Last Updated on January 27, 2021
Dla początkujących może być wyzwaniem rozróżnienie pomiędzy różnymi powiązanymi zadaniami widzenia komputerowego.
Na przykład klasyfikacja obrazów jest prosta, ale różnice między lokalizacją obiektów a wykrywaniem obiektów mogą być mylące, zwłaszcza gdy wszystkie trzy zadania mogą być równie dobrze określane jako rozpoznawanie obiektów.
Klasyfikacja obrazów obejmuje przypisanie etykiety klasy do obrazu, podczas gdy lokalizacja obiektów obejmuje rysowanie ramki wokół jednego lub więcej obiektów na obrazie. Wykrywanie obiektów jest bardziej wymagające i łączy te dwa zadania i rysuje ramkę wokół każdego obiektu zainteresowania na obrazie i przypisuje im etykietę klasy. Łącznie wszystkie te problemy są określane jako rozpoznawanie obiektów.
W tym poście odkryjesz delikatne wprowadzenie do problemu rozpoznawania obiektów i najnowocześniejszych modeli głębokiego uczenia zaprojektowanych do jego rozwiązania.
Po przeczytaniu tego postu będziesz wiedział:
- Rozpoznawanie obiektów odnosi się do zbioru powiązanych zadań identyfikacji obiektów na zdjęciach cyfrowych.
- Region-Based Convolutional Neural Networks, lub R-CNNs, to rodzina technik do rozwiązywania zadań lokalizacji i rozpoznawania obiektów, zaprojektowana z myślą o wydajności modelu.
- You Only Look Once, lub YOLO, to druga rodzina technik rozpoznawania obiektów zaprojektowana z myślą o szybkości i wykorzystaniu w czasie rzeczywistym.
Zacznij swój projekt dzięki mojej nowej książce Deep Learning for Computer Vision, zawierającej samouczki krok po kroku oraz pliki z kodem źródłowym Pythona dla wszystkich przykładów.
Zacznijmy.

Delikatne wprowadzenie do rozpoznawania obiektów za pomocą głębokiego uczenia
Zdjęcie autorstwa Barta Eversona, pewne prawa zastrzeżone.
Przegląd
Tutorial ten jest podzielony na trzy części; są to:
- Co to jest rozpoznawanie obiektów?
- R-CNN Model Family
- YOLO Model Family
Chcesz wyników z głębokim uczeniem dla wizji komputerowej?
Weź udział w moim darmowym 7-dniowym kursie e-mailowym (z przykładowym kodem).
Kliknij, aby się zapisać i otrzymać darmową wersję PDF Ebook kursu.
Ściągnij swój DARMOWY mini-kurs
Czym jest rozpoznawanie obiektów?
Rozpoznawanie obiektów to ogólny termin opisujący zbiór powiązanych zadań widzenia komputerowego, które obejmują identyfikację obiektów na fotografiach cyfrowych.
Klasyfikacja obrazu obejmuje przewidywanie klasy jednego obiektu na obrazie. Lokalizowanie obiektów odnosi się do identyfikacji lokalizacji jednego lub więcej obiektów na obrazie i rysowania obwiedni wokół ich zasięgu. Wykrywanie obiektów łączy te dwa zadania i lokalizuje i klasyfikuje jeden lub więcej obiektów w obrazie.
Gdy użytkownik lub praktyk odnosi się do „rozpoznawania obiektów”, często ma na myśli „wykrywanie obiektów”.
… będziemy używać terminu rozpoznawanie obiektów szeroko, aby objąć zarówno klasyfikację obrazu (zadanie wymagające algorytmu do określenia, jakie klasy obiektów są obecne w obrazie), jak i wykrywanie obiektów (zadanie wymagające algorytmu do zlokalizowania wszystkich obiektów obecnych w obrazie
– ImageNet Large Scale Visual Recognition Challenge, 2015.
Jako takie, możemy rozróżnić te trzy zadania widzenia komputerowego:
- Klasyfikacja obrazu: Przewidywanie typu lub klasy obiektu na obrazie.
- Dane wejściowe: Obraz z pojedynczym obiektem, np. zdjęcie.
- Dane wyjściowe: Etykieta klasy (np. jedna lub więcej liczb całkowitych, które są odwzorowane na etykiety klas).
- Lokalizacja obiektów: Lokalizowanie obecności obiektów w obrazie i wskazywanie ich położenia za pomocą bounding box.
- Dane wejściowe: Obraz z jednym lub większą liczbą obiektów, np. fotografia.
- Dane wyjściowe: Jedna lub więcej skrzynek ograniczających (np. zdefiniowanych przez punkt, szerokość i wysokość).
- Wykrywanie obiektów: Lokalizowanie obecności obiektów za pomocą bounding box oraz typów lub klas zlokalizowanych obiektów w obrazie.
- Dane wejściowe: Obraz z jednym lub więcej obiektami, np. zdjęcie.
- Dane wyjściowe: Jedno lub więcej pudełek ograniczających (np. zdefiniowanych przez punkt, szerokość i wysokość) oraz etykieta klasy dla każdego pudełka ograniczającego.
Jednym z dalszych rozszerzeń tego podziału zadań widzenia komputerowego jest segmentacja obiektów, zwana również „segmentacją instancji obiektu” lub „segmentacją semantyczną”, w której instancje rozpoznanych obiektów są wskazywane przez wyróżnienie konkretnych pikseli obiektu zamiast grubego pudełka ograniczającego.
Z tego podziału możemy zobaczyć, że rozpoznawanie obiektów odnosi się do zestawu trudnych zadań widzenia komputerowego.
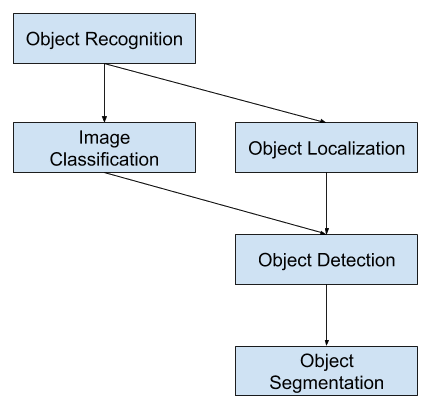
Overview of Object Recognition Computer Vision Tasks
Większość ostatnich innowacji w problemach rozpoznawania obrazów pojawiła się w ramach uczestnictwa w zadaniach ILSVRC.
Jest to coroczny konkurs akademicki z oddzielnym wyzwaniem dla każdego z tych trzech typów problemów, z zamiarem wspierania niezależnych i oddzielnych ulepszeń na każdym poziomie, które mogą być wykorzystywane szerzej. Na przykład, zobacz listę trzech odpowiadających sobie typów zadań poniżej, zaczerpniętą z dokumentu przeglądowego 2015 ILSVRC:
- Klasyfikacja obrazów: Algorytmy produkują listę kategorii obiektów obecnych w obrazie.
- Lokalizacja pojedynczych obiektów: Algorytmy wytwarzają listę kategorii obiektów obecnych w obrazie wraz z wyrównaną względem osi ramką ograniczającą, wskazującą położenie i skalę jednej instancji każdej kategorii obiektów.
- Wykrywanie obiektów: Algorytmy wytwarzają listę kategorii obiektów obecnych w obrazie wraz z wyrównaną do osi ramką ograniczającą wskazującą położenie i skalę każdej instancji każdej kategorii obiektów.
Widzimy, że „Lokalizacja pojedynczego obiektu” jest prostszą wersją szerzej zdefiniowanej „Lokalizacji obiektu”, ograniczając zadania lokalizacyjne do obiektów jednego typu w obrębie obrazu, co możemy założyć, że jest łatwiejszym zadaniem.
Poniżej znajduje się przykład porównujący lokalizację pojedynczego obiektu i detekcję obiektu, zaczerpnięty z dokumentu ILSVRC. Zwróć uwagę na różnicę w oczekiwaniach prawdy podstawowej w każdym przypadku.
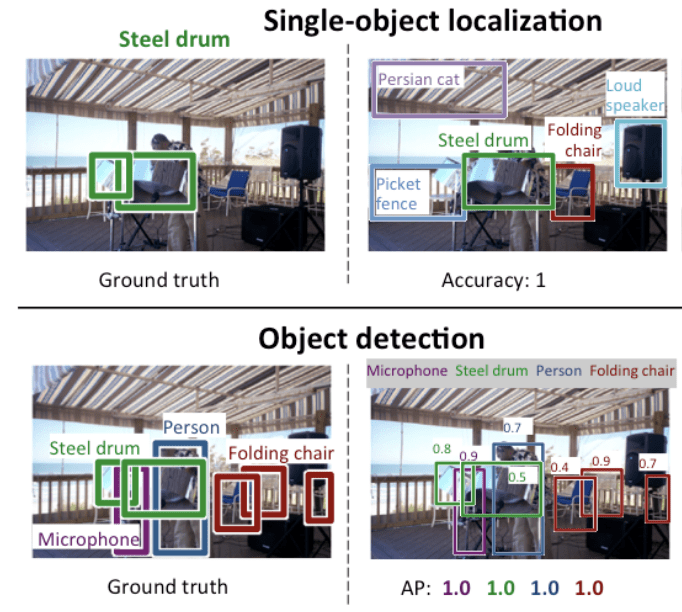
Comparison Between Single Object Localization and Object Detection.Taken From: ImageNet Large Scale Visual Recognition Challenge.
Wydajność modelu do klasyfikacji obrazów jest oceniana przy użyciu średniego błędu klasyfikacji dla wszystkich przewidywanych etykiet klas. Wydajność modelu dla lokalizacji pojedynczego obiektu jest oceniana przy użyciu odległości pomiędzy oczekiwaną i przewidywaną ramką dla oczekiwanej klasy. Podczas gdy wydajność modelu do rozpoznawania obiektów jest oceniana przy użyciu precyzji i odwołania przez każdą z najlepiej dopasowanych skrzynek ograniczających dla znanych obiektów w obrazie.
Teraz, gdy jesteśmy zaznajomieni z problemem lokalizacji i wykrywania obiektów, spójrzmy na kilka ostatnich najlepiej działających modeli głębokiego uczenia.
R-CNN Rodzina modeli
Rodzina metod R-CNN odnosi się do sieci R-CNN, która może oznaczać „Regions with CNN Features” lub „Region-Based Convolutional Neural Network”, opracowanej przez Rossa Girshicka i in.
Obejmuje ona techniki R-CNN, Fast R-CNN i Faster-RCNN zaprojektowane i zademonstrowane do lokalizacji obiektów i rozpoznawania obiektów.
Przyjrzyjrzyjmy się bliżej najważniejszym cechom każdej z tych technik po kolei.
R-CNN
R-CNN została opisana w pracy z 2014 roku autorstwa Rossa Girshicka, et al. z UC Berkeley zatytułowanej „Rich feature hierarchies for accurate object detection and semantic segmentation.”
Mogło to być jedno z pierwszych dużych i udanych zastosowań konwencjonalnych sieci neuronowych do problemu lokalizacji, wykrywania i segmentacji obiektów. Podejście to zostało zademonstrowane na wzorcowych zbiorach danych, osiągając następnie wyniki state-of-the-art na zbiorze danych VOC-2012 oraz 200-klasowym zbiorze danych do wykrywania obiektów ILSVRC-2013.
Zaproponowany przez nich model R-CNN składa się z trzech modułów; są to:
- Moduł 1: Region Proposal. Generuje i wyodrębnia niezależne od kategorii propozycje regionów, np. kandydackie ramki ograniczające.
- Moduł 2: Feature Extractor. Wyodrębnij cechy z każdego regionu kandydującego, np. używając głębokiej sieci neuronowej konwolwentowej.
- Moduł 3: Klasyfikator. Klasyfikuje cechy jako jedną ze znanych klas, np. liniowy model klasyfikatora SVM.
Architektura modelu jest podsumowana na poniższym obrazku, zaczerpniętym z pracy.
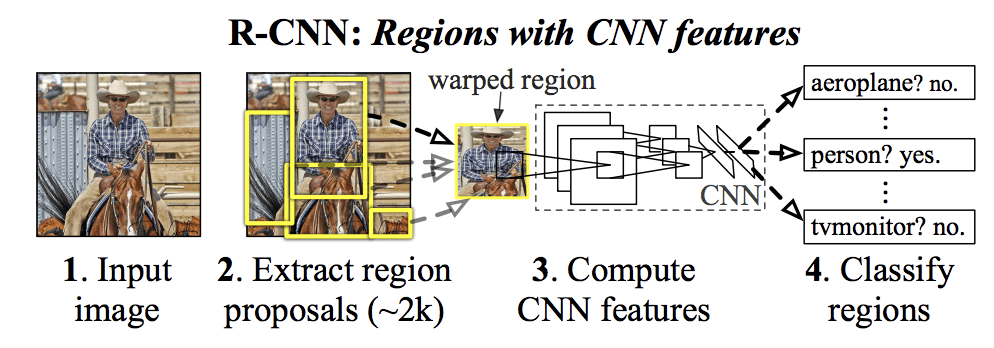
Summary of the R-CNN Model ArchitectureTaken from Rich feature hierarchies for accurate object detection and semantic segmentation.
Technika wizji komputerowej jest używana do proponowania regionów kandydujących lub pól ograniczających potencjalnych obiektów na obrazie zwanych „selektywnym wyszukiwaniem”, chociaż elastyczność projektu pozwala na użycie innych algorytmów proponowania regionów.
Eksploratorem cech używanym przez model była głęboka sieć CNN AlexNet, która wygrała konkurs klasyfikacji obrazów ILSVRC-2012. Wyjściem CNN był 4096 elementowy wektor opisujący zawartość obrazu, który jest podawany do liniowego SVM w celu klasyfikacji, w szczególności jeden SVM jest trenowany dla każdej znanej klasy.
Jest to stosunkowo proste i nieskomplikowane zastosowanie CNN do problemu lokalizacji i rozpoznawania obiektów. Wadą tego podejścia jest to, że jest ono powolne, wymaga przejścia ekstrakcji cech opartej na CNN na każdym z regionów kandydujących wygenerowanych przez algorytm propozycji regionu. Jest to problem, ponieważ w artykule opisano model działający na około 2000 proponowanych regionów na obraz w czasie testu.
Kod źródłowy Pythona (Caffe) i MatLaba dla R-CNN opisanego w artykule został udostępniony w repozytorium R-CNN GitHub.
Szybki R-CNN
Zważywszy na wielki sukces R-CNN, Ross Girshick, wówczas w Microsoft Research, zaproponował rozszerzenie w celu rozwiązania problemów z szybkością R-CNN w pracy z 2015 roku zatytułowanej „Fast R-CNN.”
Pracę otwiera przegląd ograniczeń R-CNN, które można podsumować w następujący sposób:
- Trening jest wieloetapowym potokiem. Wiąże się z przygotowaniem i działaniem trzech oddzielnych modeli.
- Trening jest kosztowny w przestrzeni i czasie. Trenowanie głębokiej sieci CNN na tak wielu propozycjach regionów na obraz jest bardzo powolne.
- Wykrywanie obiektów jest powolne. Make predictions using a deep CNN on so many region proposals is very slow.
Poprzednia praca została zaproponowana w celu przyspieszenia techniki zwanej spatial pyramid pooling networks, lub SPPnets, w pracy z 2014 roku „Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.” To rzeczywiście przyspieszyło ekstrakcję cech, ale zasadniczo używało rodzaju algorytmu buforowania forward pass.
Fast R-CNN jest proponowany jako pojedynczy model zamiast rurociągu do uczenia się i wyprowadzania regionów i klasyfikacji bezpośrednio.
Architektura modelu przyjmuje fotografię a zestaw propozycji regionów jako dane wejściowe, które są przepuszczane przez głęboką konwencjonalną sieć neuronową. Wstępnie wytrenowana sieć CNN, taka jak VGG-16, jest używana do ekstrakcji cech. Na końcu głębokiej sieci CNN znajduje się niestandardowa warstwa zwana warstwą łączenia regionów zainteresowania, lub RoI Pooling, która wyodrębnia cechy specyficzne dla danego wejściowego regionu kandydackiego.
Wyjście sieci CNN jest następnie interpretowane przez w pełni połączoną warstwę, po czym model rozwidla się na dwa wyjścia, jedno dla przewidywania klasy przez warstwę softmax, a drugie z wyjściem liniowym dla pola ograniczającego. Proces ten jest następnie powtarzany wielokrotnie dla każdego regionu zainteresowania w danym obrazie.
Architektura modelu jest podsumowana na poniższym obrazku, zaczerpniętym z pracy.
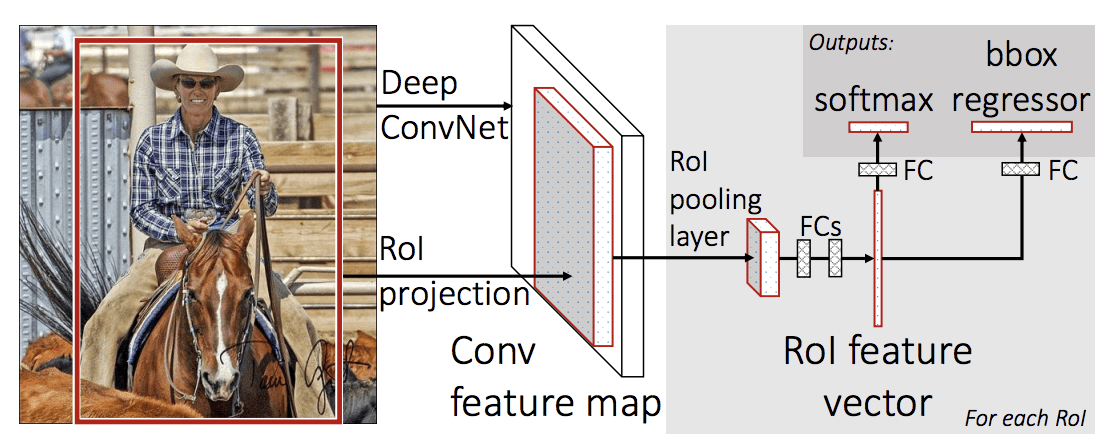
Summary of the Fast R-CNN Model Architecture.
Taken from: Fast R-CNN.
Model jest znacznie szybszy w trenowaniu i przewidywaniu, ale nadal wymaga zestawu kandydujących regionów, które mają być zaproponowane wraz z każdym obrazem wejściowym.
Kod źródłowy Pythona i C++ (Caffe) dla Fast R-CNN opisanego w pracy został udostępniony w repozytorium GitHub.
Faster R-CNN
Architektura modelu została dalej ulepszona zarówno pod kątem szybkości treningu, jak i detekcji przez Shaoqing Ren, et al. w Microsoft Research w pracy z 2016 roku zatytułowanej „Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.”
Architektura ta stanowiła podstawę wyników pierwszego miejsca osiągniętych zarówno w zadaniach konkursowych rozpoznawania i wykrywania obiektów ILSVRC-2015, jak i MS COCO-2015.
Architektura ta została zaprojektowana tak, aby zarówno proponować, jak i udoskonalać propozycje regionów w ramach procesu szkolenia, określanego jako sieć propozycji regionów (Region Proposal Network, w skrócie RPN). Regiony te są następnie używane razem z modelem Fast R-CNN w pojedynczej konstrukcji modelu. Usprawnienia te redukują liczbę propozycji regionów i przyspieszają działanie modelu w czasie testów do niemalże czasu rzeczywistego przy zachowaniu najnowocześniejszej wydajności.
… nasz system detekcji osiąga częstotliwość odświeżania na poziomie 5 klatek na sekundę (włączając w to wszystkie kroki) na układzie GPU, osiągając przy tym najnowocześniejszą dokładność wykrywania obiektów w zestawach danych PASCAL VOC 2007, 2012 i MS COCO przy zaledwie 300 propozycjach na obraz. W konkursach ILSVRC i COCO 2015, Faster R-CNN i RPN są fundamentami prac, które zdobyły pierwsze miejsce w kilku ścieżkach
– Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
Ale choć jest to jeden zunifikowany model, architektura składa się z dwóch modułów:
- Moduł 1: Region Proposal Network. Konwolucyjna sieć neuronowa do proponowania regionów i typu obiektu, który należy uwzględnić w regionie.
- Moduł 2: Fast R-CNN. Konwolucyjna sieć neuronowa do wyodrębniania cech z proponowanych regionów i wyprowadzania ramki ograniczającej oraz etykiet klas.
Oba moduły działają na tym samym wyjściu głębokiej sieci CNN. Sieć propozycji regionów działa jako mechanizm uwagi dla sieci Fast R-CNN, informując drugą sieć o tym, gdzie ma patrzeć lub zwracać uwagę.
Architektura modelu jest podsumowana na poniższym obrazku, zaczerpniętym z pracy.
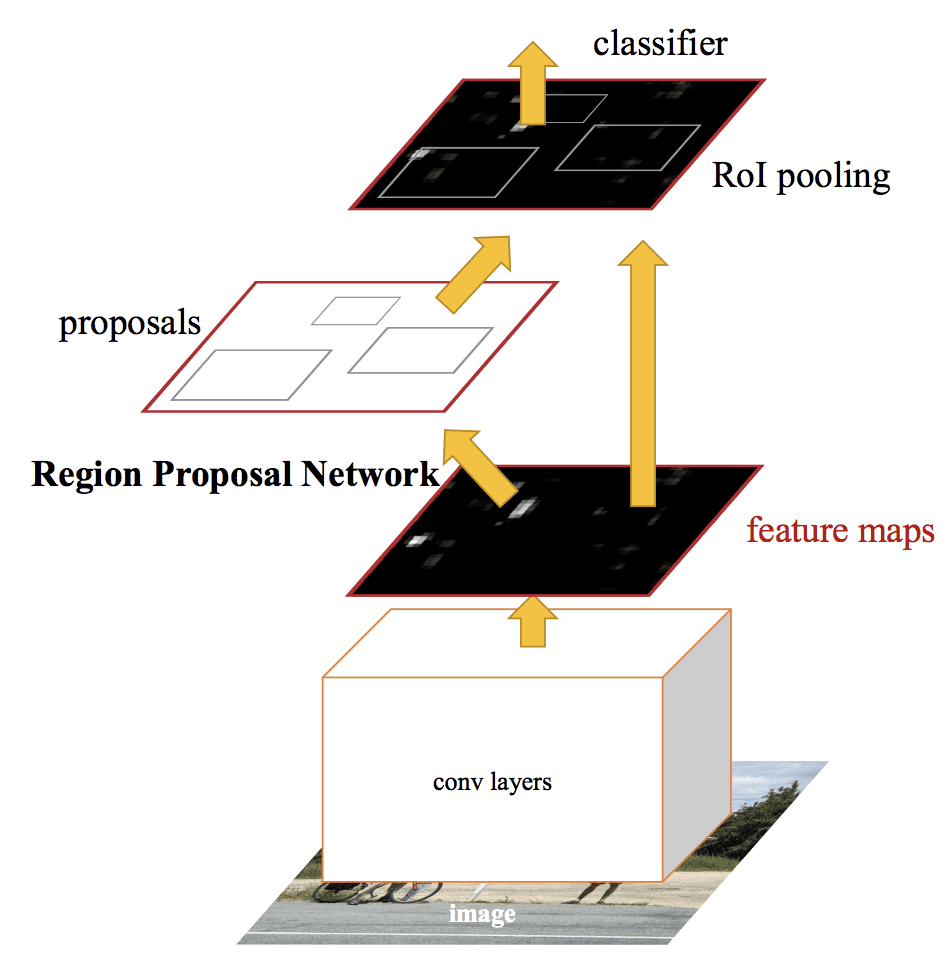
Summary of the Faster R-CNN Model Architecture.Taken from: Faster R-CNN: Towards Real-Time Object Detection With Region Proposal Networks.
Działanie RPN polega na wykorzystaniu danych wyjściowych wstępnie wytrenowanej głębokiej sieci CNN, takiej jak VGG-16, i przepuszczeniu małej sieci przez mapę cech oraz wyprowadzeniu wielu propozycji regionów i przewidywania klasy dla każdej z nich. Propozycje regionów to ramki ograniczające, oparte na tzw. anchor boxach lub predefiniowanych kształtach zaprojektowanych w celu przyspieszenia i ulepszenia propozycji regionów. Predykcja klasy jest binarna, wskazując na obecność obiektu lub nie, tak zwaną „obiektowość” proponowanego regionu.
Używana jest procedura naprzemiennego treningu, gdzie obie podsieci są trenowane w tym samym czasie, choć z przeplotem. Pozwala to na dostosowanie parametrów głębokiej sieci CNN do obu zadań w tym samym czasie.
W czasie pisania tego tekstu, ta architektura Faster R-CNN jest szczytem rodziny modeli i nadal osiąga wyniki bliskie state-of-the-art w zadaniach rozpoznawania obiektów. Dalsze rozszerzenie dodaje wsparcie dla segmentacji obrazu, opisane w pracy 2017 „Mask R-CNN.”
Kod źródłowy Python i C++ (Caffe) dla Fast R-CNN, jak opisano w pracy, został udostępniony w repozytorium GitHub.
Rodzina modeli YOLO
Inna popularna rodzina modeli rozpoznawania obiektów jest określana zbiorczo jako YOLO lub „You Only Look Once,” opracowana przez Josepha Redmona, et al.
Modele R-CNN mogą być ogólnie dokładniejsze, jednak rodzina modeli YOLO jest szybka, znacznie szybsza niż R-CNN, osiągając wykrywanie obiektów w czasie rzeczywistym.
YOLO
Model YOLO został po raz pierwszy opisany przez Josepha Redmona, et al. w pracy z 2015 roku zatytułowanej „You Only Look Once: Unified, Real-Time Object Detection.” Zauważ, że Ross Girshick, twórca R-CNN, był również autorem i współtwórcą tej pracy, wówczas w Facebook AI Research.
Podejście obejmuje pojedynczą sieć neuronową wyszkoloną od końca do końca, która przyjmuje fotografię jako dane wejściowe i przewiduje bounding boxes i etykiety klas dla każdego bounding box bezpośrednio. Technika ta oferuje niższą dokładność przewidywania (np. więcej błędów lokalizacji), choć działa z prędkością 45 klatek na sekundę i do 155 klatek na sekundę dla zoptymalizowanej pod kątem szybkości wersji modelu.
Nasza zunifikowana architektura jest niezwykle szybka. Nasz podstawowy model YOLO przetwarza obrazy w czasie rzeczywistym z prędkością 45 klatek na sekundę. Mniejsza wersja sieci, Fast YOLO, przetwarza zdumiewające 155 klatek na sekundę …
– You Only Look Once: Unified, Real-Time Object Detection, 2015.
Model działa poprzez pierwsze podzielenie obrazu wejściowego na siatkę komórek, gdzie każda komórka jest odpowiedzialna za przewidywanie ramki ograniczającej, jeśli środek ramki ograniczającej mieści się w komórce. Każda komórka siatki przewiduje bounding box z udziałem współrzędnych x, y, szerokości i wysokości oraz zaufania. Przewidywanie klasy jest również oparte na każdej komórce.
Na przykład obraz może być podzielony na siatkę 7×7, a każda komórka w siatce może przewidywać 2 ramki ograniczające, co daje 94 proponowane przewidywania ramek ograniczających. Mapa prawdopodobieństwa klasy i ramki ograniczające z zaufaniem są następnie łączone w ostateczny zestaw ramek ograniczających i etykiet klas. Obraz zaczerpnięty z poniższego artykułu podsumowuje dwa wyjścia modelu.
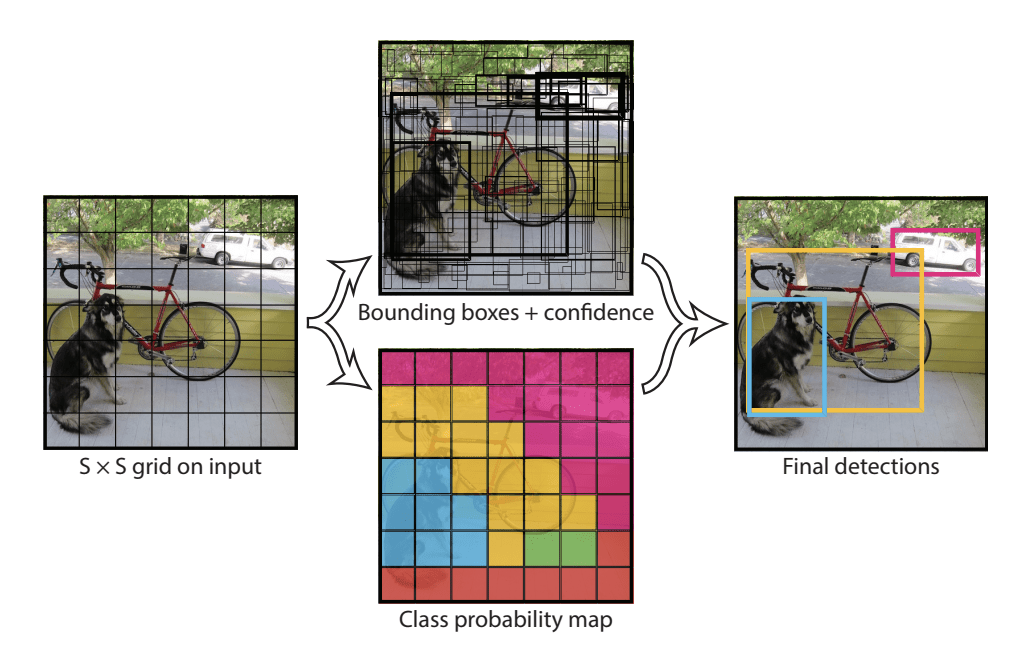
Summary of Predictions made by YOLO Model.Taken from: You Only Look Once: Unified, Real-Time Object Detection
YOLOv2 (YOLO9000) and YOLOv3
The model was updated by Joseph Redmon and Ali Farhadi in an effort to further improve model performance in their 2016 paper titled „YOLO9000: Better, Faster, Stronger.”
Ale chociaż ta odmiana modelu jest określana jako YOLO v2, opisano instancję modelu, która została wytrenowana na dwóch zbiorach danych rozpoznawania obiektów równolegle, zdolnych do przewidywania 9000 klas obiektów, stąd nadano jej nazwę „YOLO9000.”
Do modelu wprowadzono szereg zmian szkoleniowych i architektonicznych, takich jak użycie normalizacji partii i obrazów wejściowych o wysokiej rozdzielczości.
Podobnie jak Faster R-CNN, model YOLOv2 korzysta z anchor boxów, predefiniowanych pudełek ograniczających o użytecznych kształtach i rozmiarach, które są dostosowywane podczas szkolenia. Wybór pól ograniczających dla obrazu jest wstępnie przetwarzany przy użyciu analizy k-średnich na zbiorze danych treningowych.
Co ważne, przewidywana reprezentacja pól ograniczających jest zmieniana, aby umożliwić małym zmianom mniej dramatyczny wpływ na przewidywania, co skutkuje bardziej stabilnym modelem. Zamiast przewidywać pozycję i rozmiar bezpośrednio, przesunięcia są przewidywane dla przesuwania i zmiany kształtu wstępnie zdefiniowanych pól zakotwiczenia w stosunku do komórki siatki i tłumione przez funkcję logistyczną.
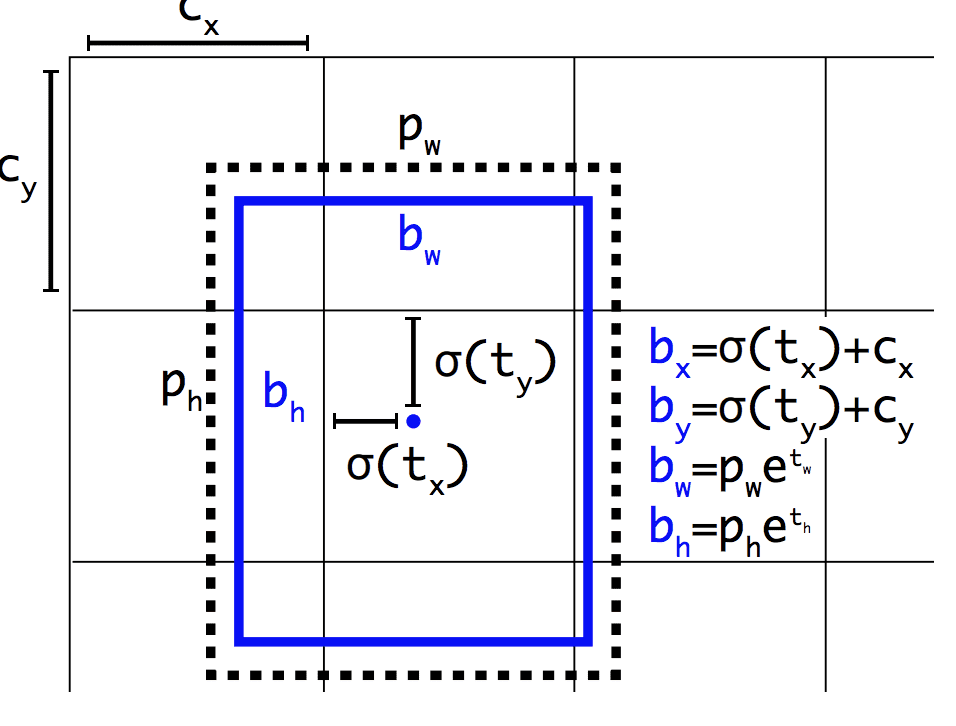
Przykład reprezentacji wybranej podczas przewidywania pozycji i kształtu Bounding BoxTaken from: YOLO9000: Better, Faster, Stronger
Dalsze ulepszenia modelu zostały zaproponowane przez Josepha Redmona i Ali Farhadiego w ich pracy z 2018 roku zatytułowanej „YOLOv3: An Incremental Improvement.” Ulepszenia były dość niewielkie, w tym głębsza sieć detektora cech i niewielkie zmiany reprezentacyjne.
Further Reading
Ta sekcja zapewnia więcej zasobów na ten temat, jeśli szukasz zagłębić się w temat.
Papers
- ImageNet Large Scale Visual Recognition Challenge, 2015.
R-CNN Family Papers
- Rich feature hierarchies for accurate object detection and semantic segmentation, 2013.
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, 2014.
- Fast R-CNN, 2015.
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, 2016.
- Mask R-CNN, 2017.
YOLO Family Papers
- You Only Look Once: Unified, Real-Time Object Detection, 2015.
- YOLO9000: Better, Faster, Stronger, 2016.
- YOLOv3: An Incremental Improvement, 2018.
Code Projects
- R-CNN: Regions with Convolutional Neural Network Features, GitHub.
- Fast R-CNN, GitHub.
- Faster R-CNN Python Code, GitHub.
- YOLO, GitHub.
Resources
- Ross Girshick, Strona główna.
- Joseph Redmon, Homepage.
- YOLO: Real-Time Object Detection, Homepage.
Articles
- A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN, 2017.
- Object Detection for Dummies Part 3: R-CNN Family, 2017.
- Object Detection Part 4: Fast Detection Models, 2018.
Summary
W tym poście odkryłeś delikatne wprowadzenie do problemu rozpoznawania obiektów i state-of-the-art deep learning models designed to address it.
Specjalnie, dowiedziałeś się:
- Rozpoznawanie obiektów odnosi się do zbioru powiązanych zadań identyfikacji obiektów na fotografiach cyfrowych.
- Region-Based Convolutional Neural Networks, lub R-CNNs, to rodzina technik do rozwiązywania zadań lokalizacji i rozpoznawania obiektów, zaprojektowana z myślą o wydajności modelu.
- You Only Look Once, lub YOLO, to druga rodzina technik rozpoznawania obiektów zaprojektowana z myślą o szybkości i wykorzystaniu w czasie rzeczywistym.
Czy masz jakieś pytania?
Zadawaj pytania w komentarzach poniżej, a ja postaram się odpowiedzieć.
Rozwijaj modele Deep Learning dla wizji już dziś!

Rozwijaj własne modele wizji w ciągu kilku minut
….z zaledwie kilkoma liniami kodu Pythona
Odkryj jak to zrobić w moim nowym Ebooku:
Deep Learning for Computer Vision
Zawiera on samouczki na takie tematy jak:
klasyfikacja, wykrywanie obiektów (yolo i rcnn), rozpoznawanie twarzy (vggface i facenet), przygotowanie danych i wiele innych…
Wreszcie wprowadź Deep Learning do swoich projektów wizyjnych
Opuść akademickość. Just Results.
Zobacz, co jest w środku
.