Last Bijgewerkt op 27 januari 2021
Het kan voor beginners een uitdaging zijn om onderscheid te maken tussen verschillende gerelateerde computervisietaken.
Beeldclassificatie is bijvoorbeeld rechttoe rechtaan, maar de verschillen tussen objectlokalisatie en objectdetectie kunnen verwarrend zijn, vooral wanneer alle drie de taken net zo goed objectherkenning kunnen worden genoemd.
Beeldclassificatie omvat het toewijzen van een classificatielabel aan een afbeelding, terwijl objectlokalisatie het tekenen van een begrenzende box rond een of meer objecten in een afbeelding omvat. Objectdetectie is een grotere uitdaging en combineert deze twee taken en tekent een begrenzingskader rond elk object van belang in het beeld en kent ze een klasse-etiket toe. Samen worden al deze problemen objectherkenning genoemd.
In deze post ontdekt u een voorzichtige inleiding tot het probleem van objectherkenning en state-of-the-art deep learning-modellen die zijn ontworpen om het aan te pakken.
Na het lezen van deze post zult u weten:
- Objectherkenning verwijst naar een verzameling gerelateerde taken voor het identificeren van objecten in digitale foto’s.
- Region-Based Convolutional Neural Networks, of R-CNN’s, zijn een familie van technieken voor het aanpakken van objectlokalisatie en -herkenningstaken, ontworpen voor modelprestaties.
- You Only Look Once, of YOLO, is een tweede familie van technieken voor objectherkenning, ontworpen voor snelheid en real-time gebruik.
Kick-start uw project met mijn nieuwe boek Deep Learning for Computer Vision, inclusief stap-voor-stap tutorials en de Python-broncodebestanden voor alle voorbeelden.
Let’s get started.

Een voorzichtige inleiding tot objectherkenning met deep learning
Foto door Bart Everson, sommige rechten voorbehouden.
Overzicht
Deze tutorial is onderverdeeld in drie delen; deze zijn:
- Wat is Objectherkenning?
- R-CNN Model Family
- YOLO Model Family
Wilt u resultaten met Deep Learning voor Computer Vision?
Doe nu mijn gratis 7-daagse e-mail stoomcursus (met voorbeeldcode).
Klik om in te schrijven en ontvang ook een gratis PDF Ebook versie van de cursus.
Download Uw GRATIS Mini-Cursus
Wat is Objectherkenning?
Objectherkenning is een algemene term om een verzameling verwante computervisietaken te beschrijven die betrekking hebben op het identificeren van objecten in digitale foto’s.
Imageclassificatie omvat het voorspellen van de klasse van een object in een afbeelding. Object lokalisatie verwijst naar het identificeren van de locatie van een of meer objecten in een afbeelding en het tekenen van een omvattend kader rond hun omvang. Objectdetectie combineert deze twee taken en lokaliseert en classificeert een of meer objecten in een afbeelding.
Wanneer een gebruiker of beoefenaar verwijst naar “objectherkenning”, bedoelen zij vaak “objectdetectie”.
… we zullen de term objectherkenning ruim gebruiken om zowel beeldclassificatie (een taak waarbij een algoritme moet bepalen welke objectklassen in het beeld aanwezig zijn) als objectdetectie (een taak waarbij een algoritme alle in het beeld aanwezige objecten moet lokaliseren
– ImageNet Large Scale Visual Recognition Challenge, 2015.
Zo kunnen we onderscheid maken tussen deze drie computervisietaken:
- Beeldclassificatie: Voorspellen van het type of de klasse van een object in een afbeelding.
- Input: Een afbeelding met een enkel object, zoals een foto.
- Uitvoer: Een klassenlabel (bijv. een of meer gehele getallen die worden toegewezen aan klassenlabels).
- Objectlokalisatie: Lokaliseer de aanwezigheid van objecten in een afbeelding en geef hun locatie aan met een bounding box.
- Input: Een afbeelding met een of meer objecten, zoals een foto.
- Uitvoer: Een of meer bounding boxes (b.v. gedefinieerd door een punt, breedte en hoogte).
- Object Detection: Lokaliseren van de aanwezigheid van objecten met een bounding box en typen of klassen van de gelokaliseerde objecten in een afbeelding.
- Input: Een afbeelding met een of meer objecten, zoals een foto.
- Uitvoer: Een of meer bounding boxes (bijvoorbeeld gedefinieerd door een punt, breedte en hoogte), en een klassenlabel voor elke bounding box.
Een verdere uitbreiding op deze indeling van computervisietaken is objectsegmentatie, ook wel “object instance segmentation” of “semantische segmentatie” genoemd, waarbij instanties van herkende objecten worden aangegeven door de specifieke pixels van het object te markeren in plaats van een grove bounding box.
Uit deze uitsplitsing kunnen we opmaken dat objectherkenning verwijst naar een reeks uitdagende computervisietaken.
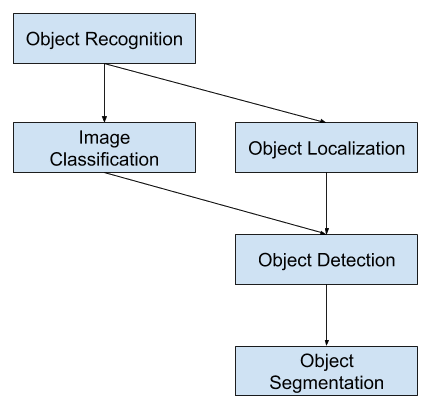
Overzicht van computer vision-taken voor objectherkenning
De meeste recente innovaties in beeldherkenningsproblemen zijn voortgekomen uit deelname aan de ILSVRC-taken.
Dit is een jaarlijkse academische competitie met een aparte uitdaging voor elk van deze drie probleemtypen, met de bedoeling om op elk niveau onafhankelijke en afzonderlijke verbeteringen te stimuleren die breder kunnen worden ingezet. Zie bijvoorbeeld de lijst van de drie corresponderende taaktypen hieronder, afkomstig uit het ILSVRC-review paper van 2015:
- Beeldclassificatie: Algoritmen produceren een lijst van objectcategorieën die in het beeld aanwezig zijn.
- Lokalisatie van afzonderlijke objecten: Algoritmen produceren een lijst van in het beeld aanwezige objectcategorieën, samen met een as-georiënteerde bounding box die de positie en schaal van een instantie van elke objectcategorie aangeeft.
- Objectdetectie: Algoritmen produceren een lijst van objectcategorieën aanwezig in het beeld, samen met een as-georiënteerde bounding box die de positie en de schaal van elke instantie van elke objectcategorie aangeeft.
We zien dat “lokalisatie van afzonderlijke objecten” een eenvoudiger versie is van de breder gedefinieerde “lokalisatie van objecten”, waarbij de lokalisatietaken worden beperkt tot objecten van één type binnen een beeld, waarvan we mogen aannemen dat het een eenvoudiger taak is.
Hieronder ziet u een voorbeeld waarin lokalisatie van afzonderlijke objecten wordt vergeleken met objectdetectie, afkomstig uit het ILSVRC-document. Let op het verschil in grondwaarheidsverwachtingen in beide gevallen.
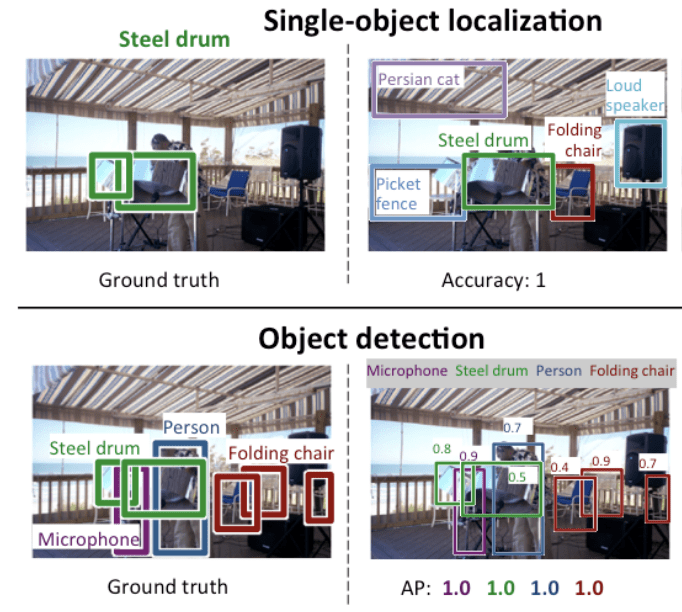
Vergelijking tussen lokalisatie van afzonderlijke objecten en objectdetectie.Genomen uit: ImageNet Large Scale Visual Recognition Challenge.
De prestaties van een model voor beeldclassificatie worden geëvalueerd aan de hand van de gemiddelde classificatiefout over de voorspelde klassenlabels. De prestaties van een model voor objectlokalisatie worden geëvalueerd aan de hand van de afstand tussen de verwachte en de voorspelde begrenzing voor de verwachte klasse. Terwijl de prestaties van een model voor objectherkenning worden geëvalueerd met behulp van de precisie en recall over elk van de best overeenkomende bounding boxes voor de bekende objecten in het beeld.
Nu we bekend zijn met het probleem van objectlokalisatie en -detectie, laten we eens kijken naar een aantal recente top-presterende deep learning-modellen.
R-CNN Model Family
De R-CNN-familie van methoden verwijst naar de R-CNN, wat kan staan voor “Regio’s met CNN-functies” of “Region-Based Convolutional Neural Network,” ontwikkeld door Ross Girshick, et al.
Dit omvat de technieken R-CNN, Fast R-CNN, en Faster-RCNN ontworpen en gedemonstreerd voor objectlokalisatie en objectherkenning.
Laten we de hoogtepunten van elk van deze technieken op hun beurt nader bekijken.
R-CNN
Het R-CNN werd beschreven in de paper uit 2014 van Ross Girshick, et al. van UC Berkeley getiteld “Rich feature hierarchies for accurate object detection and semantic segmentation.”
Het was mogelijk een van de eerste grote en succesvolle toepassingen van convolutionele neurale netwerken op het probleem van objectlokalisatie, -detectie en -segmentatie. De aanpak werd gedemonstreerd op benchmark datasets, waarbij vervolgens state-of-the-art resultaten werden bereikt op de VOC-2012 dataset en de 200-klasse ILSVRC-2013 objectdetectie dataset.
Hun voorgestelde R-CNN-model bestaat uit drie modules; ze zijn:
- Module 1: Regio Voorstellen. Genereert en extraheert categorie-onafhankelijke regiovoorstellen, b.v. kandidaat-grensvlakken.
- Module 2: Feature Extractor. Extraheer kenmerken uit elke kandidaat-regio, b.v. met behulp van een diep convolutie neuraal netwerk.
- Module 3: Classificator. Classificeer kenmerken als een van de bekende klasse, bijvoorbeeld lineaire SVM classifier model.
De architectuur van het model is samengevat in de afbeelding hieronder, overgenomen uit de paper.
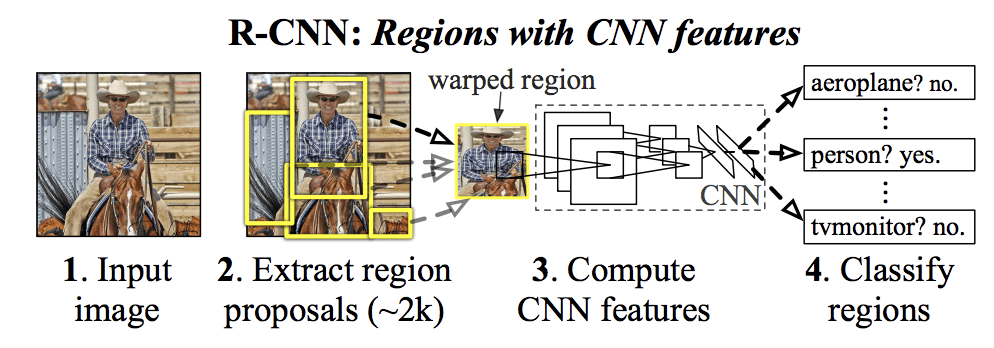
Samenvatting van de R-CNN Model ArchitectuurGehaald uit Rich feature hiërarchieën voor nauwkeurige object detectie en semantische segmentatie.
Een computervisietechniek wordt gebruikt om kandidaat-regio’s of bounding boxes van potentiële objecten in het beeld voor te stellen, “selectief zoeken” genaamd, hoewel de flexibiliteit van het ontwerp het mogelijk maakt andere algoritmen voor het voorstellen van regio’s te gebruiken.
De door het model gebruikte feature-extractor was het AlexNet deep CNN dat de ILSVRC-2012-beeldclassificatiewedstrijd won. De uitvoer van de CNN was een vector van 4.096 elementen die de inhoud van het beeld beschrijft en die wordt toegevoerd aan een lineaire SVM voor classificatie, waarbij specifiek één SVM wordt getraind voor elke bekende klasse.
Het is een relatief eenvoudige en ongecompliceerde toepassing van CNN’s op het probleem van objectlokalisatie en -herkenning. Een nadeel van de aanpak is dat hij traag is, omdat een op CNN gebaseerde eigenschap-extractie nodig is voor elk van de kandidaat-regio’s die door het regio-voorstelalgoritme worden gegenereerd. Dit is een probleem omdat de paper beschrijft dat het model werkt op ongeveer 2.000 voorgestelde regio’s per beeld op test-tijd.
Python (Caffe) en MatLab broncode voor R-CNN zoals beschreven in de paper werd beschikbaar gesteld in de R-CNN GitHub repository.
Snel R-CNN
Gezien het grote succes van R-CNN, stelde Ross Girshick, toen bij Microsoft Research, een uitbreiding voor om de snelheidsproblemen van R-CNN aan te pakken in een paper uit 2015, getiteld “Snel R-CNN.”
The paper opent met een overzicht van de beperkingen van R-CNN, die als volgt kunnen worden samengevat:
- Training is een pijplijn met meerdere fasen.
- Training is duur in ruimte en tijd. Trainen van een deep CNN op zoveel regiovoorstellen per beeld is erg traag.
- Objectdetectie is traag. Voorspellingen doen met behulp van een diepe CNN op zoveel regiovoorstellen is erg traag.
Er is eerder werk voorgesteld om de techniek, genaamd spatial pyramid pooling networks, of SPPnets, te versnellen in de paper uit 2014 “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.” Dit versnelde wel de extractie van features, maar gebruikte in wezen een soort forward pass caching algoritme.
Fast R-CNN wordt voorgesteld als een enkel model in plaats van een pijplijn om regio’s en classificaties direct te leren en uit te voeren.
De architectuur van het model neemt de foto een set regiovoorstellen als invoer die door een diep convolutioneel neuraal netwerk worden geleid. Een vooraf getraind CNN, zoals een VGG-16, wordt gebruikt voor feature-extractie. Het einde van de diepe CNN is een aangepaste laag, een zogenaamde Region of Interest Pooling Layer, of RoI Pooling, die specifieke kenmerken extraheert voor een gegeven kandidaat-regio van invoer.
De output van de CNN wordt vervolgens geïnterpreteerd door een volledig aangesloten laag, waarna het model splitst in twee outputs, een voor de klassevoorspelling via een softmax-laag, en een andere met een lineaire output voor de begrenzingsbox. Dit proces wordt vervolgens meerdere malen herhaald voor elk interessegebied in een gegeven afbeelding.
De architectuur van het model wordt samengevat in de onderstaande afbeelding, afkomstig uit de paper.
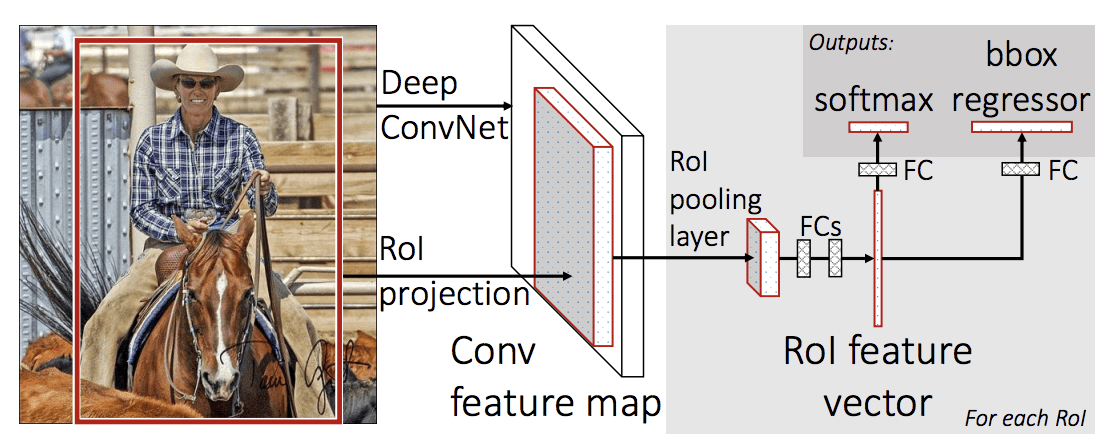
Samenvatting van de Architectuur van het Fast R-CNN Model.
Opgenomen uit: Fast R-CNN.Het model is aanzienlijk sneller te trainen en voorspellingen te doen, maar vereist nog steeds dat bij elk invoerbeeld een reeks kandidaatregio’s wordt voorgesteld.
Python en C++ (Caffe) broncode voor Fast R-CNN zoals beschreven in de paper werd beschikbaar gesteld in een GitHub repository.
Faster R-CNN
De modelarchitectuur werd verder verbeterd voor zowel snelheid van training en detectie door Shaoqing Ren, et al. bij Microsoft Research in de 2016 paper getiteld “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.”
De architectuur vormde de basis voor de eerste-plaats resultaten behaald op zowel de ILSVRC-2015 en MS COCO-2015 objectherkenning en detectie competitie taken.
De architectuur is ontworpen om zowel regio-voorstellen voor te stellen en te verfijnen als onderdeel van het trainingsproces, aangeduid als een Region Proposal Network, of RPN. Deze regio’s worden vervolgens gebruikt in combinatie met een Fast R-CNN model in een enkel modelontwerp. Deze verbeteringen verminderen zowel het aantal regiovoorstellen als de werking van het model in testtijd tot bijna real-time met dan state-of-the-art prestaties.
… ons detectiesysteem heeft een framerate van 5fps (inclusief alle stappen) op een GPU, terwijl het state-of-the-art objectdetectienauwkeurigheid bereikt op PASCAL VOC 2007, 2012, en MS COCO datasets met slechts 300 voorstellen per beeld. In ILSVRC- en COCO 2015-wedstrijden liggen Faster R-CNN en RPN aan de basis van de winnende inzendingen voor de eerste plaats in verschillende tracks
– Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
Hoewel het een enkel verenigd model is, bestaat de architectuur uit twee modules:
- Module 1: Netwerk voor regio-voorstellen. Convolutioneel neuraal netwerk voor het voorstellen van regio’s en het type object dat in de regio in aanmerking moet worden genomen.
- Module 2: Fast R-CNN. Convolutioneel neuraal netwerk voor het extraheren van kenmerken uit de voorgestelde regio’s en het produceren van de bounding box en klasse-labels.
Beide modules werken op dezelfde output van een diepe CNN. Het netwerk voor het voorstellen van regio’s fungeert als een aandachtsmechanisme voor het snelle R-CNN-netwerk, dat het tweede netwerk informeert over waar het moet kijken of waar het aandacht aan moet besteden.
De architectuur van het model wordt samengevat in de onderstaande afbeelding, afkomstig uit het artikel.
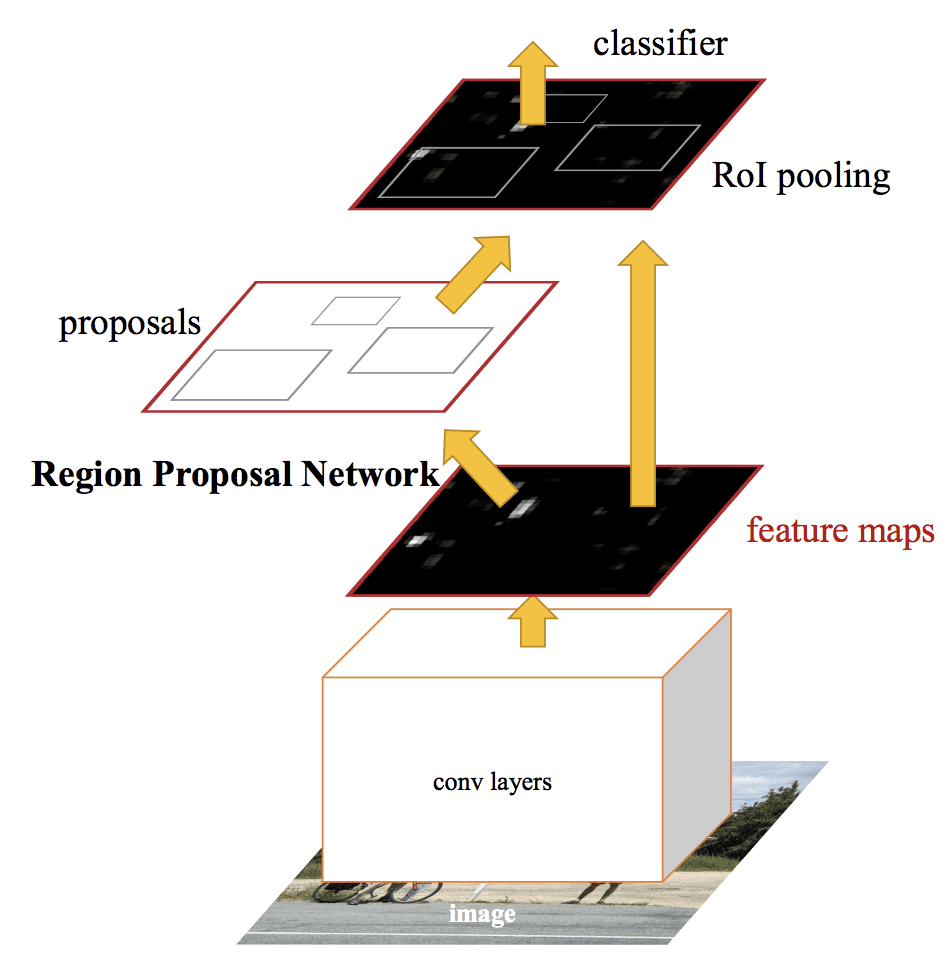
Samenvatting van de modelarchitectuur van het snellere R-CNN.overgenomen uit: Faster R-CNN: Towards Real-Time Object Detection With Region Proposal Networks.
De RPN werkt door de output van een voorgetrainde diepe CNN, zoals VGG-16, te nemen en een klein netwerk over de feature map te laten gaan en meerdere regiovoorstellen en een klassevoorspelling voor elk te produceren. Voorstellen voor regio’s zijn bounding boxes, gebaseerd op zogenaamde ankerboxen of voorgedefinieerde vormen die zijn ontworpen om het voorstellen van regio’s te versnellen en te verbeteren. De klassevoorspelling is binair en geeft de aanwezigheid van een object aan of niet, de zogenaamde “objectness” van de voorgestelde regio.
Er wordt gebruik gemaakt van een procedure van alternerende training waarbij beide subnetwerken tegelijkertijd worden getraind, zij het interleaved. Hierdoor kunnen de parameters in de feature detector deep CNN voor beide taken tegelijk worden aangepast of verfijnd.
Op het moment van schrijven is deze Faster R-CNN architectuur het summum van de familie van modellen en behaalt zij nog steeds bijna state-of-the-art resultaten op objectherkenningstaken. Een verdere uitbreiding voegt ondersteuning toe voor beeldsegmentatie, beschreven in de paper 2017 paper “Mask R-CNN.”
Python en C++ (Caffe) broncode voor Fast R-CNN zoals beschreven in de paper werd beschikbaar gesteld in een GitHub repository.
YOLO Model Family
Een andere populaire familie van objectherkenningsmodellen wordt collectief aangeduid als YOLO of “You Only Look Once,” ontwikkeld door Joseph Redmon, et al.
De R-CNN-modellen kunnen over het algemeen nauwkeuriger zijn, maar de YOLO-familie van modellen zijn snel, veel sneller dan R-CNN, en bereiken objectdetectie in realtime.
YOLO
Het YOLO-model werd voor het eerst beschreven door Joseph Redmon, et al. in de paper uit 2015 met de titel “You Only Look Once: Unified, Real-Time Object Detection.” Merk op dat Ross Girshick, ontwikkelaar van R-CNN, ook een auteur en bijdrager aan dit werk was, toen bij Facebook AI Research.
De aanpak omvat een enkel neuraal netwerk dat van begin tot eind is getraind en dat een foto als invoer neemt en direct bounding boxes en klasse-labels voor elke bounding box voorspelt. De techniek biedt een lagere voorspellende nauwkeurigheid (bijv. meer lokalisatiefouten), maar werkt met 45 beelden per seconde en tot 155 beelden per seconde voor een voor snelheid geoptimaliseerde versie van het model.
Onze verenigde architectuur is extreem snel. Ons basis YOLO-model verwerkt beelden in real-time met 45 beelden per seconde. Een kleinere versie van het netwerk, Fast YOLO, verwerkt een verbazingwekkende 155 beelden per seconde …
– You Only Look Once: Unified, Real-Time Object Detection, 2015.
Het model werkt door het inputbeeld eerst op te splitsen in een raster van cellen, waarbij elke cel verantwoordelijk is voor het voorspellen van een bounding box als het middelpunt van een bounding box binnen de cel valt. Elke rastercel voorspelt een bounding box met de x-, y-coördinaat en de breedte en hoogte en het vertrouwen. Een klassevoorspelling is ook gebaseerd op elke cel.
Een afbeelding kan bijvoorbeeld worden verdeeld in een raster van 7×7 en elke cel in het raster kan 2 bounding boxes voorspellen, wat resulteert in 94 voorgestelde bounding box-voorspellingen. De klassenwaarschijnlijkheidskaart en de bounding boxes met confidenties worden dan gecombineerd tot een uiteindelijke set van bounding boxes en klasse-labels. De onderstaande afbeelding uit de paper vat de twee outputs van het model samen.
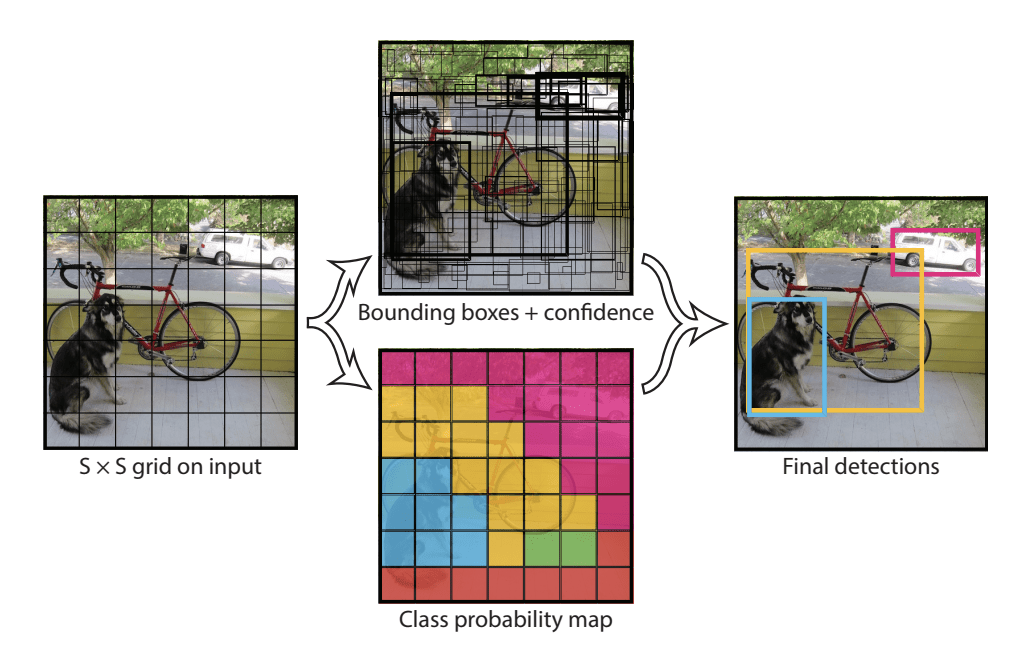
Samenvatting van voorspellingen gedaan door YOLO-model.Overgenomen uit: You Only Look Once: Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) en YOLOv3
Het model werd bijgewerkt door Joseph Redmon en Ali Farhadi in een poging om de prestaties van het model verder te verbeteren in hun paper uit 2016 met de titel “YOLO9000: Better, Faster, Stronger.”
Hoewel deze variant van het model wordt aangeduid als YOLO v2, wordt een instantie van het model beschreven die parallel werd getraind op twee objectherkenningsdatasets, in staat om 9.000 objectklassen te voorspellen, vandaar de naam “YOLO9000.”
Er zijn een aantal trainings- en architectuurwijzigingen in het model aangebracht, zoals het gebruik van batchnormalisatie en invoerbeelden met hoge resolutie.
Net als Faster R-CNN maakt het YOLOv2-model gebruik van ankerdozen, vooraf gedefinieerde bounding boxes met bruikbare vormen en maten die tijdens de training worden aangepast. De keuze van de bounding boxes voor de afbeelding wordt voorbewerkt met behulp van een k-means analyse op de trainingsdataset.
Belangrijk is dat de voorspelde representatie van de bounding boxes wordt gewijzigd, zodat kleine veranderingen een minder dramatisch effect hebben op de voorspellingen, wat resulteert in een stabieler model. In plaats van de positie en grootte rechtstreeks te voorspellen, worden offsets voorspeld voor het verplaatsen en opnieuw vormgeven van de vooraf gedefinieerde ankervakken ten opzichte van een rastercel en worden deze gedempt door een logistische functie.
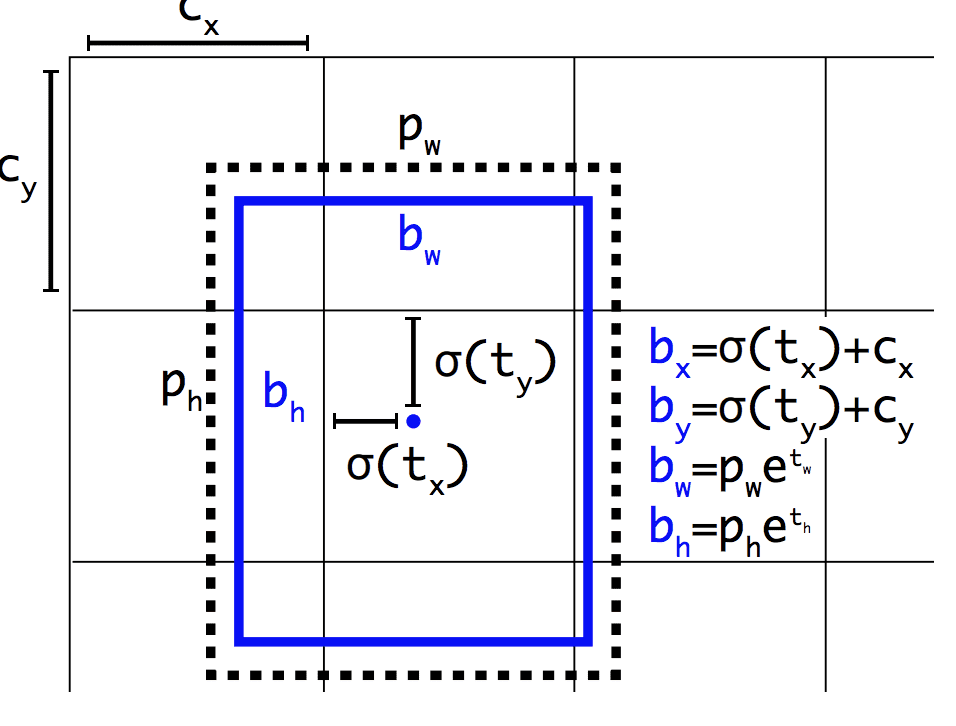
Voorbeeld van de weergave die wordt gekozen bij het voorspellen van de positie en vorm van grensvakkenOpgenomen uit: YOLO9000: Better, Faster, Stronger
Verdere verbeteringen aan het model werden voorgesteld door Joseph Redmon en Ali Farhadi in hun paper uit 2018 getiteld “YOLOv3: An Incremental Improvement.” De verbeteringen waren redelijk klein, waaronder een dieper feature detector netwerk en kleine representatieve veranderingen.
Verder lezen
Deze sectie biedt meer bronnen over het onderwerp als u op zoek bent om dieper te gaan.
Papers
- ImageNet Large Scale Visual Recognition Challenge, 2015.
R-CNN Family Papers
- Rich feature hierarchies for accurate object detection and semantic segmentation, 2013.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, 2014.
- Fast R-CNN, 2015.
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
- Mask R-CNN, 2017.
YOLO Family Papers
- You Only Look Once: Unified, Real-Time Object Detection, 2015.
- YOLO9000: Better, Faster, Stronger, 2016.
- YOLOv3: An Incremental Improvement, 2018.
Code Projects
- R-CNN: Regions with Convolutional Neural Network Features, GitHub.
- Snelle R-CNN, GitHub.
- Snellere R-CNN Python Code, GitHub.
- YOLO, GitHub.
Resources
- Ross Girshick, Homepage.
- Joseph Redmon, Homepage.
- YOLO: Real-Time Object Detection, Homepage.
Artikelen
- Een korte geschiedenis van CNNs in beeldsegmentatie: From R-CNN to Mask R-CNN, 2017.
- Object Detection for Dummies Part 3: R-CNN Family, 2017.
- Object Detection Part 4: Fast Detection Models, 2018.
Summary
In deze post ontdekte u een voorzichtige inleiding tot het probleem van objectherkenning en state-of-the-art deep learning-modellen die zijn ontworpen om het aan te pakken.
Specifiek, u leerde:
- Objectherkenning verwijst naar een verzameling gerelateerde taken voor het identificeren van objecten in digitale foto’s.
- Region-Based Convolutional Neural Networks, of R-CNN’s, zijn een familie van technieken voor het aanpakken van objectlokalisatie en -herkenningstaken, ontworpen voor modelprestaties.
- You Only Look Once, of YOLO, is een tweede familie van technieken voor objectherkenning, ontworpen voor snelheid en real-time gebruik.
Heeft u vragen?
Stel uw vragen in de commentaren hieronder en ik zal mijn best doen om ze te beantwoorden.Ontwikkel vandaag Deep Learning-modellen voor Vision!

Ontwikkel uw eigen Vision-modellen in enkele minuten
…met slechts een paar regels python code
Ontdek hoe in mijn nieuwe Ebook:
Deep Learning for Computer VisionHet biedt zelfstudie tutorials over onderwerpen als:
classificatie, objectdetectie (yolo en rcnn), gezichtsherkenning (vggface en facenet), datavoorbereiding en nog veel meer…Breng Deep Learning eindelijk naar uw Vision-projecten
Skip de academici. Alleen resultaten.
See What’s Inside
Tweet Share Share