Kolmogorov-Smirnov (KS) Statistics é uma das métricas mais importantes usadas para validar modelos preditivos. É amplamente utilizada no domínio BFSI. Se você faz parte da equipe de análise de risco ou marketing que trabalha em projetos bancários, você deve ter ouvido falar dessa métrica.
O que é KS Statistics?
Significa Kolmogorov-Smirnov que tem o nome de Andrey Kolmogorov e Nikolai Smirnov. Ele compara as duas distribuições cumulativas e retorna a diferença máxima entre elas. É um teste não paramétrico, o que significa que você não precisa testar nenhuma suposição relacionada à distribuição de dados. No Teste KS, a hipótese Nula declara nulas ambas as distribuições cumulativas são semelhantes. Rejeitando a hipótese nula significa que as distribuições cumulativas são diferentes.
Na ciência dos dados, ela compara a distribuição cumulativa de eventos e não eventos e KS é onde há uma diferença máxima entre as duas distribuições. Em palavras simples, ele nos ajuda a entender como nosso modelo preditivo é capaz de discriminar entre eventos e não-eventos.
Se você estiver construindo um modelo de propensão no qual o objetivo é identificar os possíveis compradores de um determinado produto. Neste caso, a variável dependente (alvo) está na forma binária que tem apenas dois resultados: 0 (Não-evento) ou 1 (Evento). “Evento” significa as pessoas que compraram o produto. “não-evento” refere-se a pessoas que não compraram o produto. KS Statistics mede se o modelo é capaz de distinguir entre prospects e non-prospects.
Duas maneiras de medir KS Statistic
Este método é a maneira mais comum de calcular a estatística KS para validar o modelo preditivo binário. Veja os passos abaixo.
- Você precisa ter duas variáveis antes de calcular KS. Uma é uma variável dependente que deve ser binária. A segunda é a pontuação de probabilidade prevista que é gerada a partir do modelo estatístico.
- Criar deciles com base nas colunas de probabilidade prevista, o que significa dividir a probabilidade em 10 partes. O primeiro decil deve conter a pontuação mais alta de probabilidade.
- Calcular a % cumulativa de eventos e não eventos em cada decil e, em seguida, calcular a diferença entre essas duas distribuições cumulativas.
- KS é onde a diferença é máxima
- Se KS estiver entre os 3 decil e a pontuação acima de 40, ele é considerado um bom modelo preditivo. Ao mesmo tempo, é importante validar o modelo verificando outras métricas de desempenho também para confirmar que o modelo não está sofrendo de problemas de sobreajuste.
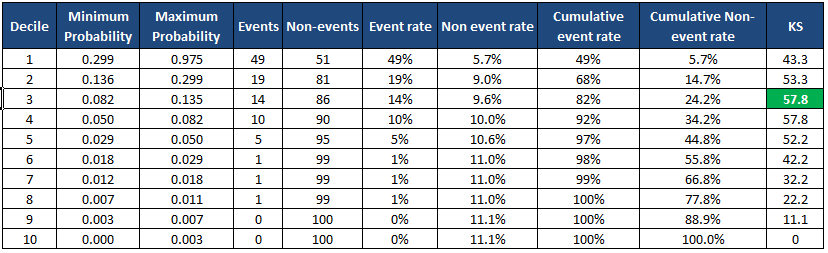
Python : KS Statistics Decile Method
Eu preparei uma amostra de dados, por exemplo. O conjunto de dados contém duas colunas chamadas y e p.yé uma variável dependente.prefere-se à probabilidade prevista.
import pandas as pdimport numpy as npdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
def ks(data=None,target=None, prob=None): data = 1 - data data = pd.qcut(data, 10) grouped = data.groupby('bucket', as_index = False) kstable = pd.DataFrame() kstable = grouped.min() kstable = grouped.max() kstable = grouped.sum() kstable = grouped.sum() kstable = kstable.sort_values(by="min_prob", ascending=False).reset_index(drop = True) kstable = (kstable.events / data.sum()).apply('{0:.2%}'.format) kstable = (kstable.nonevents / data.sum()).apply('{0:.2%}'.format) kstable=(kstable.events / data.sum()).cumsum() kstable=(kstable.nonevents / data.sum()).cumsum() kstable = np.round(kstable-kstable, 3) * 100 #Formating kstable= kstable.apply('{0:.2%}'.format) kstable= kstable.apply('{0:.2%}'.format) kstable.index = range(1,11) kstable.index.rename('Decile', inplace=True) pd.set_option('display.max_columns', 9) print(kstable) #Display KS from colorama import Fore print(Fore.RED + "KS is " + str(max(kstable))+"%"+ " at decile " + str((kstable.index==max(kstable)]))) return(kstable)
mydf = ks(data=df,target="y", prob="p")
-
datarefere-se a pandas dataframe que contém tanto a variável dependente quanto as pontuações de probabilidade. -
targetrefere-se ao nome da coluna da variável dependente -
probrefere-se ao nome da coluna da probablidade prevista
Retorna informações de cada decil em formato tabular e também imprime a partitura KS abaixo da tabela. Também gera a tabela em um novo dataframe.
min_prob max_prob events nonevents event_rate nonevent_rate \Decile 1 0.298894 0.975404 49 51 49.00% 5.67% 2 0.135598 0.298687 19 81 19.00% 9.00% 3 0.082170 0.135089 14 86 14.00% 9.56% 4 0.050369 0.082003 10 90 10.00% 10.00% 5 0.029415 0.050337 5 95 5.00% 10.56% 6 0.018343 0.029384 1 99 1.00% 11.00% 7 0.011504 0.018291 1 99 1.00% 11.00% 8 0.006976 0.011364 1 99 1.00% 11.00% 9 0.002929 0.006964 0 100 0.00% 11.11% 10 0.000073 0.002918 0 100 0.00% 11.11% cum_eventrate cum_noneventrate KS Decile 1 49.00% 5.67% 43.3 2 68.00% 14.67% 53.3 3 82.00% 24.22% 57.8 4 92.00% 34.22% 57.8 5 97.00% 44.78% 52.2 6 98.00% 55.78% 42.2 7 99.00% 66.78% 32.2 8 100.00% 77.78% 22.2 9 100.00% 88.89% 11.1 10 100.00% 100.00% 0.0 KS is 57.8% at decile 3
Usandoscipybiblioteca python, podemos calcular duas amostras da KS Statistic. Ele tem dois parâmetros – data1 e data2. Nos dados1, vamos inserir todas as pontuações de probabilidade correspondentes aos não-eventos. Nos dados2, ele irá tomar pontuações de probabilidade contra eventos.
from scipy.stats import ks_2sampdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")ks_2samp(df.loc, df.loc)
Retorna pontuação KS 0,6033 e p-valor inferior a 0,01 o que significa que podemos rejeitar a hipótese nula e a distribuição final de eventos e não-eventos é diferente.
OutputKs_2sampResult(statistic=0.6033333333333333, pvalue=1.1227180680661939e-29)
A pontuação KS do método 2 é ligeiramente diferente do método 1, uma vez que o segundo é calculado em nível de linha e o primeiro é calculado após a conversão dos dados em dez partes.