L’SRT ha poca influenza sulla capacità complessiva di riconoscimento delle parole. Anche se sembra esserci un presupposto o un approccio di lavoro nel nostro campo (e anche all’interno della comunità di ricerca) per utilizzare il punto di dati del 50% per prevedere le massime prestazioni di elaborazione del discorso, questo è, infatti, uno sforzo senza alcun fondamento clinico o teorico.
È fattibile utilizzare la soglia di riconoscimento vocale (SRT) come misura predittiva di un individuo Word Recognition Score (WRS)? Nel corso del processo di selezione degli apparecchi acustici, è necessario prendere una decisione tra due apparecchi acustici o tra le impostazioni di prestazione di un singolo apparecchio acustico. Un’impostazione delle prestazioni produce un SRT migliore dell’altra. Quali sono i fattori principali dietro una decisione clinica che pesano sull’equazione tra i professionisti attuali? Quando si vede che un apparecchio è in grado di fornire un SRT migliore a un livello di presentazione del segnale inferiore o a un rapporto segnale-rumore (SNR, o rapporto S/N) migliore rispetto ad altri apparecchi, cosa dovrebbe aspettarsi il professionista da un apparecchio che ha un SRT migliore? Sceglieremo questo dispositivo perché, come previsto dal nostro giudizio professionale, porterà a migliori prestazioni di comprensione del parlato nel mondo reale?
Quando si scopre che un apparecchio acustico digitale con un sistema direzionale è associato a un SRT leggermente migliore in termini di SNR, molti di noi sceglierebbero quell’apparecchio e si aspetterebbero di vedere migliori punteggi di intelligibilità del parlato quando il sistema direzionale si attiva. Allo stesso modo, quando un dispositivo di ascolto assistito (ALD), come un sistema FM, mostra un beneficio leggermente maggiore nell’SRT rispetto ad altri dispositivi, molti medici tendono a dedurre ragionevolmente che l’ALD produrrà prestazioni superiori di comprensione del parlato.1
Infatti, la letteratura ha persino cercato di prevedere le prestazioni di comprensione del parlato dei soggetti dalla soglia di riconoscimento della frase, basandosi sulla pendenza della curva della funzione Performance-Intensità (P-I) dalla quale è stata ottenuta la soglia di riconoscimento della frase. Per fare solo un esempio, potremmo leggere in letteratura che secondo il manuale del test, una differenza di 1 dB nel rapporto S/N equivale a 9 punti percentuali nell’intelligibilità delle frasi. Così, una differenza di 4 dB nel rapporto S/N tra i gruppi implica punteggi di intelligibilità del discorso di circa il 36% più poveri nei bilingui che nei madrelingua monolingui.
Evidentemente, l’assunto di base per tutti questi approcci è che si può fare una previsione o una stima delle prestazioni di intelligibilità del discorso di un individuo dal SRT. Tuttavia, questo approccio ampiamente accettato è abbastanza preciso per l’uso clinico? Possiamo davvero essere in grado di stimare o prevedere il punteggio di comprensione del parlato di un utente di apparecchi acustici semplicemente basandoci su quel punto del 50%?
Considerazioni teoriche
Come la soglia del tono puro (PT), che è il livello più morbido al quale il segnale del tono puro è appena percepibile per il 50% del tempo, la soglia di riconoscimento del parlato (SRT) è il livello di soglia al quale il segnale del parlato è appena riconoscibile per il 50% del tempo.3-5 Ancora una volta, come la soglia del tono puro, che rappresenta la sensibilità uditiva di un individuo ai segnali di tono puro, la SRT rappresenta la sensibilità uditiva di un individuo ai segnali vocali. Per definizione e per la natura della procedura di test per la determinazione della soglia, l’SRT indica una risposta dell’individuo al segnale vocale al livello della soglia. Questa è una sfumatura importante: L’SRT indica la risposta ai segnali vocali quando il segnale vocale è presentato a un livello abbastanza morbido, tale che è appena quasi percepibile/riconoscibile per circa il 50% del tempo. Dal momento che il segnale vocale è a quel livello appena riconoscibile e che durante il test sono naturalmente coinvolte congetture, l’SRT è la risposta a livello di soglia, a parte la risposta a livello di soprasoglia dell’individuo.
D’altra parte, il Word Recognition Score (WRS) rappresenta tutte le possibili risposte quando il segnale vocale viene presentato a vari livelli di volume sopra la soglia individuale.3-5 Il WRS mostra quanto bene il paziente può sentire ed elaborare i segnali vocali a vari livelli sopra soglia; al contrario, l’SRT indica quanto la persona è sensibile a sentire i segnali vocali a specifici livelli appena percettibili. Quindi, rispetto al tracciare tutte le possibili risposte WRS in funzione dei livelli di presentazione del segnale, l’SRT è noto nel campo come il punto del 50% sulla curva Performance-Intensità. Il punto di partenza è che l’SRT è la risposta a livello di soglia, mentre il WRS è la risposta a livello sopra-soglia agli stimoli vocali; in nessun modo l’SRT indica o accenna a risposte sopra-soglia.
Esame dell’SRT e del WRS per diversi tipi di perdita uditiva
Per illustrare quanto sopra, la Figura 1 mostra quattro ipotetici SRT visualizzati come quattro punti dati in funzione del WRS (rispetto ai livelli di presentazione del segnale vocale). I quattro punti di dati rappresentano il livello di segnale più tenue al quale il segnale vocale è appena percettibile per il 50% del tempo per individui con sensibilità uditiva normale e vari gradi di perdita uditiva di circa 50 dB, 70 dB e 90 dB HL. I quattro punti di dati indicano anche che la prestazione di riconoscimento delle parole è del 50% poiché gli individui dei quattro tipi di stato uditivo possono riconoscere i segnali vocali con una precisione del 50% solo quando i segnali vocali sono presentati ai loro livelli di soglia, rispettivamente.
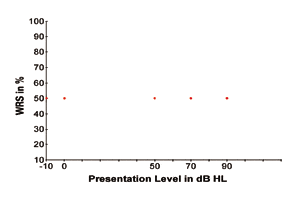 FIGURA 1. Quattro ipotetiche soglie di riconoscimento vocale (SRT) visualizzate come quattro punti di dati per l’udito normale e vari gradi di perdita uditiva.
FIGURA 1. Quattro ipotetiche soglie di riconoscimento vocale (SRT) visualizzate come quattro punti di dati per l’udito normale e vari gradi di perdita uditiva.
Allora, come sarebbe la curva prestazione-intensità quando i segnali vocali sono presentati ai loro livelli soprasoglia? Sulla base di questi quattro punti di dati, possiamo stimare i loro punteggi massimi di riconoscimento delle parole quando i segnali vocali sono presentati a vari livelli superiori? Allo stesso modo, se questi quattro punti di dati rappresentano gli SRT con un apparecchio acustico appropriato in uso, siamo in grado di prevedere il punteggio massimo di intelligibilità del discorso di un soggetto dopo aver ricevuto il beneficio di un apparecchio acustico? Ipotetiche curve di Performance-Intensità che mostrano vari punteggi massimi di riconoscimento delle parole (asse y) per le quattro ipotetiche soglie di riconoscimento del parlato (SRT) come mostrato nella Figura 1, che rappresenta il livello di presentazione in cui il discorso è appena riconoscibile per il 50% del tempo. Va notato che le curve mostrate qui sono solo una porzione limitata della famiglia di tutte le possibili prestazioni di elaborazione del discorso che sono possibili con i vari gradi di perdita uditiva.
La figura 2 può servire a rispondere a queste domande. Sulla base di esperienze cliniche e considerazioni teoriche, sono stati tracciati esempi di alcune curve ipotetiche di Performance-Intensità (P-I) per dimostrare l’interrelazione e il modello di risposta dei punteggi di riconoscimento delle parole dei soggetti per individui con stato di udito normale e vari gradi di perdite uditive.
Per lo stato di udito normale. Nella Figura 2, la curva all’estrema sinistra (ad esempio, passando il livello di presentazione 0 dB) può essere utilizzata come la curva che rappresenta gli individui normoudenti. Questa è quella che si vede spesso nei libri di testo e che indica che la prestazione aumenta all’aumentare del livello di presentazione del segnale con una pendenza fissa, se misurata con una procedura di prova fissa e un dato materiale di prova per il parlato. La performance raggiunge il WRS massimo a circa 40 dB di Sensation Level (SL) sopra l’SRT.
Per perdite uditive di 50 dB. Nella Figura 2, a destra della curva per gli individui con udito normale, un gruppo di curve che passa il livello di presentazione di 50 dB rappresenta le risposte tipiche sul WRS per la categoria di ascoltatori con perdita uditiva di 50 dB. Tra questa categoria con perdita uditiva di 50 dB (5 curve a linea continua), la curva a sinistra mostra la funzione P-I quando la perdita uditiva di 50 dB è di natura conduttiva. Si noti che la curva ha esattamente la stessa pendenza e raggiunge lo stesso WRS massimo di quello dei soggetti con udito normale, perché la perdita uditiva conduttiva è, per natura, una perdita di sensibilità che non comporta alcuna patologia nell’orecchio interno e nelle strutture superiori.
Quando la perdita uditiva di 50 dB comporta una perdita uditiva di natura mista (ad esempio, una lieve componente di perdita uditiva neurosensoriale), allora la capacità di elaborazione del segnale dei soggetti è ridotta. Le loro curve P-I (le altre 4 curve solide in questo gruppo di curve) potrebbero ancora salire, ma con una pendenza più ripida e diventare appiattite a un WRS massimo inferiore, rispetto alla curva dei soggetti con udito normale o con perdita uditiva conduttiva.
Da questa categoria di perdita uditiva di 50 dB, si può vedere che tutte le curve mostrano lo stesso SRT ma con una grande differenza individuale nel WRS massimo che va possibilmente dal 70% al 100%.
Per perdite uditive di 70 dB. Più a destra nella Figura 2, ci sono 4 linee tratteggiate che passano attraverso il punto di dati SRT di 70 dB, che culminano in una diversa WRS massima. Queste rappresentano i possibili modelli di risposta e le differenze individuali sulla funzione P-I per la categoria di perdita uditiva di 70 dB. La categoria di perdita uditiva intorno ai 70 dB SRT è di solito la maggioranza della popolazione di clienti vista nella tipica clinica degli apparecchi acustici.
Dovrebbe essere immediatamente evidente che maggiori variazioni nel WRS massimo, come mostrato nella Figura 2, possono derivare da questo tipo di perdita. È anche interessante notare che alcune curve tratteggiate raggiungono una prestazione WRS superiore a quelle della categoria con perdita uditiva di 50 dB, mentre altre mostrano una prestazione che è, in generale, inferiore. Una curva (la curva tratteggiata in basso) mostra un piccolo grado di fenomeno di rollover: WRS più scadente a livelli di presentazione più alti una volta raggiunto il WRS più alto.
La grande quantità di variazione individuale rivelata dalle curve P-I è spesso legata alla perdita uditiva neurosensoriale (SNHL) con patologia delle cellule ciliate e delle fibre neurali coinvolte. Queste perdite sono spesso caratterizzate sia da una perdita di sensibilità che da una perdita di chiarezza, con la perdita di chiarezza nei segnali vocali che varia drasticamente a seconda di fattori quali, ma non solo, il grado di perdita uditiva, la forma della perdita uditiva, l’eziologia della perdita uditiva, la condizione patologica della struttura orecchio-cervello, l’entità del danno alle cellule ciliate esterne e/o interne, il danno e gli effetti sull’amplificazione cocleare attiva, la funzione residua delle cellule ciliate interne, danno alle fibre nervose retro cocleari, effetto sulla sincronia delle scariche neurali, proporzione della lesione retro cocleare rispetto alla lesione cocleare, effetto della riorganizzazione tonotopica della corteccia uditiva, durata della perdita uditiva, storia dell’uso di apparecchi acustici, quantità di tempo associata ad una (in)adeguata stimolazione uditiva, casi prelinguali rispetto a quelli postlinguali, stile di vita e dintorni, capacità linguistica degli individui (vedi barra laterale, Esiste una cosa come una tipica perdita uditiva di 70 dB?).
E’ chiaro che una miriade di fattori, come discusso nella barra laterale, compresi quelli in ambito patologico e linguistico, interagiscono tra loro come meccanismi sottostanti che influenzano le prestazioni di elaborazione del segnale vocale. Pertanto, grandi differenze individuali sul modello di risposta dell’elaborazione del segnale vocale, la pendenza della curva P-I e la massima WRS, dovrebbero essere ragionevolmente prevedibili tra i soggetti. Per la categoria di perdita uditiva di 70dB di SNHL, ciò che è mostrato nella Figura 2 è solo una parte delle possibili funzioni P-I con vari WRS massimi raggiunti tutti con uno stesso SRT.
Pertanto, la figura 2 e il buon senso suggeriscono che prevedere il possibile WRS massimo dall’SRT è un approccio avventato senza le opportune avvertenze.
Per perdite uditive di 90 dB. Quando il grado di perdita uditiva si sposta verso la categoria di perdita uditiva di 90 dB, il SNHL normalmente coinvolge la componente neurale per integrare la componente sensoriale, producendo perdite molto maggiori nella chiarezza del segnale insieme alla perdita di sensibilità. Questi tipi di perdite suggeriscono più danni nella regione retrococleare e in altre stazioni di trasmissione neurale lungo le vie uditive superiori. Così, più danni neurologici sulle vie più alte, con una maggiore possibilità di dissincronia delle scariche neurali e disturbi dell’elaborazione uditiva, possono diventare una possibilità e rivelare prestazioni di elaborazione del segnale ancora più scarse (rispetto alla categoria con perdita uditiva di 70 dB). Tutti i fattori discussi sopra, come il grado effettivo di perdita uditiva attraverso le frequenze, l’eziologia particolare, la posizione e la gravità del danno nell’orecchio interno e nelle vie uditive, la riorganizzazione tonotopica, l’abilità linguistica degli individui, ecc. potrebbero interagire tra loro e risultare in diversi modelli di risposta e pendenze della curva P-I. Anche in questo caso, ci si aspetterebbe grandi variazioni nelle prestazioni massime di elaborazione del segnale vocale.
Nella Figura 2, sono state tracciate tre curve (due tratteggiate e una linea continua che passa per il punto dati di 90 dB) per mostrare le varie pendenze con vari WRS massimi che possono essere raggiunti da individui in questa categoria di perdita uditiva. La curva a linea continua mostra un fenomeno di roll-over ancora maggiore rispetto a quello della categoria con perdita uditiva di 70 dB. Tutte e tre le curve sono posizionate per mostrare che il loro WRS massimo è probabilmente inferiore a quello della categoria con perdita uditiva di 70 dB.
Ovviamente, sappiamo che alcuni soggetti con una perdita uditiva di circa 90 dB mostrerebbero una WRS estremamente ed eccezionalmente buona rispetto a quelli con una perdita uditiva anche lieve. Questo tipo di eccezione non è del tutto infrequente; supporta ulteriormente la grande variabilità delle funzioni di prestazione dell’elaborazione del segnale e del sistema uditivo. Il punto unico di discussione qui è che tutte queste curve passano attraverso lo stesso punto dati di 90 dB SRT e producono una WRS massima radicalmente diversa. Come per il gruppo con perdita di 70 dB, ci sono grandi differenze individuali.
Nell’angolo in basso a destra della Figura 2, vengono visualizzate altre tre curve che mostrano alcune possibili curve P-I per coloro che hanno una perdita uditiva superiore a 90 dB HL. Con questo profondo grado di perdita uditiva e fattori di confusione (come discusso sopra), grandi differenze individuali nella pendenza della curva di risposta e il massimo WRS dovrebbe essere previsto.
L’unicità di queste tre curve è che la prestazione di riconoscimento vocale ascendente dei soggetti potrebbe anche non raggiungere il punto del 50%. Inoltre, sia il WRS massimo che il fenomeno del rollover possono essere ancora più poveri o più pronunciati, rispettivamente, delle perdite di 70 dB.
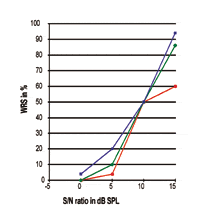 FIGURA 3. Tre curve individuali Performance-Intensità espresse in rapporto S/N. Si noti che il punto del 50% è esattamente a 10 dB SPL mentre la pendenza e le prestazioni massime di elaborazione del discorso sono chiaramente diverse.
FIGURA 3. Tre curve individuali Performance-Intensità espresse in rapporto S/N. Si noti che il punto del 50% è esattamente a 10 dB SPL mentre la pendenza e le prestazioni massime di elaborazione del discorso sono chiaramente diverse.
Prova clinica
Alcuni dati clinici empirici possono essere utili per dimostrare quanto sopra. Nel tentativo di studiare l’effetto della soglia di compressione sull’intelligibilità del discorso, 12 soggetti con SNHL da lieve a grave sopra i 2 kHz hanno ascoltato attraverso un apparecchio acustico programmabile le frasi target del test Speech In Noise (SIN). Esempi delle prestazioni di elaborazione del discorso di questi soggetti sono stati selezionati e tracciati come curve P-I relative al SNR (Figure 3-6).
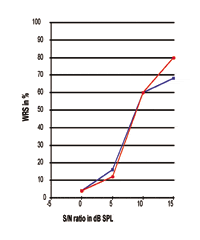 FIGURA 4. Due curve individuali Performance-Intensità espresse in rapporto S/N. Si noti che il punto del 50% è intorno a 9,06 dB SPL mentre la pendenza e le prestazioni massime di elaborazione del discorso sono chiaramente diverse.
FIGURA 4. Due curve individuali Performance-Intensità espresse in rapporto S/N. Si noti che il punto del 50% è intorno a 9,06 dB SPL mentre la pendenza e le prestazioni massime di elaborazione del discorso sono chiaramente diverse.
Riferendosi alle figure 3-5, è chiaro che le prestazioni WRS di diversi soggetti possono essere esattamente le stesse al punto del 50%, mentre la pendenza della curva e le prestazioni massime sono completamente diverse tra loro. Tutte queste curve mostrano che l’SRT è, in effetti, solo il punto dati del 50% lungo la curva di risposta; grandi differenze rispetto alla pendenza della curva e alla massima prestazione di elaborazione esistono nel mondo reale. Le figure indicano che il punto di dati del 50% non ha una stretta relazione con la massima prestazione di elaborazione che sarebbe compiuta dagli individui. Quindi, l’SRT non dovrebbe essere usato come rappresentativo per le risposte di performance-intensità.
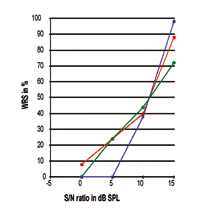 FIGURA 5. Tre curve individuali di Performance-Intensità espresse in rapporto S/N. Si noti che il punto del 50% è intorno a 10,75 dB SPL mentre la pendenza e le prestazioni massime di elaborazione del discorso sono chiaramente diverse.
FIGURA 5. Tre curve individuali di Performance-Intensità espresse in rapporto S/N. Si noti che il punto del 50% è intorno a 10,75 dB SPL mentre la pendenza e le prestazioni massime di elaborazione del discorso sono chiaramente diverse.
Questa informazione suggerisce anche che, quando si consiglia agli studenti laureati e si formulano progetti di ricerca, potrebbe non essere saggio usare l’SRT come criterio primario dello studio. Anche se molti test sono ora progettati per trovare il punto del 50% delle prestazioni di elaborazione del discorso dei soggetti, l’interpretazione del punto del 50% o dell’SRT espresso in termini di livello di presentazione o SNR dovrebbe essere fatta con cautela. La performance di elaborazione del discorso è un fenomeno più complicato.
Nella Figura 6, le tre curve P-I individuali sono con un punto del 50% totalmente diverso. La curva rossa rappresenta un individuo con SNHL lieve ad alta frequenza, mentre le altre due curve sono state ottenute da individui con SNHL moderato-grave ad alta frequenza. Infatti, la ripida pendenza e le prestazioni di elaborazione del discorso quasi perfette dimostrate dalla curva rossa sono simili alle risposte ottenute dai soggetti con udito normale.
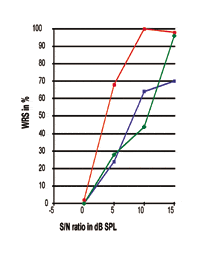 FIGURA 6. Tre curve individuali di performance-intensità con i loro punti del 50% a 3,35, 8,51, e 9,83 dB SPL rispettivamente. Quella rossa con il cerchio pieno, la cui pendenza e la massima prestazione di elaborazione del discorso sono simili a quelle raggiunte dai soggetti con udito normale, è realizzata da un individuo con lieve perdita uditiva sensorineurale ad alta frequenza, mentre le altre due curve sono ottenute da individui con perdita uditiva sensorineurale ad alta frequenza da moderata a grave.
FIGURA 6. Tre curve individuali di performance-intensità con i loro punti del 50% a 3,35, 8,51, e 9,83 dB SPL rispettivamente. Quella rossa con il cerchio pieno, la cui pendenza e la massima prestazione di elaborazione del discorso sono simili a quelle raggiunte dai soggetti con udito normale, è realizzata da un individuo con lieve perdita uditiva sensorineurale ad alta frequenza, mentre le altre due curve sono ottenute da individui con perdita uditiva sensorineurale ad alta frequenza da moderata a grave.
Questo potrebbe essere atteso, poiché i soggetti con lieve perdita uditiva sensorineurale possono soffrire di meno danni nel sistema orecchio-cervello. Per le curve ottenute da individui con SNHL ad alta frequenza da moderata a grave, si possono notare maggiori gradi di differenze individuali, come discusso in precedenza. Osservando queste due curve, si noti che quella con il miglior punto del 50% (curva blu), rispetto alla curva verde, non produce una migliore WRS. Questo indica che, nel mondo reale dove esistono variazioni individuali, un punto migliore del 50% (SRT) non è sempre associato a migliori prestazioni massime di elaborazione del discorso.
Sommario
1) Le prestazioni di elaborazione del discorso di un individuo sono influenzate dinamicamente da una serie di fattori tra cui il grado, il tipo, la forma della perdita uditiva, la durata della perdita uditiva, e molte altre condizioni fisiopatologiche nel sistema orecchio-cervello e anche l’abilità/profilo linguistico individuale.
2) La soglia di riconoscimento vocale è solo il punto del 50% dei dati sulla curva P-I delle prestazioni di elaborazione del discorso dei soggetti.
3) Un individuo al 50% del punto dei dati (SRT) sulla curva P-I potrebbe essere all’unità con un altro paziente, ma la pendenza e le prestazioni di elaborazione di questi due pazienti potrebbero essere completamente diverse tra loro.
4) La relazione tra il modello di risposta, l’SRT, la pendenza della curva P-I e la massima prestazione di elaborazione è estremamente dinamica e imprevedibile a causa della variabilità individuale.
5) Una risposta con un migliore SRT non è necessariamente associata a una migliore WRS. Anche se spesso sembra esserci un’ipotesi/approccio di lavoro nel nostro campo per usare il punto di dati del 50% per predire la massima prestazione di elaborazione del discorso, questo è in realtà uno sforzo senza fondamento clinico/teorico e precisione.
6) Quando si esegue l’adattamento dell’apparecchio acustico o dell’ALD, come la selezione, la modifica e la messa a punto, o quando si stabiliscono aspettative realistiche per i benefici dell’amplificazione, non si dovrebbe fare troppo affidamento sul punto dati del 50%. Invece, ottenere una curva P-I più completa con le massime prestazioni di elaborazione del discorso è un approccio più pragmatico per il clinico del mondo reale.
Esiste una cosa come una tipica perdita uditiva di 70 dB?
E’ evidente che le perdite uditive più gravi possono portare a variazioni abbastanza notevoli nel WRS. Le perdite uditive superiori a 70 dB sono spesso complesse e sfaccettate. Per esempio, i pazienti con punteggi SRT di 70 dB possono avere soglie di toni puri totalmente diverse nelle varie frequenze. In altre parole, i pazienti possono avere varie grandezze di perdita uditiva a discrete frequenze di tono puro, ma tutti possono sembrare avere una SRT intorno ai 70 dB HL. Gli individui possono anche avere diverse forme di audiogramma, tra cui una perdita uditiva piatta, inclinata, a bassa frequenza, ad alta frequenza, precipitosa, o anche a morso di biscotto, ma mostrano comunque un SRT di circa 70 dB HL.
Questo significa che la posizione e la gravità del danno sulla regione ad alta frequenza rispetto a quella a bassa frequenza (ad esempio, basale rispetto a quella apicale) della membrana basilare nell’orecchio interno potrebbe essere molto diversa tra questi soggetti. Inoltre, diversi gradi di danno sarebbero indotti sulla funzione attiva di amplificazione cocleare; la diversa elettromotilità delle cellule ciliate esterne porterebbe a diverse capacità di sensibilità uditiva e di discriminazione di frequenza dei segnali.6-9 Tutte queste condizioni patologiche comporterebbero un’elaborazione del segnale con scarsa sensibilità uditiva e ridotta analisi di frequenza, oltre a diverse quantità di distorsione nell’elaborazione di consonanti e vocali. E, a loro volta, queste condizioni si rifletterebbero in vari punteggi di riconoscimento vocale.
Se la patologia comporta più danni sulle cellule ciliate interne rispetto a quelle esterne, il suo effetto sull’elaborazione del segnale e la quantità di distorsione durante l’elaborazione del segnale sarebbe probabilmente maggiore e più alta, perché il 95% delle fibre nervose uditive trasportano informazioni dalle cellule ciliate interne mentre solo circa il 5% dei nervi uditivi innervano le cellule ciliate esterne.9-10 Quando la patologia si verifica più nella regione retrococleare che in quella cocleare, ci si potrebbe aspettare una maggiore quantità di perdita di chiarezza e il fenomeno del rollover nel riconoscimento del parlato. È anche noto che, con danni alle vie uditive superiori, i processi di livello superiore come la differenziazione uditiva figura-terra, l’integrazione binaurale, la separazione binaurale e la liberazione dal mascheramento potrebbero essere tutti interessati. Questo potrebbe anche portare ad un riconoscimento del parlato vario e apparentemente sproporzionatamente più povero nei compiti di ascolto nel rumore.11,12 Varie eziologie come l’infezione batterica/virus dell’orecchio interno, la perdita dell’udito indotta da rumore/farmaci, la circolazione sanguigna/fenomeno emorragico, il neuroma acustico, l’APD e la dissincronia uditiva, la malattia autoimmune dell’orecchio interno e l’ipoacusia ereditaria possono risultare in condizioni patologiche che producono diverse localizzazioni e gravità del danno sulle strutture sensoriali/neurali con conseguenti prestazioni di riconoscimento del parlato ancora associate a un SRT di 70 dB.11,12
Un altro fattore proviene dall’area di riorganizzazione tonotopica della corteccia uditiva di soggetti animali affetti da SNHL. È noto che, con la SNHL sostenuta nel tempo, si stabilisce un’area monotonica espansa nella corteccia uditiva in cui i neuroni hanno la loro frequenza caratteristica originale cambiata in una nuova frequenza (più bassa). Le loro curve di sintonizzazione mostrano soglie elevate, scarsa discriminazione di frequenza e ipersensibilità a frequenze diverse dalla loro frequenza caratteristica originale.13,14
È stato anche suggerito che questa riorganizzazione tonotopica, un effetto dovuto alla plasticità cerebrale in risposta alla stimolazione uditiva inadeguata e asimmetrica nel tempo, sia strettamente correlata alla deprivazione/adattamento uditivo in soggetti umani che hanno un povero WRS su parole e frasi monosillabiche, e anche con altre prestazioni di elaborazione del segnale di alto livello che coinvolgono la separazione binaurale e l’integrazione.13-17 Qui, per i soggetti della categoria con perdita uditiva di 70 dB, i loro diversi gradi di perdita uditiva attraverso le frequenze, le diverse posizioni/severità del danno, e molte altre variabili possono tutti sommarsi come fattori confondenti per la formazione della riorganizzazione tonotopica della corteccia uditiva.
Questo significa che, tra i soggetti di questa categoria, una diversa area monotona nella corteccia uditiva degli individui perde le sue capacità originali di elaborazione del segnale. Diventa sintonizzata su una frequenza diversa, varie percentuali di neuroni diventano meno sintonizzati, e possono verificarsi cambiamenti unici nella disposizione dei contorni di iso-frequenza nella corteccia, così come vari gradi di elevazione della soglia e ipersensibilità dei neuroni a frequenze diverse dalla loro frequenza migliore. Ci si dovrebbero quindi aspettare varie riduzioni nella discriminazione di frequenza e altre capacità di elaborazione neurologica superiore. Queste diverse caratteristiche della riorganizzazione tonotopica risultante, a sua volta, portano a variazioni nelle prestazioni dei soggetti nel rumore di fondo, elaborazione del segnale e risoluzioni di frequenza e intensità, il tutto con conseguenti differenze nel riconoscimento del discorso.
Inoltre, non c’è dubbio che l’abilità linguistica di ogni individuo è una grande macrovariabile nelle prestazioni di comprensione del discorso di quella persona. Le abilità linguistiche delle persone – le loro abilità nella forma semantica, nella struttura sintattica e nell’uso pragmatico del linguaggio, ecc. – differiscono e possono aiutarle o ostacolarle durante le interruzioni della comunicazione (per esempio, quando cercano di riempire gli spazi vuoti usando spunti linguistici e contestuali). Per coloro che rientrano nella categoria con perdita uditiva di 70dB, che hanno già difficoltà a capire il parlato, l’abilità linguistica sarebbe una macrovariabile che interagisce con la loro perdita uditiva e che influenza la WRS, specialmente quando la WRS viene misurata utilizzando materiali di frasi nel rumore di fondo. Inoltre, la complessità del profilo linguistico per le persone bilingui può essere aggravata da variabili come l’età di acquisizione della seconda lingua, la lingua dei genitori, l’origine geografica dell’acquisizione, l’uso della lingua, la durata dell’esposizione alla seconda lingua, ecc, e tutte queste variabili sono influenti nelle prestazioni di elaborazione del discorso/lingua, soprattutto durante i compiti di ascolto nel rumore.18-20
1. Lewis MS, Crandell CC. Applicazioni della tecnologia della modulazione di frequenza (FM). Presentato a: Il 17° Convegno annuale dell’Accademia Americana di Audiologia (corso didattico IC-103), Washington, DC;2005.
2. Von Hapsburg D, Pena E. Capire il bilinguismo e il suo impatto sull’audiometria vocale. J Speech Lang Hear Res. 2002; 45: 202-213.
3. Newby HA, Popelka GR. Audiologia. 6a ed. Englewood Cliffs, NJ: Prentice Hall Inc; 1992:126-201.
4. Stach BA. Audiologia clinica: An Introduction. San Diego, California: Singular Publishing Group Inc; 1998:193-249.
5. DeBonis DA, Donohue CL. Indagine sull’audiologia: Fundamentals for Audiologists and Health Professionals. Boston, Mass: Allyn and Bacon; 2004:77-164.
6. Brownell W, Bader C, Bertrand D, de Ribaupierre Y. Risposte meccaniche evocate delle cellule ciliate esterne cocleari isolate. Scienza. 1985;227(11):194-196.
7. Dallos P, Evans B, Hallworth R. Natura dell’elemento motore nei cambiamenti di forma elettrocinetici delle cellule ciliate esterne cocleari. Natura. 1991;350(14):155-157.
8. Dallos P, Martin R. La nuova teoria dell’udito. Hear Jour. 1994; 47(2):41-42.
9. Ryan AF. Nuovi punti di vista della funzione cocleare. In: Robinette MS, Glattke TJ, eds. Emissioni otoacustiche: Applicazioni cliniche. 1a ed. New York, NY: Thieme Medical Publishers Inc; 1997:22-45.
10. Gelfand SA. Udito: An Introduction to Psychological and Physiological Acoustics. 3a ed. New York, NY: Marcel Dekker Inc; 1998:47-82.
11. Mencher GT, Gerber SE, McCombe A. Audiology and Auditory Dysfunction. Needham Heights, Mass: Allyn and Bacon; 1997:105-232.
12. Martin FN, Clark JG. Introduzione all’audiologia. 9a ed. Boston, Mass: Allyn and Bacon; 2006:277-346.
13. Harrison RV, Nagasawa A, Smith DW, Stanton S, Mount RJ. Riorganizzazione della corteccia uditiva dopo la perdita uditiva cocleare neonatale ad alta frequenza. Hearing Res. 1991;54:11-19.
14. Dybala P. Effetti della perdita uditiva periferica sull’organizzazione tonotopica della corteccia uditiva. Hear Jour. 1997;50(9):49-54.
15. Silman S, Gelfand SA, Silverman CA. Tardiva privazione uditiva: Effetti degli apparecchi acustici monofonici rispetto a quelli binaurali. J Acoust Soc Amer. 1984;76(5):1357-1362.
16. Palmer CV. Deprivazione, acclimatazione, adattamento: Cosa significano per l’adattamento degli apparecchi acustici? Hear Jour. 1995;47(5):10,41-45.
17. Neuman AC. Deprivazione uditiva tardiva: Una revisione della ricerca passata e una valutazione dei bisogni futuri della ricerca. Ear Hear. 1996;17(3):3s-13s.
18. Grosjean F. Elaborazione del linguaggio misto: problemi, risultati e modelli. In: de Groot AMB, Kroll JF, eds. Tutorial in bilinguismo: Psycholinguistic Perspectives. Mahwah, NJ: Lawrence Erlbaum Associates; 1997:225-251.
19. Mayo LH, Florentine M, Buus S. Età di acquisizione della seconda lingua e percezione del discorso nel rumore. J Speech Lang Hear Res. 1997;40:686-693.
20. Von Hapsburg D, Champlin CA, Shetty SR. Soglie di ricezione per le frasi in ascoltatori bilingue (spagnolo/inglese) e monolingue (inglese). J Amer Acad Audiol. 2004;15(1):88-98.