La statistique Kolmogorov-Smirnov (KS) est l’une des plus importantes métriques utilisées pour valider les modèles prédictifs. Elle est largement utilisée dans le domaine BFSI. Si vous faites partie de l’équipe d’analyse des risques ou du marketing qui travaille sur un projet dans le secteur bancaire, vous devez avoir entendu parler de cette métrique.
Qu’est-ce que la statistique KS ?
C’est l’abréviation de Kolmogorov-Smirnov qui doit son nom à Andrey Kolmogorov et Nikolai Smirnov. Il compare les deux distributions cumulatives et renvoie la différence maximale entre elles. Il s’agit d’un test non paramétrique, ce qui signifie que vous n’avez pas besoin de tester une hypothèse liée à la distribution des données. Dans le test de KS, l’hypothèse nulle indique que les deux distributions cumulatives sont similaires. Le rejet de l’hypothèse nulle signifie que les distributions cumulatives sont différentes.
En science des données, il compare la distribution cumulative des événements et des non-événements et le KS est là où il y a une différence maximale entre les deux distributions. En termes simples, il nous aide à comprendre dans quelle mesure notre modèle prédictif est capable de discriminer les événements et les non-événements.
Supposons que vous construisiez un modèle de propension dans lequel l’objectif est d’identifier les prospects qui sont susceptibles d’acheter un produit particulier. Dans ce cas, la variable dépendante (cible) est sous forme binaire qui n’a que deux issues : 0 (non-événement) ou 1 (événement). « Événement » désigne les personnes qui ont acheté le produit. « Non-événement » fait référence aux personnes qui n’ont pas acheté le produit. La statistique KS mesure si le modèle est capable de distinguer les prospects des non-prospects.
Deux façons de mesurer la statistique KS
Cette méthode est la plus courante pour calculer la statistique KS pour valider un modèle prédictif binaire. Voir les étapes ci-dessous.
- Vous devez avoir deux variables avant de calculer KS. L’une est la variable dépendante qui doit être binaire. La seconde est le score de probabilité prédite qui est généré à partir du modèle statistique.
- Créer des déciles basés sur les colonnes de probabilité prédite, ce qui signifie diviser la probabilité en 10 parties. Le premier décile doit contenir le score de probabilité le plus élevé.
- Calculer le % cumulé d’événements et de non-événements dans chaque décile, puis calculer la différence entre ces deux distributions cumulatives.
- KS est l’endroit où la différence est maximale
- Si KS est dans le décile 3 supérieur et le score supérieur à 40, il est considéré comme un bon modèle prédictif. Dans le même temps, il est important de valider le modèle en vérifiant également d’autres mesures de performance pour confirmer que le modèle ne souffre pas d’un problème de surajustement.
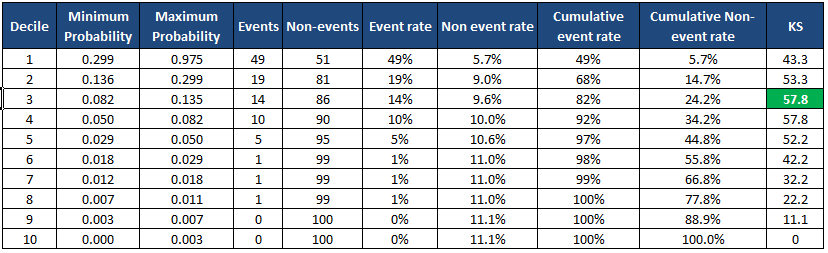
Python : Méthode des déciles statistiques KS
J’ai préparé un échantillon de données pour l’exemple. L’ensemble de données contient deux colonnes appelées y et p.yest une variable dépendante.pfait référence à la probabilité prédite.
import pandas as pdimport numpy as npdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")
def ks(data=None,target=None, prob=None): data = 1 - data data = pd.qcut(data, 10) grouped = data.groupby('bucket', as_index = False) kstable = pd.DataFrame() kstable = grouped.min() kstable = grouped.max() kstable = grouped.sum() kstable = grouped.sum() kstable = kstable.sort_values(by="min_prob", ascending=False).reset_index(drop = True) kstable = (kstable.events / data.sum()).apply('{0:.2%}'.format) kstable = (kstable.nonevents / data.sum()).apply('{0:.2%}'.format) kstable=(kstable.events / data.sum()).cumsum() kstable=(kstable.nonevents / data.sum()).cumsum() kstable = np.round(kstable-kstable, 3) * 100 #Formating kstable= kstable.apply('{0:.2%}'.format) kstable= kstable.apply('{0:.2%}'.format) kstable.index = range(1,11) kstable.index.rename('Decile', inplace=True) pd.set_option('display.max_columns', 9) print(kstable) #Display KS from colorama import Fore print(Fore.RED + "KS is " + str(max(kstable))+"%"+ " at decile " + str((kstable.index==max(kstable)]))) return(kstable)
mydf = ks(data=df,target="y", prob="p")
-
datafait référence au dataframe pandas qui contient à la fois la variable dépendante et les scores de probabilité. -
targetfait référence au nom de la colonne de la variable dépendante -
probfait référence au nom de la colonne de la probabilité prédite
Elle renvoie les informations de chaque décile sous forme de tableau et imprime également le score KS sous le tableau. Il génère également le tableau dans un nouveau dataframe.
min_prob max_prob events nonevents event_rate nonevent_rate \Decile 1 0.298894 0.975404 49 51 49.00% 5.67% 2 0.135598 0.298687 19 81 19.00% 9.00% 3 0.082170 0.135089 14 86 14.00% 9.56% 4 0.050369 0.082003 10 90 10.00% 10.00% 5 0.029415 0.050337 5 95 5.00% 10.56% 6 0.018343 0.029384 1 99 1.00% 11.00% 7 0.011504 0.018291 1 99 1.00% 11.00% 8 0.006976 0.011364 1 99 1.00% 11.00% 9 0.002929 0.006964 0 100 0.00% 11.11% 10 0.000073 0.002918 0 100 0.00% 11.11% cum_eventrate cum_noneventrate KS Decile 1 49.00% 5.67% 43.3 2 68.00% 14.67% 53.3 3 82.00% 24.22% 57.8 4 92.00% 34.22% 57.8 5 97.00% 44.78% 52.2 6 98.00% 55.78% 42.2 7 99.00% 66.78% 32.2 8 100.00% 77.78% 22.2 9 100.00% 88.89% 11.1 10 100.00% 100.00% 0.0 KS is 57.8% at decile 3
En utilisant la bibliothèque pythonscipy, nous pouvons calculer la statistique KS à deux échantillons. Il a deux paramètres – data1 et data2. Dans data1, Nous entrerons tous les scores de probabilité correspondant aux non-événements. Dans data2, il prendra les scores de probabilité contre les événements.
from scipy.stats import ks_2sampdf = pd.read_csv("https://raw.githubusercontent.com/deepanshu88/data/master/data.csv")ks_2samp(df.loc, df.loc)
Il renvoie le score KS 0,6033 et la valeur p inférieure à 0,01 ce qui signifie que nous pouvons rejeter l’hypothèse nulle et conclure que la distribution des événements et des non-événements est différente.
OutputKs_2sampResult(statistic=0.6033333333333333, pvalue=1.1227180680661939e-29)
Le score KS de la méthode 2 est légèrement différent de celui de la méthode 1 car le second est calculé au niveau des lignes et le premier est calculé après avoir converti les données en dix parties.