Dernière mise à jour le 27 janvier 2021
Il peut être difficile pour les débutants de distinguer les différentes tâches de vision par ordinateur liées.
Par exemple, la classification d’images est simple, mais les différences entre la localisation d’objets et la détection d’objets peuvent être déroutantes, surtout lorsque ces trois tâches peuvent tout aussi bien être désignées par le terme de reconnaissance d’objets.
La classification d’images consiste à attribuer une étiquette de classe à une image, tandis que la localisation d’objets consiste à dessiner une boîte englobante autour d’un ou plusieurs objets dans une image. La détection d’objets est plus difficile et combine ces deux tâches et dessine une boîte de délimitation autour de chaque objet d’intérêt dans l’image et leur attribue une étiquette de classe. Ensemble, tous ces problèmes sont appelés reconnaissance d’objets.
Dans ce post, vous découvrirez une introduction douce au problème de la reconnaissance d’objets et des modèles d’apprentissage profond de pointe conçus pour le résoudre.
Après avoir lu ce post, vous saurez :
- La reconnaissance d’objets fait référence à une collection de tâches connexes pour identifier des objets dans des photographies numériques.
- Les réseaux neuronaux convolutifs basés sur les régions, ou R-CNN, sont une famille de techniques pour aborder les tâches de localisation et de reconnaissance d’objets, conçues pour des performances de modèle.
- You Only Look Once, ou YOLO, est une deuxième famille de techniques pour la reconnaissance d’objets conçue pour la vitesse et l’utilisation en temps réel.
Démarrez votre projet avec mon nouveau livre Deep Learning for Computer Vision, comprenant des tutoriels étape par étape et les fichiers de code source Python pour tous les exemples.
Démarrons.

Une douce introduction à la reconnaissance d’objets avec l’apprentissage profond
Photo de Bart Everson, certains droits réservés.
Overview
Ce tutoriel est divisé en trois parties ; ce sont :
- Qu’est-ce que la reconnaissance d’objets ?
- Famille de modèles R-CNN
- Famille de modèles YOLO
Vous voulez des résultats avec l’apprentissage profond pour la vision par ordinateur ?
Prenez dès maintenant mon cours intensif gratuit de 7 jours par courriel (avec un exemple de code).
Cliquez pour vous inscrire et obtenir également une version PDF Ebook gratuite du cours.
Téléchargez votre mini-cours GRATUIT
Qu’est-ce que la reconnaissance des objets ?
La reconnaissance d’objets est un terme général pour décrire une collection de tâches de vision par ordinateur connexes qui impliquent l’identification d’objets dans des photographies numériques.
La classification d’images implique la prédiction de la classe d’un objet dans une image. La localisation d’objets fait référence à l’identification de l’emplacement d’un ou de plusieurs objets dans une image et au dessin d’une boîte environnante autour de leur étendue. La détection d’objets combine ces deux tâches et localise et classifie un ou plusieurs objets dans une image.
Lorsqu’un utilisateur ou un praticien fait référence à la « reconnaissance d’objets », il veut souvent dire « détection d’objets ».
… nous utiliserons le terme de reconnaissance d’objets au sens large pour englober à la fois la classification d’images (une tâche nécessitant un algorithme pour déterminer quelles classes d’objets sont présentes dans l’image) ainsi que la détection d’objets (une tâche nécessitant un algorithme pour localiser tous les objets présents dans l’image
– ImageNet Large Scale Visual Recognition Challenge, 2015.
À ce titre, nous pouvons distinguer ces trois tâches de vision par ordinateur :
- Classification d’images : Prédire le type ou la classe d’un objet dans une image.
- Entrée : Une image avec un seul objet, comme une photographie.
- Sortie : Une étiquette de classe (par exemple, un ou plusieurs entiers qui sont mis en correspondance avec des étiquettes de classe).
- Localisation d’objets : Localiser la présence d’objets dans une image et indiquer leur emplacement avec une boîte de délimitation.
- Entrée : Une image avec un ou plusieurs objets, comme une photographie.
- Sortie : Une ou plusieurs boîtes englobantes (par exemple, définies par un point, une largeur et une hauteur).
- Détection d’objets : Localiser la présence d’objets avec une boîte de délimitation et les types ou classes des objets localisés dans une image.
- Entrée : Une image avec un ou plusieurs objets, comme une photographie.
- Sortie : Une ou plusieurs boîtes de délimitation (par exemple, définies par un point, une largeur et une hauteur), et une étiquette de classe pour chaque boîte de délimitation.
Une autre extension de cette décomposition des tâches de vision par ordinateur est la segmentation d’objets, également appelée « segmentation d’instance d’objet » ou « segmentation sémantique », où les instances des objets reconnus sont indiquées en mettant en évidence les pixels spécifiques de l’objet au lieu d’une boîte de délimitation grossière.
À partir de ce découpage, nous pouvons voir que la reconnaissance d’objets fait référence à une suite de tâches difficiles de vision par ordinateur.
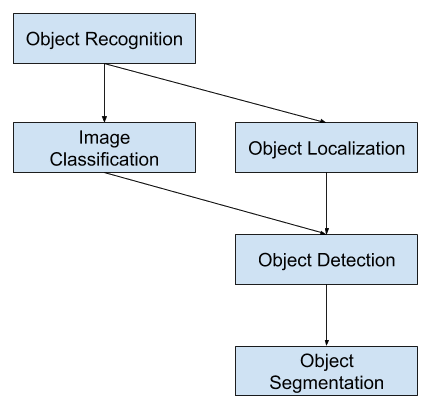
Vue d’ensemble des tâches de vision par ordinateur de reconnaissance d’objets
La plupart des innovations récentes dans les problèmes de reconnaissance d’images sont venues dans le cadre de la participation aux tâches de l’ILSVRC.
Il s’agit d’une compétition académique annuelle avec un défi distinct pour chacun de ces trois types de problèmes, avec l’intention de favoriser des améliorations indépendantes et distinctes à chaque niveau qui peuvent être exploitées plus largement. Par exemple, voir la liste des trois types de tâches correspondants ci-dessous, tirée du document d’examen de l’ILSVRC de 2015 :
- Classification d’images : Les algorithmes produisent une liste de catégories d’objets présents dans l’image.
- Localisation d’un seul objet : Les algorithmes produisent une liste de catégories d’objets présents dans l’image, ainsi qu’une boîte de délimitation alignée sur l’axe indiquant la position et l’échelle d’une instance de chaque catégorie d’objet.
- Détection d’objets : Les algorithmes produisent une liste de catégories d’objets présentes dans l’image, ainsi qu’une boîte de délimitation alignée sur l’axe indiquant la position et l’échelle de chaque instance de chaque catégorie d’objet.
Nous pouvons voir que la « localisation d’un seul objet » est une version plus simple de la « localisation d’objets » définie de manière plus large, en limitant les tâches de localisation aux objets d’un seul type dans une image, ce qui, nous pouvons le supposer, est une tâche plus facile.
Vous trouverez ci-dessous un exemple comparant la localisation d’un seul objet et la détection d’objets, tiré du document de l’ILSVRC. Notez la différence dans les attentes de la vérité du sol dans chaque cas.
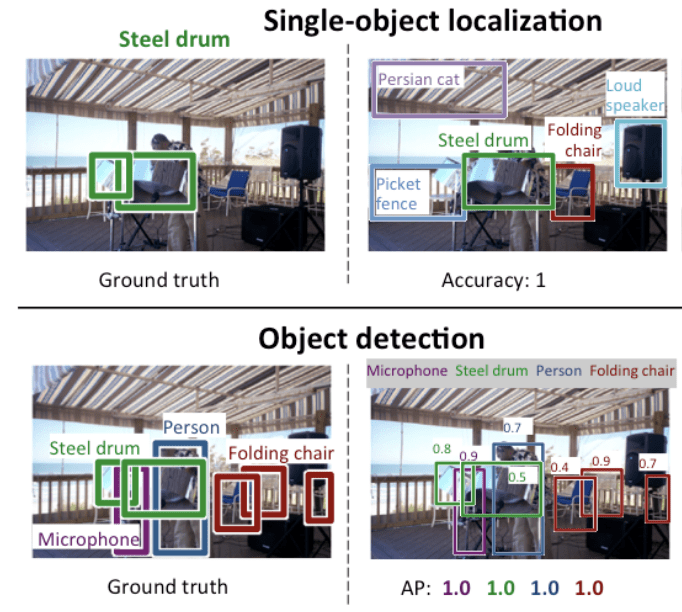
Comparaison entre la localisation d’un seul objet et la détection d’objets.Tiré de : ImageNet Large Scale Visual Recognition Challenge.
La performance d’un modèle pour la classification d’images est évaluée en utilisant l’erreur de classification moyenne sur les étiquettes de classe prédites. La performance d’un modèle pour la localisation d’un seul objet est évaluée en utilisant la distance entre la boîte de délimitation attendue et prédite pour la classe attendue. Alors que la performance d’un modèle pour la reconnaissance d’objets est évaluée en utilisant la précision et le rappel à travers chacune des meilleures boîtes de délimitation correspondantes pour les objets connus dans l’image.
Maintenant que nous sommes familiers avec le problème de la localisation et de la détection d’objets, jetons un coup d’œil à certains modèles récents d’apprentissage profond les plus performants.
Famille de modèles R-CNN
La famille de méthodes R-CNN fait référence au R-CNN, qui peut signifier » régions avec caractéristiques CNN » ou » réseau neuronal convolutif basé sur les régions « , développé par Ross Girshick, et al.
Cela comprend les techniques R-CNN, Fast R-CNN, et Faster-RCNN conçues et démontrées pour la localisation et la reconnaissance d’objets.
Regardons de plus près les points saillants de chacune de ces techniques à tour de rôle.
R-CNN
Le R-CNN a été décrit dans l’article de 2014 de Ross Girshick, et al. de l’UC Berkeley intitulé « Rich feature hierarchies for accurate object detection and semantic segmentation. »
Il pourrait avoir été l’une des premières applications importantes et réussies des réseaux neuronaux convolutifs au problème de la localisation, de la détection et de la segmentation des objets. L’approche a été démontrée sur des ensembles de données de référence, obtenant alors des résultats de pointe sur l’ensemble de données VOC-2012 et l’ensemble de données de détection d’objets ILSVRC-2013 de 200 classes.
Leur modèle R-CNN proposé est composé de trois modules ; ce sont :
- Module 1 : Proposition de région. Générer et extraire des propositions de régions indépendantes de la catégorie, par exemple des boîtes de délimitation candidates.
- Module 2 : Extracteur de caractéristiques. Extraire une caractéristique de chaque région candidate, par exemple en utilisant un réseau neuronal convolutif profond.
- Module 3 : Classificateur. Classifier les caractéristiques comme l’une de la classe connue, par exemple en utilisant un modèle de classificateur SVM linéaire.
L’architecture du modèle est résumée dans l’image ci-dessous, tirée de l’article.
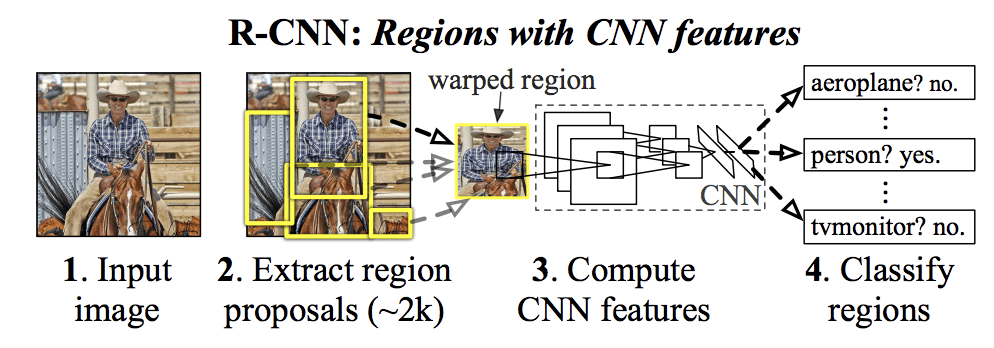
Résumé de l’architecture du modèle R-CNNPrise de Riches hiérarchies de caractéristiques pour une détection précise des objets et une segmentation sémantique.
Une technique de vision par ordinateur est utilisée pour proposer des régions candidates ou des boîtes limites d’objets potentiels dans l’image, appelée « recherche sélective », bien que la flexibilité de la conception permette d’utiliser d’autres algorithmes de proposition de régions.
L’extracteur de caractéristiques utilisé par le modèle était le CNN profond AlexNet qui a remporté le concours de classification d’images ILSVRC-2012. La sortie du CNN était un vecteur de 4 096 éléments qui décrit le contenu de l’image qui est alimenté à un SVM linéaire pour la classification, spécifiquement un SVM est formé pour chaque classe connue.
C’est une application relativement simple et directe des CNN au problème de la localisation et de la reconnaissance des objets. Un inconvénient de l’approche est qu’elle est lente, nécessitant une passe d’extraction de caractéristiques basée sur les CNN sur chacune des régions candidates générées par l’algorithme de proposition de région. C’est un problème car l’article décrit le modèle fonctionnant sur environ 2 000 régions proposées par image au moment du test.
Le code source de Python (Caffe) et MatLab pour R-CNN tel que décrit dans l’article a été mis à disposition dans le dépôt GitHub de R-CNN.
Fast R-CNN
Compte tenu du grand succès de R-CNN, Ross Girshick, alors chez Microsoft Research, a proposé une extension pour résoudre les problèmes de vitesse de R-CNN dans un article de 2015 intitulé « Fast R-CNN »
L’article s’ouvre sur un examen des limites de R-CNN, qui peuvent être résumées comme suit :
- La formation est un pipeline à plusieurs étapes. Implique la préparation et l’exploitation de trois modèles distincts.
- La formation est coûteuse en espace et en temps. L’entraînement d’un CNN profond sur autant de propositions de régions par image est très lent.
- La détection des objets est lente. Faire des prédictions en utilisant un CNN profond sur tant de propositions de régions est très lent.
Un travail préalable a été proposé pour accélérer la technique appelée réseaux de mise en commun de pyramides spatiales, ou SPPnets, dans l’article de 2014 « Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. » Cela a effectivement accéléré l’extraction des caractéristiques, mais a essentiellement utilisé un type d’algorithme de mise en cache de passage vers l’avant.
Le R-CNN rapide est proposé comme un modèle unique au lieu d’un pipeline pour apprendre et sortir des régions et des classifications directement.
L’architecture du modèle prend la photographie un ensemble de propositions de régions comme entrée qui sont passées à travers un réseau neuronal convolutif profond. Un CNN pré-entraîné, tel qu’un VGG-16, est utilisé pour l’extraction des caractéristiques. La fin du CNN profond est une couche personnalisée appelée couche de mise en commun de la région d’intérêt, ou RoI Pooling, qui extrait les caractéristiques spécifiques à une région candidate d’entrée donnée.
La sortie du CNN est ensuite interprétée par une couche entièrement connectée puis le modèle bifurque en deux sorties, une pour la prédiction de la classe via une couche softmax, et une autre avec une sortie linéaire pour la boîte de délimitation. Ce processus est ensuite répété plusieurs fois pour chaque région d’intérêt dans une image donnée.
L’architecture du modèle est résumée dans l’image ci-dessous, tirée de l’article.
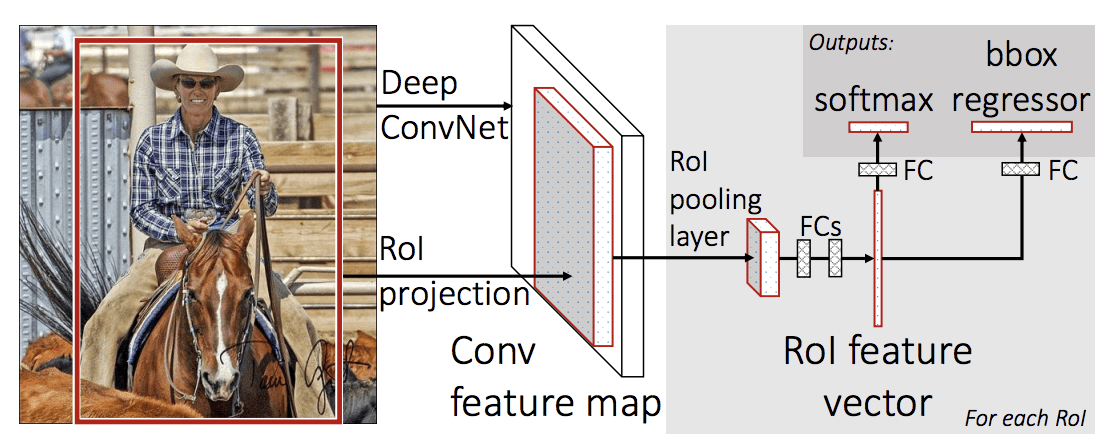
Sommaire de l’architecture du modèle R-CNN rapide.
Taken from : R-CNN rapide.
Le modèle est significativement plus rapide à entraîner et à faire des prédictions, mais nécessite toujours un ensemble de régions candidates à proposer avec chaque image d’entrée.
Le code source Python et C++ (Caffe) pour Fast R-CNN tel que décrit dans l’article a été mis à disposition dans un dépôt GitHub.
Faster R-CNN
L’architecture du modèle a été encore améliorée à la fois pour la vitesse d’entraînement et de détection par Shaoqing Ren, et al. chez Microsoft Research dans l’article de 2016 intitulé « Faster R-CNN : Towards Real-Time Object Detection with Region Proposal Networks »
L’architecture a été la base des résultats de première place obtenus sur les tâches du concours de reconnaissance et de détection d’objets ILSVRC-2015 et MS COCO-2015.
L’architecture a été conçue pour à la fois proposer et affiner des propositions de régions dans le cadre du processus de formation, appelé réseau de proposition de région, ou RPN. Ces régions sont ensuite utilisées de concert avec un modèle R-CNN rapide dans une conception de modèle unique. Ces améliorations permettent à la fois de réduire le nombre de propositions de régions et d’accélérer le fonctionnement du modèle en temps de test jusqu’à un temps quasi réel avec des performances de pointe.
… notre système de détection a une fréquence d’images de 5fps (incluant toutes les étapes) sur un GPU, tout en atteignant une précision de détection d’objets de pointe sur les ensembles de données PASCAL VOC 2007, 2012 et MS COCO avec seulement 300 propositions par image. Dans les compétitions ILSVRC et COCO 2015, Faster R-CNN et RPN sont les fondations des entrées gagnantes de la 1ère place dans plusieurs pistes
– Faster R-CNN : Towards Real-Time Object Detection with Region Proposal Networks, 2016.
Bien qu’il s’agisse d’un seul modèle unifié, l’architecture est composée de deux modules :
- Module 1 : Réseau de proposition de région. Réseau neuronal convolutif pour proposer des régions et le type d’objet à considérer dans la région.
- Module 2 : Fast R-CNN. Réseau neuronal convolutif pour extraire les caractéristiques des régions proposées et sortir la boîte englobante et les étiquettes de classe.
Les deux modules fonctionnent sur la même sortie d’un CNN profond. Le réseau de proposition de régions agit comme un mécanisme d’attention pour le réseau R-CNN rapide, informant le second réseau de l’endroit où regarder ou prêter attention.
L’architecture du modèle est résumée dans l’image ci-dessous, tirée de l’article.
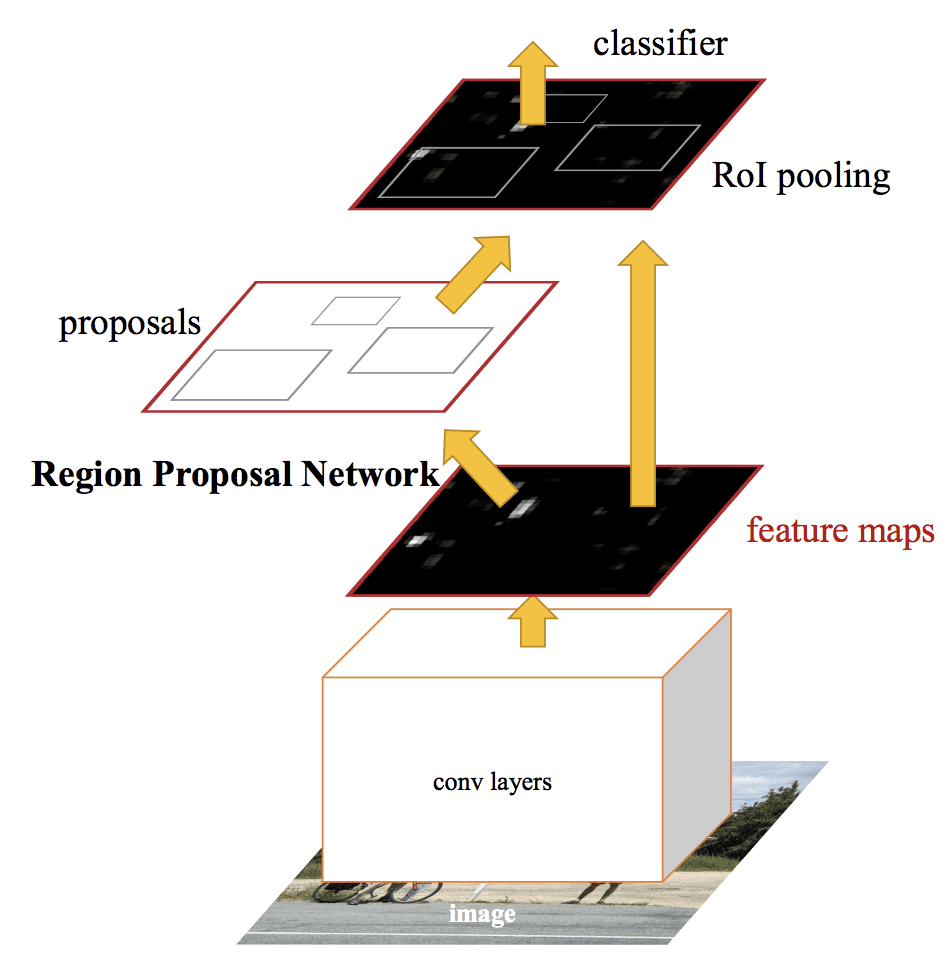
Résumé de l’architecture du modèle Faster R-CNN.Tiré de : Faster R-CNN : Towards Real-Time Object Detection With Region Proposal Networks.
Le RPN fonctionne en prenant la sortie d’un CNN profond pré-entraîné, tel que VGG-16, et en passant un petit réseau sur la carte de caractéristiques et en sortant plusieurs propositions de régions et une prédiction de classe pour chacune. Les propositions de régions sont des boîtes de délimitation, basées sur des boîtes dites d’ancrage ou des formes prédéfinies conçues pour accélérer et améliorer la proposition de régions. La prédiction de classe est binaire, indiquant la présence ou non d’un objet, ce que l’on appelle « objectness » de la région proposée.
Une procédure d’entraînement alterné est utilisée où les deux sous-réseaux sont entraînés en même temps, bien qu’entrelacés. Cela permet d’adapter ou d’affiner les paramètres du CNN profond du détecteur de caractéristiques pour les deux tâches en même temps.
Au moment de la rédaction, cette architecture R-CNN Faster est le summum de la famille de modèles et continue d’obtenir des résultats proches de l’état de l’art sur les tâches de reconnaissance d’objets. Une autre extension ajoute le support pour la segmentation d’images, décrite dans l’article 2017 « Mask R-CNN. »
Le code source Python et C++ (Caffe) pour Fast R-CNN tel que décrit dans l’article a été mis à disposition dans un dépôt GitHub.
Famille de modèles YOLO
Une autre famille populaire de modèles de reconnaissance d’objets est désignée collectivement comme YOLO ou « You Only Look Once », développée par Joseph Redmon, et al.
Les modèles R-CNN peuvent être généralement plus précis, mais la famille de modèles YOLO est rapide, beaucoup plus rapide que R-CNN, réalisant la détection d’objets en temps réel.
YOLO
Le modèle YOLO a été décrit pour la première fois par Joseph Redmon, et al. dans l’article de 2015 intitulé « You Only Look Once : Unified, Real-Time Object Detection. » Notez que Ross Girshick, développeur de R-CNN, était également un auteur et un contributeur à ce travail, alors chez Facebook AI Research.
L’approche implique un seul réseau neuronal formé de bout en bout qui prend une photographie comme entrée et prédit directement les boîtes de délimitation et les étiquettes de classe pour chaque boîte de délimitation. Cette technique offre une précision prédictive plus faible (par exemple, plus d’erreurs de localisation), bien qu’elle fonctionne à 45 images par seconde et jusqu’à 155 images par seconde pour une version du modèle optimisée en termes de vitesse.
Notre architecture unifiée est extrêmement rapide. Notre modèle de base YOLO traite les images en temps réel à 45 images par seconde. Une version plus petite du réseau, Fast YOLO, traite un étonnant 155 images par seconde…
– You Only Look Once : Unified, Real-Time Object Detection, 2015.
Le modèle fonctionne en divisant d’abord l’image d’entrée en une grille de cellules, où chaque cellule est responsable de la prédiction d’une boîte englobante si le centre d’une boîte englobante tombe dans la cellule. Chaque cellule de la grille prédit une boîte englobant les coordonnées x, y, la largeur, la hauteur et la confiance. Une prédiction de classe est également basée sur chaque cellule.
Par exemple, une image peut être divisée en une grille 7×7 et chaque cellule de la grille peut prédire 2 boites limites, ce qui donne 94 prédictions de boites limites proposées. La carte des probabilités de classe et les bounding boxes avec les confidences sont ensuite combinées en un ensemble final de bounding boxes et d’étiquettes de classe. L’image tirée de l’article ci-dessous résume les deux sorties du modèle.
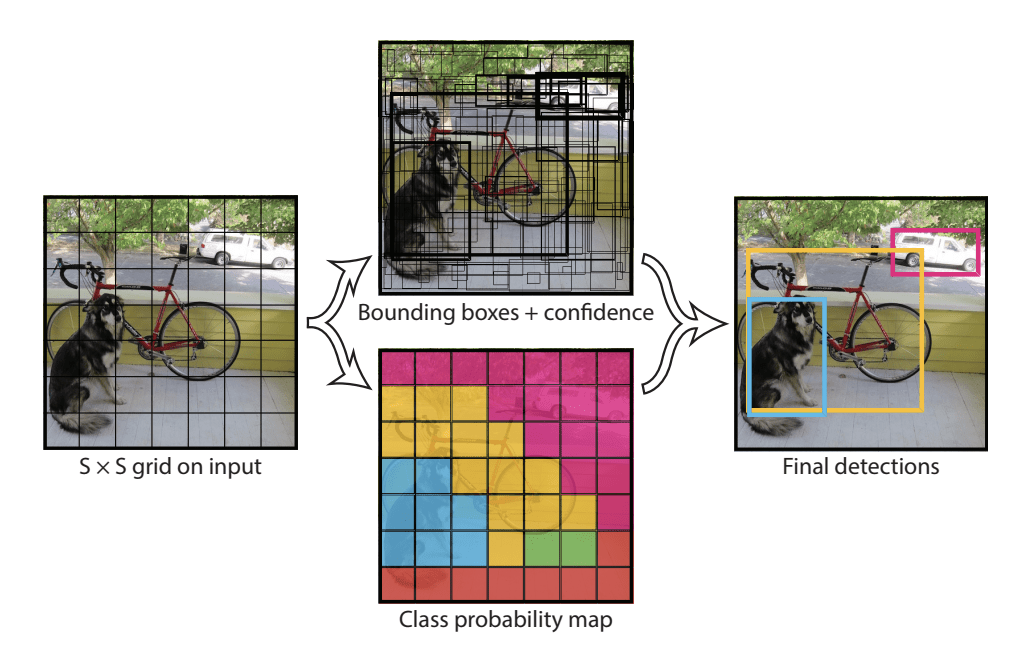
Résumé des prédictions faites par le modèle YOLO.Tiré de : You Only Look Once : Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) et YOLOv3
Le modèle a été mis à jour par Joseph Redmon et Ali Farhadi dans le but d’améliorer encore les performances du modèle dans leur article de 2016 intitulé « YOLO9000 : Better, Faster, Stronger. »
Bien que cette variante du modèle soit appelée YOLO v2, une instance du modèle est décrite qui a été entraînée sur deux ensembles de données de reconnaissance d’objets en parallèle, capable de prédire 9 000 classes d’objets, d’où le nom « YOLO9000″. »
Un certain nombre de modifications de formation et d’architecture ont été apportées au modèle, telles que l’utilisation de la normalisation par lots et d’images d’entrée à haute résolution.
Comme Faster R-CNN, le modèle YOLOv2 fait appel à des boîtes d’ancrage, des boîtes de délimitation prédéfinies avec des formes et des tailles utiles qui sont adaptées pendant la formation. Le choix des boîtes de délimitation pour l’image est prétraité à l’aide d’une analyse k-means sur l’ensemble de données d’entraînement.
Important, la représentation prédite des boîtes de délimitation est modifiée pour permettre aux petits changements d’avoir un effet moins dramatique sur les prédictions, ce qui donne un modèle plus stable. Plutôt que de prédire directement la position et la taille, les décalages sont prédits pour le déplacement et le remodelage des boîtes d’ancrage prédéfinies par rapport à une cellule de grille et amortis par une fonction logistique.
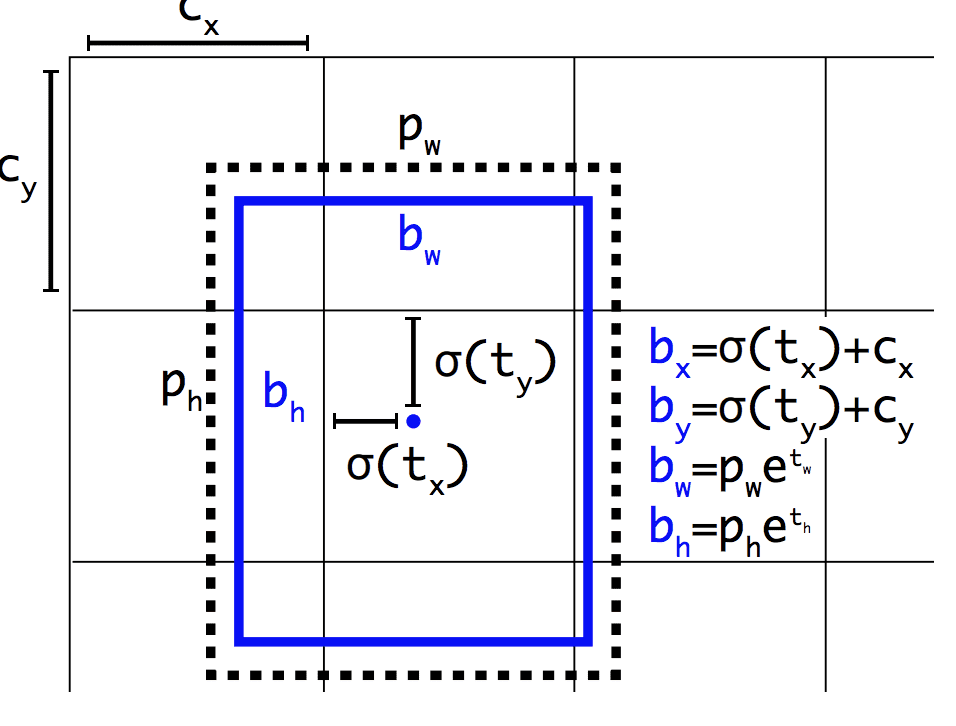
Exemple de la représentation choisie lors de la prédiction de la position et de la forme des boîtes d’ancrageTaken from : YOLO9000 : Better, Faster, Stronger
De nouvelles améliorations du modèle ont été proposées par Joseph Redmon et Ali Farhadi dans leur article de 2018 intitulé « YOLOv3 : An Incremental Improvement. » Les améliorations étaient raisonnablement mineures, y compris un réseau de détecteur de caractéristiques plus profond et des changements mineurs de représentation.
Lectures complémentaires
Cette section fournit plus de ressources sur le sujet si vous cherchez à approfondir.
Papers
- ImageNet Large Scale Visual Recognition Challenge, 2015.
Papiers de la famille R-CNN
- Hiérarchies de caractéristiques riches pour la détection précise d’objets et la segmentation sémantique, 2013.
- Mise en commun des pyramides spatiales dans les réseaux convolutifs profonds pour la reconnaissance visuelle, 2014.
- R-CNN rapide, 2015.
- R-CNN plus rapide : Towards Real-Time Object Detection with Region Proposal Networks, 2016.
- Mask R-CNN, 2017.
YOLO Family Papers
- You Only Look Once : Unified, Real-Time Object Detection, 2015.
- YOLO9000 : meilleur, plus rapide, plus fort, 2016.
- YOLOv3 : une amélioration incrémentale, 2018.
Projets de code
- R-CNN : Régions avec des caractéristiques de réseau neuronal convolutif, GitHub.
- R-CNN rapide, GitHub.
- Code Python R-CNN plus rapide, GitHub.
- YOLO, GitHub.
Ressources
- Ross Girshick, Page d’accueil.
- Joseph Redmon, Page d’accueil.
- YOLO : Détection d’objets en temps réel, Page d’accueil.
Articles
- Une brève histoire des CNN dans la segmentation d’images : Du R-CNN au R-CNN de masque, 2017.
- La détection d’objets pour les nuls Partie 3 : la famille des R-CNN, 2017.
- La détection d’objets Partie 4 : modèles de détection rapide, 2018.
Summary
Dans ce post, vous avez découvert une introduction douce au problème de la reconnaissance d’objets et des modèles d’apprentissage profond de pointe conçus pour y répondre.
Spécifiquement, vous avez appris :
- La reconnaissance d’objets fait référence à une collection de tâches connexes pour identifier des objets dans des photographies numériques.
- Les réseaux neuronaux convolutifs basés sur les régions, ou R-CNN, sont une famille de techniques pour aborder les tâches de localisation et de reconnaissance d’objets, conçues pour des performances de modèle.
- You Only Look Once, ou YOLO, est une deuxième famille de techniques pour la reconnaissance d’objets, conçue pour la vitesse et l’utilisation en temps réel.
Avez-vous des questions ?
Posez vos questions dans les commentaires ci-dessous et je ferai de mon mieux pour y répondre.
Développez des modèles d’apprentissage profond pour la vision dès aujourd’hui !

Développez vos propres modèles de vision en quelques minutes
….avec seulement quelques lignes de code python
Découvrez comment dans mon nouvel Ebook:
Deep Learning for Computer Vision
Il fournit des tutoriels d’auto-apprentissage sur des sujets tels que:
classification, détection d’objets (yolo et rcnn), reconnaissance de visages (vggface et facenet), préparation de données et bien plus encore…
Apportez enfin l’apprentissage profond à vos projets de vision
Skip les universitaires. Juste des résultats.
Voyez ce qu’il y a dedans