
Em “Anomaly Detection with Autoencoders Made Easy” mencionei que os Autocodificadores têm sido amplamente aplicados na redução de dimensões e redução de ruído de imagem. Desde então muitos leitores têm perguntado se eu posso cobrir o tópico de redução de ruído de imagem usando autocodificadores. Essa é a motivação deste post.
Modelar dados de imagem requer uma abordagem especial no mundo das redes neurais. A rede neural mais conhecida para modelagem de dados de imagem é a Convolutional Neural Network (CNN, ou ConvNet) ou chamada Convolutional Autoencoder. Neste post vou começar com uma introdução suave para os dados de imagem porque nem todos os leitores estão no campo de dados de imagem (por favor, sinta-se à vontade para pular essa seção se você já está familiarizado com ela). Descrevo então uma rede neural padrão simples para os dados de imagem. Isso me dará a oportunidade de demonstrar porque os Autoencoders Convolucionais são o método preferido para lidar com os dados de imagem. Acima de tudo, vou demonstrar como os Autocodificadores Convolucionais reduzem os ruídos em uma imagem. Eu uso o módulo Keras e os dados do MNIST neste post. O bloco de notas está disponível através deste link. O Keras é um API de redes neurais de alto nível, escrito em Python e capaz de rodar em cima do TensorFlow. Este post é uma extensão do meu post anterior “What Is Image Recognition?” que eu encorajo você a dar uma olhada.
Eu achei que é útil mencionar as três categorias de dados amplos. As três categorias de dados são: (1) Dados não-relacionados (em contraste com dados seriais), (2) Dados seriais (incluindo dados de texto e fluxo de voz), e (3) Dados de imagem. O aprendizado profundo tem três variações básicas para abordar cada categoria de dados: (1) a rede neural feedforward padrão, (2) RNN/LSTM, e (3) NN Convolucional (CNN). Para leitores que estão procurando por tutoriais para cada tipo, recomenda-se que você verifique “Explicando o Aprendizado Profundo de uma Forma Amigável à Regressão” para (1), o artigo atual “Um Guia Técnico para RNNN/LSTM/GRU sobre Previsão de Preço de Estoque” para (2), e “Aprendizado Profundo com PyTorch Não é Torturante”, “O que é Reconhecimento de Imagem?”, “Detecção de Anomalias com Autocodificadores Facilitada”, e “Autocodificadores Convolucionais para Redução de Ruído de Imagem” para (3). Você pode marcar o artigo de resumo “Dataman Learning Paths – Build Your Skills, Drive Your Career”.
Understand Image Data
Uma imagem é feita de “pixels” como mostrado na Figura (A). Em uma imagem em preto e branco, cada pixel é representado por um número que varia de 0 a 255. A maioria das imagens de hoje usam cores de 24-bit ou superiores. Uma imagem de cor RGB significa que a cor num pixel é a combinação de Vermelho, Verde e Azul, cada uma das cores variando de 0 a 255. O sistema de cor RGB constrói todas as cores a partir da combinação das cores Vermelho, Verde e Azul, como mostrado neste gerador de cor RGB. Então um pixel contém um conjunto de três valores RGB(102, 255, 102) refere-se à cor #66ff66.

Uma imagem com 800 pixels de largura, 600 pixels de altura tem 800 x 600 = 480.000 pixels = 0,48 megapixel (“megapixel” é 1 milhão de pixels). Uma imagem com uma resolução de 1024×768 é uma grade com 1.024 colunas e 768 linhas, que portanto contém 1.024 × 768 = 0,78 megapixels.
MNIST
A base de dados MNIST (Modified National Institute of Standards and Technology database) é uma grande base de dados de dígitos escritos à mão que é comumente usada para treinamento de vários sistemas de processamento de imagem. O conjunto de dados de treinamento em Keras tem 60.000 registros e o conjunto de dados de teste tem 10.000 registros. Cada registro tem 28 x 28 pixels.
O que eles se parecem? Vamos usar matplotlib e sua função de imagem imshow() para mostrar os primeiros dez registros.
Retira os dados de imagem para treinamento
A fim de encaixar uma estrutura de rede neural para treinamento do modelo, podemos empilhar todos os 28 x 28 = 784 valores em uma coluna. A coluna empilhada para o primeiro registro é parecida com esta: (usando x_train.reshape(1,784)):

Então podemos treinar o modelo com uma rede neural padrão, como mostrado na Figura (B). Cada um dos 784 valores é um nó na camada de entrada. Mas espere, não perdemos muita informação quando empilhamos os dados? Sim. As relações espaciais e temporais em uma imagem foram descartadas. Isto é uma grande perda de informação. Vamos ver como os Autocodificadores Convolucionais podem reter informação espacial e temporal.

Por que são os Autocodificadores Convolucionais Adequados para Dados de Imagem?
Vemos uma enorme perda de informação ao fatiar e empilhar os dados. Ao invés de empilhar os dados, os Autocodificadores Convolucionais mantêm a informação espacial dos dados da imagem de entrada como eles são, e extraem a informação suavemente no que é chamado de camada Convolucional. A figura (D) demonstra que uma imagem 2D plana é extraída para um quadrado grosso (Conv1), depois continua a tornar-se uma cúbica longa (Conv2) e outra cúbica mais longa (Conv3). Este processo é projetado para reter as relações espaciais nos dados. Este é o processo de codificação em um Autoencoder. No meio, há um autocodificador totalmente conectado cuja camada oculta é composta de apenas 10 neurônios. Depois disso, vem o processo de descodificação que aplana os cúbicos, e depois uma imagem plana 2D. O codificador e o decodificador são simétricos na Figura (D). Eles não precisam ser simétricos, mas a maioria dos profissionais apenas adotam esta regra como explicado em “Detecção de anomalias com Autocodificadores facilitada”.

Como Funcionam os Autocodificadores Convolucionais?
A extracção de dados acima parece mágica. Como é que isso realmente funciona? Ela envolve as três seguintes camadas: A camada de convolução, a camada reLu e a camada de pooling.

- A Camada de Convolução
O passo de convolução cria muitas pequenas peças chamadas os mapas de recursos ou recursos como os quadrados verdes, vermelhos ou azul-marinho na Figura (E). Estes quadrados preservam a relação entre os pixels na imagem de entrada. Deixe cada característica digitalizar através da imagem original como o mostrado na Figura (F). Este processo na produção das partituras é chamado de filtragem.
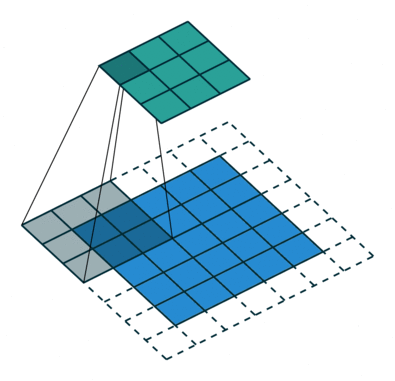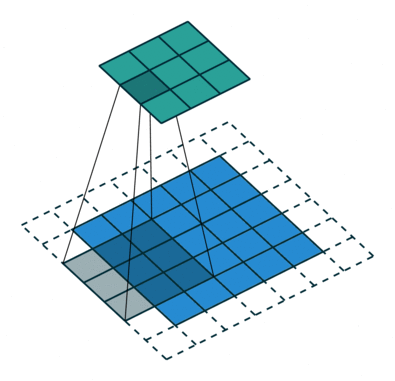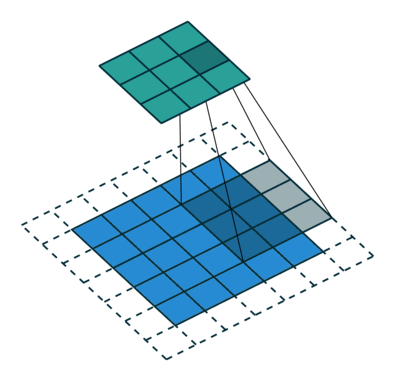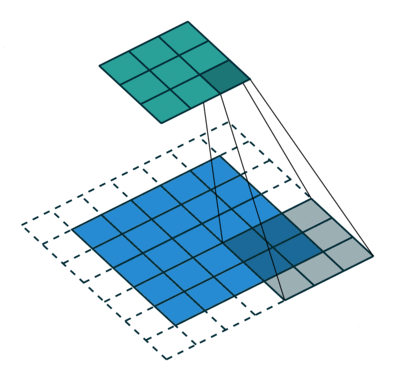
Após a digitalização da imagem original, cada característica produz uma imagem filtrada com pontuações altas e baixas como mostrado na Figura (G). Se houver uma correspondência perfeita, há uma pontuação alta nesse quadrado. Se houver uma combinação baixa ou nenhuma combinação, a pontuação é baixa ou zero. Por exemplo, o quadrado vermelho encontrou quatro áreas na imagem original que mostram uma correspondência perfeita com a característica, então as notas são altas para essas quatro áreas.

Mais filtros significam mais número de características que o modelo pode extrair. No entanto, mais características significam mais tempo de treino. Portanto, é aconselhável usar o número mínimo de filtros para extrair as características.
1.1 Padding
Como é que as características determinam a correspondência? Um hiper-parametro é o Padding que oferece duas opções: (i) preenchimento da imagem original com zeros a fim de caber na característica, ou (ii) deixar cair a parte da imagem original que não cabe e manter a parte válida.
1.2 Strides
A camada de convolução inclui outro parâmetro: o Stride. É o número de pixels que se deslocam sobre a matriz de entrada. Quando a stride é 1, os filtros mudam 1 pixel de cada vez. Nós o veremos em nosso código Keras como um hiper-parâmetro.
2. ReLUs Step
The Rectified Linear Unit (ReLU) é o mesmo passo que o passo nas redes neurais típicas. Ela retifica qualquer valor negativo para zero de forma a garantir que a matemática se comportará corretamente.
3. Max Pooling Layer
Pooling diminui o tamanho da imagem. Na figura (H) uma janela de 2 x 2, chamada tamanho do pool, varre através de cada uma das imagens filtradas e atribui o valor máximo dessa janela de 2 x 2 a um quadrado de 1 x 1 em uma nova imagem. Como ilustrado na Figura (H), o valor máximo na primeira janela 2 x 2 é uma pontuação alta (representada por vermelho), então a pontuação alta é atribuída ao quadrado 1 x 1.

Besidesides tomando o valor máximo, outros métodos menos comuns de pooling incluem o Pooling Médio (tomando o valor médio) ou o Sum Pooling (a soma).

Após o pooling, uma nova pilha de imagens filtradas menores é produzida. Agora nós dividimos as imagens filtradas menores e as empilhamos em uma lista como mostrado na Figura (J)
Modelo em Keras
As três camadas acima são os blocos de construção na rede neural de convolução. Keras oferece as seguintes duas funções:
Você pode construir muitas camadas de convolução nos Autoencoders de Convolução. Na Figura (E) há três camadas denominadas Conv1, Conv2, e Conv3 na parte de codificação. Então nós vamos construir de acordo.
- O código abaixo
input_img = Input(shape=(28,28,1)declara que a imagem 2D de entrada é 28 por 28. - Então constrói as três camadas Conv1, Conv2 e Conv3.
- Nota que Conv1 está dentro de Conv2 e Conv2 está dentro de Conv3.
- A
paddingespecifica o que fazer quando o filtro não encaixa bem na imagem de entrada.padding='valid'significa largar a parte da imagem quando o filtro não se encaixa;padding='same'coloca a imagem com zeros para encaixar na imagem.
Em seguida continua a adicionar o processo de descodificação. Assim, a parte decode abaixo tem todos os codificados e decodificados.
O Keras api requer a declaração do modelo e o método de otimização:
-
Model(inputs= input_img,outputs= decoded): O modelo incluirá todas as camadas requeridas no cálculo das saídasdecodeddado os dados de entradainput_img.compile(optimizer='adadelta',loss='binary_crossentropy'): O otimizador executa a otimização como o gradiente decente faz. Os mais comuns são o declive estocástico (SGD), o declive adaptado (Adagrad) e o Adadelta que é uma extensão do Adagrad. Veja a documentação do otimizador Keras para mais detalhes. As funções de perda podem ser encontradas na documentação de perdas do Keras.
Below I treina o modelo usando x_train como entrada e saída. O batch_size é o número de amostras e o epoch é o número de iterações. Eu especifico shuffle=True para requerer o embaralhamento dos dados do trem antes de cada época.
Podemos imprimir as primeiras dez imagens originais e as previsões para as mesmas dez imagens.
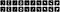
Como Construir um Autocodificador de Redução de Ruído de Imagem?
A ideia da redução de ruído de imagem é treinar um modelo com dados ruidosos como as entradas, e seus respectivos dados claros como as saídas. Esta é a única diferença em relação ao modelo acima. Vamos primeiro adicionar ruídos aos dados.
As primeiras dez imagens ruidosas parecem-se com as seguintes:

Aí treinamos o modelo com os dados ruidosos como as entradas, e os dados limpos como as saídas.
Finalmente, imprimimos as primeiras dez imagens ruidosas, bem como as imagens desnudadas correspondentes.
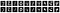
O caderno está disponível através deste link.
Há algum código de CNNs pré-treinado que eu possa usar?
Sim. Se você estiver interessado em aprender o código, Keras tem vários CNNs pré-treinados incluindo Xception, VGGG16, VGG19, ResNet50, InceptionV3, InceptionResNetV2, MobileNet, DenseNet, NASNet, e MobileNetV2. Vale a pena mencionar esta grande base de dados de imagens ImageNet que você pode contribuir ou baixar para fins de pesquisa.