Kolmogorov-Smirnov (KS)-statistiek is een van de belangrijkste meeteenheden die worden gebruikt voor het valideren van voorspellende modellen. Het wordt veel gebruikt in het BFSI-domein. Als u deel uitmaakt van een risico- of marketinganalyseteam dat aan een project in het bankwezen werkt, moet u over deze metriek hebben gehoord.
Wat is KS-statistiek?
Het staat voor Kolmogorov-Smirnov, dat is vernoemd naar Andrey Kolmogorov en Nikolai Smirnov. Het vergelijkt de twee cumulatieve verdelingen en geeft het maximale verschil tussen beide. Het is een niet-parametrische test, wat betekent dat u geen veronderstelling hoeft te testen met betrekking tot de verdeling van de gegevens. In de KS-test stelt de nulhypothese dat beide cumulatieve verdelingen gelijk zijn. Verwerpen van de nulhypothese betekent dat de cumulatieve verdelingen verschillend zijn.
In de gegevenswetenschap vergelijkt het de cumulatieve verdeling van gebeurtenissen en niet-gebeurtenissen en KS is waar er een maximaal verschil is tussen de twee verdelingen. In eenvoudige woorden, het helpt ons om te begrijpen hoe goed ons voorspellende model in staat is om onderscheid te maken tussen gebeurtenissen en niet-gebeurtenissen.
Voorstel dat u een propensity model aan het bouwen bent waarbij het doel is om prospects te identificeren die waarschijnlijk een bepaald product zullen kopen. In dit geval heeft de afhankelijke (doel)variabele een binaire vorm met slechts twee uitkomsten: 0 (non-event) of 1 (event). “Gebeurtenis” betekent mensen die het product hebben gekocht. “Niet-gebeurtenis” verwijst naar mensen die het product niet hebben gekocht. KS Statistiek meet of model in staat is onderscheid te maken tussen prospects en niet-prospects.
Twee manieren om KS Statistiek te meten
Deze methode is de meest gebruikelijke manier om KS statistiek te berekenen voor het valideren van binair voorspellend model. Zie de stappen hieronder.
- U moet twee variabelen hebben voordat u KS berekent. Een daarvan is de afhankelijke variabele, die binair moet zijn. De tweede is de voorspelde waarschijnlijkheidsscore die uit het statistische model wordt gegenereerd.
- Maak decielen op basis van de voorspelde waarschijnlijkheidskolommen, wat betekent dat de waarschijnlijkheid in 10 delen wordt verdeeld. Het eerste deciel moet de hoogste waarschijnlijkheidsscore bevatten.
- Bereken het cumulatieve % gebeurtenissen en niet-gebeurtenissen in elk deciel en bereken vervolgens het verschil tussen deze twee cumulatieve verdelingen.
- KS is waar het verschil maximaal is
- Als KS in de top 3 van het deciel ligt en een score van meer dan 40 heeft, wordt het beschouwd als een goed voorspellend model. Tegelijkertijd is het belangrijk om het model te valideren door ook andere prestatiecijfers te controleren om te bevestigen dat het model niet lijdt aan overfitting.
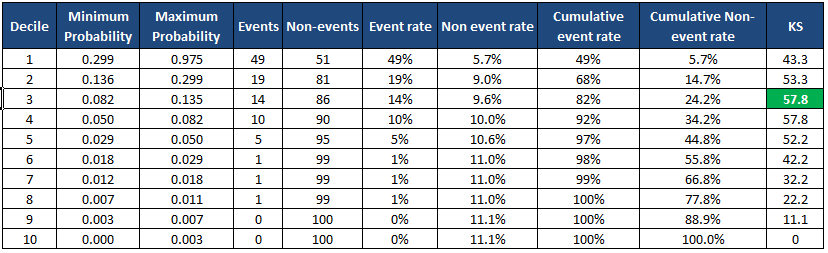
Python : KS Statistics Decile Method
Ik heb als voorbeeld een voorbeelddataset voorbereid. De dataset bevat twee kolommen genaamd y en p.yis een afhankelijke variabele.pverwijst naar de voorspelde waarschijnlijkheid.
import pandas as pdimport numpy as npdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
def ks(data=None,target=None, prob=None): data = 1 - data data = pd.qcut(data, 10) grouped = data.groupby('bucket', as_index = False) kstable = pd.DataFrame() kstable = grouped.min() kstable = grouped.max() kstable = grouped.sum() kstable = grouped.sum() kstable = kstable.sort_values(by="min_prob", ascending=False).reset_index(drop = True) kstable = (kstable.events / data.sum()).apply('{0:.2%}'.format) kstable = (kstable.nonevents / data.sum()).apply('{0:.2%}'.format) kstable=(kstable.events / data.sum()).cumsum() kstable=(kstable.nonevents / data.sum()).cumsum() kstable = np.round(kstable-kstable, 3) * 100 #Formating kstable= kstable.apply('{0:.2%}'.format) kstable= kstable.apply('{0:.2%}'.format) kstable.index = range(1,11) kstable.index.rename('Decile', inplace=True) pd.set_option('display.max_columns', 9) print(kstable) #Display KS from colorama import Fore print(Fore.RED + "KS is " + str(max(kstable))+"%"+ " at decile " + str((kstable.index==max(kstable)]))) return(kstable)
mydf = ks(data=df,target="y", prob="p")
-
dataverwijst naar pandas dataframe dat zowel de afhankelijke variabele als de waarschijnlijkheidsscores bevat. -
targetverwijst naar kolomnaam van afhankelijke variabele -
probverwijst naar kolomnaam van voorspelde waarschijnlijkheid
Het retourneert informatie van elk deciel in tabelformaat en drukt ook de KS score onder de tabel af. Het genereert ook de tabel in een nieuw dataframe.
min_prob max_prob events nonevents event_rate nonevent_rate \Decile 1 0.298894 0.975404 49 51 49.00% 5.67% 2 0.135598 0.298687 19 81 19.00% 9.00% 3 0.082170 0.135089 14 86 14.00% 9.56% 4 0.050369 0.082003 10 90 10.00% 10.00% 5 0.029415 0.050337 5 95 5.00% 10.56% 6 0.018343 0.029384 1 99 1.00% 11.00% 7 0.011504 0.018291 1 99 1.00% 11.00% 8 0.006976 0.011364 1 99 1.00% 11.00% 9 0.002929 0.006964 0 100 0.00% 11.11% 10 0.000073 0.002918 0 100 0.00% 11.11% cum_eventrate cum_noneventrate KS Decile 1 49.00% 5.67% 43.3 2 68.00% 14.67% 53.3 3 82.00% 24.22% 57.8 4 92.00% 34.22% 57.8 5 97.00% 44.78% 52.2 6 98.00% 55.78% 42.2 7 99.00% 66.78% 32.2 8 100.00% 77.78% 22.2 9 100.00% 88.89% 11.1 10 100.00% 100.00% 0.0 KS is 57.8% at decile 3
Met behulp vanscipypython bibliotheek, kunnen we twee sample KS Statistic berekenen. Het heeft twee parameters – data1 en data2. In data1, zullen we alle waarschijnlijkheidsscores invoeren die overeenkomen met niet-gebeurtenissen. In data2, het zal waarschijnlijkheid scores tegen gebeurtenissen nemen.
from scipy.stats import ks_2sampdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")ks_2samp(df.loc, df.loc)
Het geeft KS score 0,6033 en p-waarde minder dan 0,01 wat betekent dat we de nulhypothese kunnen verwerpen en concluderen distributie van gebeurtenissen en niet-gebeurtenissen is verschillend.
OutputKs_2sampResult(statistic=0.6033333333333333, pvalue=1.1227180680661939e-29)
De KS score van methode 2 is iets anders dan methode 1 omdat de tweede wordt berekend op rijniveau en de eerste wordt berekend na het omzetten van gegevens in tien delen.