personnes souffrant de SNHL haute fréquence modérée à sévère, des degrés plus importants de différences individuelles peuvent être observés, comme discuté précédemment. En observant ces deux courbes, notez que celle qui présente le meilleur point à 50% (courbe bleue), comparée à la courbe verte, ne donne pas un meilleur WRS. Cela indique que, dans le monde réel où des variations individuelles existent, un meilleur point de 50% (SRT) n’est pas toujours associé à une meilleure performance maximale de traitement de la parole.
Sommaire
1) Les performances de traitement de la parole d’un individu sont dynamiquement affectées par un certain nombre de facteurs, notamment le degré, le type, la forme de la perte auditive, la durée de la perte auditive, et de nombreuses autres conditions physiopathologiques dans le système oreille-cerveau et même la capacité/le profil linguistique des individus.
2) Le seuil de reconnaissance vocale est juste le point de données à 50% sur la courbe P-I de la performance de traitement de la parole des sujets.
3) Le point de données de 50% (SRT) d’un individu sur la courbe P-I pourrait être à l’unité avec un autre patient, mais la pente et la performance de traitement de ces deux patients pourraient être complètement différentes l’une de l’autre.
4) La relation entre le schéma de réponse, le SRT, la pente de la courbe P-I et la performance maximale de traitement est extrêmement dynamique et imprévisible en raison de la variabilité individuelle.
5) Une réponse avec un meilleur SRT n’est pas nécessairement associée à un meilleur WRS. Bien qu’il semble souvent y avoir une hypothèse/approche de travail dans notre domaine pour utiliser le point de données de 50% pour prédire la performance maximale de traitement de la parole, c’est en fait un effort sans fondement clinique/théorique et sans précision.
6) Lors de l’adaptation d’une aide auditive ou d’une ALD, comme la sélection, la modification et le réglage fin, ou lors de l’établissement d’attentes réalistes pour les avantages de l’amplification, il ne faut pas trop se fier au point de données de 50%. Au lieu de cela, l’obtention d’une courbe P-I plus complète avec des performances maximales de traitement de la parole est une approche plus pragmatique pour le clinicien du monde réel.
Est-ce qu’il existe une perte auditive typique de 70 dB ?
Il est évident que les pertes auditives plus sévères peuvent entraîner des variations assez remarquables du WRS. Les pertes auditives supérieures à 70 dB sont souvent complexes et à facettes multiples. Par exemple, les patients ayant un score SRT de 70 dB peuvent avoir des seuils de sons purs totalement différents selon les fréquences. En d’autres termes, les patients peuvent présenter des pertes auditives de différentes ampleurs à des fréquences discrètes de sons purs, mais tous peuvent sembler avoir un SRT d’environ 70 dB HL. Les individus peuvent également présenter différentes formes d’audiogrammes, y compris une perte auditive plate, inclinée, à basse fréquence, à haute fréquence, précipitée, ou même en biscuit, mais ils présentent toujours un TRS d’environ 70 dB HL.
Un autre facteur provient du domaine de la réorganisation tonotopique du cortex auditif des sujets animaux souffrant de SNHL. On sait que, dans le cas d’un SNHL soutenu dans le temps, une zone monotopique élargie du cortex auditif est établie dans laquelle les neurones voient leur fréquence caractéristique d’origine modifiée en une nouvelle fréquence (plus basse). Leurs courbes d’accord montrent des seuils élevés, une mauvaise discrimination des fréquences et une hypersensibilité aux fréquences autres que leur fréquence caractéristique d’origine13,14.
Il a également été suggéré que cette réorganisation tonotopique – un effet dû à la plasticité cérébrale en réponse à la stimulation auditive inadéquate et asymétrique au fil du temps – est étroitement liée à la privation/adaptation auditive chez les sujets humains qui ont un mauvais WRS sur les mots et les phrases monosyllabiques, et même avec d’autres performances de traitement du signal de haut niveau impliquant la séparation et l’intégration binaurale.13-17 Ici, pour les sujets de la catégorie de perte auditive de 70 dB, leurs différents degrés de perte auditive à travers les fréquences, les différents emplacements/gravités des dommages, et de nombreuses autres variables peuvent tous s’additionner comme des facteurs de confusion pour la formation de la réorganisation tonotopique du cortex auditif.
Cela signifie que, chez les sujets de cette catégorie, une zone monotopique différente dans le cortex auditif individuel perd ses capacités originales de traitement du signal. Elle devient accordée à une fréquence différente, divers pourcentages de neurones deviennent moins bien accordés, et des changements uniques dans l’arrangement du contour iso-fréquence dans le cortex peuvent se produire, tout comme divers degrés d’élévation du seuil et d’hypersensibilité des neurones à des fréquences autres que leur meilleure fréquence. Diverses réductions de la discrimination de fréquence et d’autres capacités de traitement neurologique supérieur devraient alors être attendues. Ces différentes caractéristiques de la réorganisation tonotopique résultante, à leur tour, conduisent à des variations de la performance des sujets dans le bruit de fond, le traitement du signal, et les résolutions de fréquence et d’intensitétout cela résultant en des différences dans la reconnaissance de la parole.
De plus, il ne fait aucun doute que les capacités linguistiques de chaque individu constituent une grande macrovariable dans les performances de compréhension de la parole de cette personne. Les capacités linguistiques des personnes – leurs compétences en matière de forme sémantique, de structure syntaxique et d’utilisation pragmatique du langage, etc. – diffèrent et peuvent les aider ou les gêner lors de pannes de communication (par exemple, lorsqu’elles essaient de combler les vides en utilisant des indices linguistiques et contextuels). Pour les personnes dans la catégorie de perte auditive de 70dB, qui ont déjà des difficultés à comprendre la parole, la capacité linguistique serait une macrovariable interagissant avec leur perte auditive et influençant le WRS, en particulier lorsque le WRS est mesuré en utilisant des matériaux de phrases dans un bruit de fond. De plus, la complexité du profil linguistique des personnes bilingues peut être aggravée par des variables telles que l’âge de l’acquisition de la seconde langue, la langue des parents, l’origine géographique de l’acquisition, l’utilisation de la langue, la durée d’exposition à la seconde langue, etc. et toutes ces variables ont une influence sur la performance du traitement de la parole/du langage, en particulier pendant les tâches d’écoute dans le bruit.18-20
1. Lewis MS, Crandell CC. Applications de la technologie de modulation de fréquence (FM). Présenté à : La 17e convention annuelle de l’Académie américaine d’audiologie (cours d’instruction IC-103), Washington, DC;2005.
4. Stach BA. Audiologie clinique : An Introduction. San Diego, Calif : Singular Publishing Group Inc ; 1998:193-249.
5. DeBonis DA, Donohue CL. Survey of Audiology : Fundamentals for Audiologists and Health Professionals. Boston, Mass : Allyn and Bacon ; 2004:77-164.
6. Brownell W, Bader C, Bertrand D, de Ribaupierre Y. Evoked mechanical responses of isolated cochlear outer hair cells. Science. 1985;227(11):194-196.
7 Dallos P, Evans B, Hallworth R. Nature of the motor element in electrokinetic shape changes of cochlear outer hair cells. Nature. 1991;350(14):155-157.
10. Gelfand SA. Hearing : An Introduction to Psychological and Physiological Acoustics. 3rd ed. New York, NY : Marcel Dekker Inc ; 1998:47-82.
11. Mencher GT, Gerber SE, McCombe A. Audiology and Auditory Dysfunction. Needham Heights, Mass : Allyn and Bacon ; 1997:105-232.
12. Martin FN, Clark JG. Introduction à l’audiologie. 9th ed. Boston, Mass : Allyn and Bacon ; 2006:277-346.
13. Harrison RV, Nagasawa A, Smith DW, Stanton S, Mount RJ. Réorganisation du cortex auditif après une perte auditive cochléaire haute fréquence néonatale. Hearing Res. 1991;54:11-19.
14. Dybala P. Effets de la perte auditive périphérique sur l’organisation tonotopique du cortex auditif. Hear Jour. 1997;50(9):49-54.
15. Silman S, Gelfand SA, Silverman CA. Privation auditive tardive : Effects of monaural versus binaural hearing aids. J Acoust Soc Amer. 1984;76(5):1357-1362.
16. Palmer CV. Déprivation, acclimatation, adaptation : Que signifient-ils pour l’adaptation de vos appareils auditifs ? Hear Jour. 1995;47(5):10,41-45.
17. Neuman AC. Late-onset auditory deprivation : A review of past research and an assessment of future research needs. Ear Hear. 1996;17(3):3s-13s.
18. Grosjean F. Processing mixed language : issues, findings, and models. Dans : de Groot AMB, Kroll JF, eds. Tutoriels sur le bilinguisme : Psycholinguistic Perspectives. Mahwah, NJ : Lawrence Erlbaum Associates ; 1997:225-251.
19. Mayo LH, Florentine M, Buus S. Age of second-language acquisition and perception of speech in noise. J Speech Lang Hear Res. 1997;40:686-693.
20. Von Hapsburg D, Champlin CA, Shetty SR. Seuils de réception des phrases chez des auditeurs bilingues (espagnol/anglais) et monolingues (anglais). J Amer Acad Audiol. 2004;15(1):88-98.