.Les fichiers ZIP sont des archives qui stockent plusieurs fichiers. ZIP permet aux fichiers contenus d’être compressés en utilisant de nombreuses méthodes différentes, ainsi que de simplement stocker un fichier sans le compresser. Chaque fichier est stocké séparément, ce qui permet aux différents fichiers d’une même archive d’être compressés à l’aide de différentes méthodes. Comme les fichiers d’une archive ZIP sont compressés individuellement, il est possible de les extraire ou d’en ajouter de nouveaux, sans appliquer de compression ou de décompression à l’ensemble de l’archive. Cela contraste avec le format des fichiers tar compressés, pour lesquels un tel traitement à accès aléatoire n’est pas facilement possible.
Un répertoire est placé à la fin d’un fichier ZIP. Cela permet d’identifier les fichiers contenus dans le ZIP et d’identifier où dans le ZIP se trouve ce fichier. Cela permet aux lecteurs ZIP de charger la liste des fichiers sans lire l’intégralité de l’archive ZIP. Les archives ZIP peuvent également inclure des données supplémentaires qui ne sont pas liées à l’archive ZIP. Cela permet de transformer une archive ZIP en une archive auto-extractible (application qui décompresse les données qu’elle contient), en ajoutant le code du programme à une archive ZIP et en marquant le fichier comme exécutable. Le stockage du catalogue à la fin rend également possible la dissimulation d’un fichier zippé en l’annexant à un fichier inoffensif, tel qu’un fichier image GIF.
Le format .ZIP utilise un algorithme CRC 32 bits et inclut deux copies de la structure de répertoire de l’archive afin de fournir une meilleure protection contre la perte de données.
StructureEdit
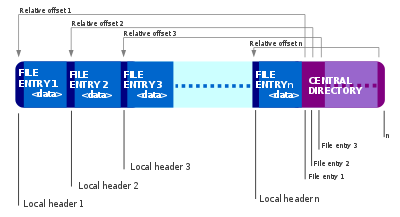
Un fichier ZIP est correctement identifié par la présence d’un enregistrement de fin de répertoire central qui est situé à la fin de la structure de l’archive afin de permettre l’ajout facile de nouveaux fichiers. Si l’enregistrement de fin de répertoire central indique une archive non vide, le nom de chaque fichier ou répertoire de l’archive doit être spécifié dans une entrée de répertoire central, avec d’autres métadonnées sur l’entrée, et un décalage dans le fichier ZIP, pointant vers les données d’entrée réelles. Cela permet de dresser une liste des fichiers de l’archive relativement rapidement, car il n’est pas nécessaire de lire l’archive entière pour voir la liste des fichiers. Les entrées du fichier ZIP comprennent également ces informations, par souci de redondance, dans un en-tête de fichier local. Comme les fichiers ZIP peuvent être ajoutés, seuls les fichiers spécifiés dans le répertoire central à la fin du fichier sont valides. L’analyse d’un fichier ZIP à la recherche d’en-têtes de fichiers locaux n’est pas valable (sauf dans le cas d’archives corrompues), car le répertoire central peut déclarer que certains fichiers ont été supprimés et que d’autres ont été mis à jour.
Par exemple, nous pouvons commencer avec un fichier ZIP qui contient les fichiers A, B et C. Le fichier B est ensuite supprimé et C mis à jour. Pour ce faire, il suffit d’ajouter un nouveau fichier C à la fin du fichier ZIP original et d’ajouter un nouveau répertoire central qui ne contient que le fichier A et le nouveau fichier C. Lorsque le ZIP a été conçu, le transfert de fichiers par disquette était courant, mais l’écriture sur les disques prenait beaucoup de temps. Si vous aviez un gros fichier zip, s’étendant éventuellement sur plusieurs disques, et que vous n’aviez besoin de mettre à jour que quelques fichiers, plutôt que de lire et réécrire tous les fichiers, il serait sensiblement plus rapide de simplement lire l’ancien répertoire central, d’annexer les nouveaux fichiers puis d’annexer un répertoire central mis à jour.
L’ordre des entrées de fichiers dans le répertoire central n’a pas besoin de coïncider avec l’ordre des entrées de fichiers dans l’archive.
Chaque entrée stockée dans une archive ZIP est introduite par un en-tête de fichier local avec des informations sur le fichier telles que le commentaire, la taille du fichier et le nom du fichier, suivi par des champs de données « supplémentaires » facultatifs, puis les données du fichier éventuellement compressées, éventuellement cryptées. Les champs de données « supplémentaires » sont la clé de l’extensibilité du format ZIP. Les champs « Extra » sont exploités pour prendre en charge le format ZIP64, le cryptage AES compatible avec WinZip, les attributs de fichier et les horodatages de fichiers NTFS ou Unix de plus haute résolution. D’autres extensions sont possibles via le champ « Extra ». Les outils ZIP sont tenus par la spécification d’ignorer les champs Extra qu’ils ne reconnaissent pas.
Le format ZIP utilise des « signatures » spécifiques de 4 octets pour désigner les différentes structures du fichier. Chaque entrée du fichier est marquée par une signature spécifique. La fin de l’enregistrement du répertoire central est indiquée par sa signature spécifique, et chaque entrée du répertoire central commence par la signature de l’en-tête du fichier central sur 4 octets.
Il n’y a pas de marqueur BOF ou EOF dans la spécification ZIP. Conventionnellement, la première chose dans un fichier ZIP est une entrée ZIP, qui peut être identifiée facilement par sa signature d’en-tête de fichier local. Cependant, ce n’est pas nécessairement le cas, car cela n’est pas requis par la spécification ZIP – plus particulièrement, une archive auto-extractible commencera par un en-tête de fichier exécutable.
Les outils qui lisent correctement les archives ZIP doivent rechercher la signature de l’enregistrement de fin de répertoire central, puis, le cas échéant, les autres enregistrements de répertoire central, indiqués. Ils ne doivent pas analyser les entrées du haut du fichier ZIP, car (comme mentionné précédemment dans cette section) seul le répertoire central spécifie où un chunk de fichier commence et qu’il n’a pas été supprimé. L’analyse pourrait conduire à des faux positifs, car le format n’interdit pas la présence d’autres données entre les morceaux, ni aux flux de données des fichiers de contenir de telles signatures. Cependant, les outils qui tentent de récupérer des données à partir d’archives ZIP endommagées analyseront très probablement l’archive à la recherche de signatures d’en-tête de fichier local ; cela est rendu plus difficile par le fait que la taille compressée d’un chunk de fichier peut être stockée après le chunk de fichier, ce qui rend le traitement séquentiel difficile.
La plupart des signatures se terminent par l’entier court 0x4b50, qui est stocké dans l’ordre little-endian. Vu comme une chaîne ASCII, cela donne « PK », les initiales de l’inventeur Phil Katz. Ainsi, lorsqu’un fichier ZIP est affiché dans un éditeur de texte, les deux premiers octets du fichier sont généralement « PK ». (Les ZIP auto-extractibles DOS, OS/2 et Windows ont un EXE avant le ZIP et commencent donc par « MZ » ; les ZIP auto-extractibles pour d’autres systèmes d’exploitation peuvent de la même manière être précédés d’un code exécutable pour extraire le contenu de l’archive sur cette plate-forme.)
La spécification .ZIP prend également en charge la répartition des archives sur plusieurs fichiers du système de fichiers. Initialement prévue pour le stockage de gros fichiers ZIP sur plusieurs disquettes, cette fonctionnalité est maintenant utilisée pour l’envoi d’archives ZIP en parties par courrier électronique, ou sur d’autres transports ou supports amovibles.
Le système de fichiers FAT de DOS a une résolution d’horodatage de seulement deux secondes ; les enregistrements de fichiers ZIP imitent cela. Par conséquent, la résolution intégrée de l’horodatage des fichiers dans une archive ZIP n’est que de deux secondes, bien que des champs supplémentaires puissent être utilisés pour stocker des horodatages plus précis. Le format ZIP n’a aucune notion de fuseau horaire, de sorte que les horodatages ne sont significatifs que si l’on sait dans quel fuseau horaire ils ont été créés.
En septembre 2007, PKWARE a publié une révision de la spécification ZIP prévoyant le stockage des noms de fichiers en utilisant UTF-8, ajoutant finalement la compatibilité Unicode au ZIP.
En-têtes de fichiersEdit
Toutes les valeurs multi-octets dans l’en-tête sont stockées dans l’ordre des octets little-endian. Tous les champs de longueur comptent la longueur en octets.
En-tête du fichier localEdit
| Offset | Octets | Description |
|---|---|---|
| 0 | 4 | Signature de l’en-tête du fichier local = 0x04034b50 (lu comme un nombre little-endian) |
| 4 | 2 | Version nécessaire à l’extraction (minimum) |
| 6 | 2 | Facteur de bit à usage général |
| 8 | 2 | Méthode de compression |
| 10 | 2 | Heure de dernière modification du fichier |
| 12 | 2 | Date de dernière modification du fichier |
| 14 | 4 | CRC-32 de données non comprimées |
| 18 | 4 | Taille comprimée (ou 0xffffffff pour ZIP64) |
| 22 | 4 | Taille non compressée (ou 0xffffffff pour ZIP64) |
| 26 | 2 | Longueur du nom de fichier (n) |
| 28 | 2 | Longueur du champ supplémentaire (m) |
| 30 | n | Nom du fichier |
| 30+n | m | Extra field |
Le champ supplémentaire contient une variété de données facultatives telles que des attributs spécifiques au système d’exploitation.attributs spécifiques au système d’exploitation. Il est divisé en chunks, chacun ayant un code d’identification de 16 bits et une longueur de 16 bits. Pour ZIP64, il existe toujours au moins un chunk (avec le code ID 0001 et une taille de 32 octets), voir ci-dessous.
Ceci est immédiatement suivi par les données compressées.
Descripteur de donnéesEdit
Si le bit au décalage 3 (0x08) du champ des drapeaux à usage général est activé, alors le CRC-32 et les tailles de fichiers ne sont pas connus lorsque l’en-tête est écrit. Les champs de l’en-tête local sont remplis de zéro, et le CRC-32 et la taille sont ajoutés dans une structure de 12 octets (éventuellement précédée d’une signature de 4 octets) immédiatement après les données compressées :
| Offset | Bytes | Description |
|---|---|---|
| 0 | 0/4 | Signature du descripteur de données optionnel = 0x08074b50 |
| 0/4 | 4 | CRC-32 de données non compressées |
| 4/8 | 4 | Taille compressée |
| 8/12 | 4 | Taille non compressée size |
En-tête du fichier du répertoire centralEdit
L’entrée du répertoire central est une forme développée de l’en-tête local :
| Offset | Octets | Description | |
|---|---|---|---|
| 0 | 4 | En-tête de fichier de répertoire central. signature de l’en-tête du fichier du répertoire = 0x02014b50 | |
| 4 | 2 | Version faite par | |
| 6 | 2 | Version nécessaire à l’extraction (minimum) | |
| 8 | 2 | Facteur de bit à usage général | |
| 10 | 2 | Méthode de compression | |
| 12 | 2 | 2 | Heure de dernière modification du fichier |
| 14 | 2 | Date de dernière modification du fichier | |
| 16 | 4 | CRC-32 de données non compressées | |
| 20 | 4 | Taille compressée (ou 0xffffffff pour ZIP64) | |
| 24 | 4 | Taille non compressée. (ou 0xffffff pour ZIP64) | |
| 28 | 2 | Longueur du nom de fichier (n) | |
| 30 | 2 | Longueur du champ supplémentaire (m) | |
| 32 | 2 | Longueur du commentaire du fichier (k) | |
| 34 | 2 | Numéro du disque où le fichier commence | |
| 36 | 2 | Attributs internes du fichier | |
| 38 | 4 | Attributs externes du fichier | |
| 42 | 4 | Décalage relatif de l’en-tête du fichier local. Il s’agit du nombre d’octets entre le début du premier disque sur lequel le fichier se produit, et le début de l’en-tête du fichier local. Cela permet aux logiciels qui lisent le répertoire central de localiser la position du fichier à l’intérieur du fichier ZIP. | |
| 46 | n | Nom du fichier | |
| 46+n | m | Extra champ | |
| 46+n+m | k | Commentaire de fichier |
Enregistrement de fin de répertoire central (EOCD)Edit
Après toutes les entrées du répertoire central vient l’enregistrement de fin de répertoire central (EOCD), qui marque la fin du fichier ZIP :
| Offset | Octets | Description |
|---|---|---|
| 0 | 4 | Fin de… signature du répertoire central = 0x06054b50 |
| 4 | 2 | Numéro de ce disque |
| 6 | 2 | Disque où le répertoire central central commence |
| 8 | 2 | Nombre d’enregistrements du répertoire central sur ce disque |
| 10 | 2 | Nombre total d’enregistrements du central |
| 12 | 4 | Taille du répertoire central (octets) |
| 16 | 4 | Offset du début du répertoire central, par rapport au début de l’archive |
| 20 | 2 | Longueur du commentaire (n) |
| 22 | n | Commentaire |
Cet ordonnancement permet de créer un fichier ZIP en une seule passe, mais le répertoire central est également placé à la fin du fichier afin de faciliter le retrait des fichiers de parties multiples (par ex.par exemple, « plusieurs disquettes »), comme discuté précédemment.
Méthodes de compressionModification
La spécification du format de fichier .ZIP documente les méthodes de compression suivantes : Store (aucune compression), Shrink (LZW), Reduce (niveaux 1 à 4 ; LZ77 + probabiliste), Implode, Deflate, Deflate64, bzip2, LZMA, WavPack, PPMd, et une variante de LZ77 fournie par l’instruction IBM z/OS CMPSC. La méthode de compression la plus couramment utilisée est DEFLATE, qui est décrite dans l’IETF RFC 1951.
Les autres méthodes mentionnées, mais non documentées en détail dans la spécification comprennent : PKWARE DCL Implode (ancien IBM TERSE), nouveau IBM TERSE, IBM LZ77 z Architecture (PFS), et une variante JPEG. Une méthode « Tokenize » était réservée à une tierce partie, mais le support n’a jamais été ajouté.
Le mot Implode est surutilisé par PKWARE : l’Implode DCL/TERSE est distinct de l’ancien Implode PKZIP, un prédécesseur de Deflate. L’Implode DCL est non documenté en partie à cause de son caractère propriétaire détenu par IBM, mais Mark Adler a néanmoins fourni un décompresseur appelé « blast » aux côtés de zlib.
EncryptionEdit
ZIP supporte un système de cryptage symétrique simple basé sur un mot de passe généralement connu sous le nom de ZipCrypto. Il est documenté dans la spécification ZIP, et connu pour être sérieusement défectueux. En particulier, il est vulnérable aux attaques par texte connu, qui sont dans certains cas aggravées par de mauvaises implémentations des générateurs de nombres aléatoires.
De nouvelles fonctionnalités, y compris de nouvelles méthodes de compression et de cryptage (par exemple AES), ont été documentées dans la spécification du format de fichier ZIP depuis la version 5.2. Un standard ouvert basé sur l’AES développé par WinZip (« AE-x » dans APPNOTE) est également utilisé par 7-Zip et Xceed, mais certains vendeurs utilisent d’autres formats. PKWARE SecureZIP (SES, propriétaire) prend également en charge les méthodes de chiffrement RC2, RC4, DES, Triple DES, le chiffrement et l’authentification par certificat numérique (X.509), ainsi que le chiffrement de l’en-tête d’archive. Il est cependant breveté (voir § Controverse sur le cryptage fort).
Le cryptage des noms de fichiers est introduit dans la spécification 6.2 du format de fichier .ZIP, qui crypte les métadonnées stockées dans la partie Répertoire central d’une archive, mais les sections En-tête local restent non cryptées. Un archiveur conforme peut falsifier les données de l’en-tête local lorsqu’il utilise le cryptage du répertoire central. Depuis la version 6.2 de la spécification, les champs Compression Method et Compressed Size dans Local Header ne sont pas encore masqués.
ZIP64Edit
Le format .ZIP original avait une limite de 4 GiB (232 octets) sur diverses choses (taille non compressée d’un fichier, taille compressée d’un fichier et taille totale de l’archive), ainsi qu’une limite de 65 535 (216) entrées dans une archive ZIP. Dans la version 4.5 de la spécification (qui n’est pas la même que la v4.5 d’un outil particulier), PKWARE a introduit les extensions du format « ZIP64 » pour contourner ces limitations, augmentant les limites à 16 EiB (264 octets). En substance, il utilise une entrée de répertoire centrale « normale » pour un fichier, suivie d’une entrée de répertoire « zip64 » facultative, qui comporte les champs les plus grands.
Le format de l’en-tête du fichier local et de l’entrée du répertoire central sont les mêmes dans ZIP et ZIP64, mais pour les tailles toujours 0xffffff stockées, et un champ supplémentaire existe toujours :
| Offset | Bytes | Description |
|---|---|---|
| 0 | 2 | ID de l’en-tête 0x0001 |
| 2 | 2 | Taille du fragment de champ supplémentaire (16, 24 ou 28) |
| 4 | 8 | Taille du fichier original non compressé |
| 12 | 8 | Taille des données compressées |
| 20 | 8 | Offset de l’enregistrement d’en-tête local |
| 28 | 4 | Numéro du disque sur lequel ce fichier commence |
D’autre part, le format de l’EOCD pour ZIP64 est légèrement différent de celui de la version ZIP normale (voir appnote section 4.3.14).
| Offset | Bytes | Description |
|---|---|---|
| 0 | 4 | Fin de la signature du répertoire central = 0x06064b50 |
| 4 | 8 | Taille de l’EOCD64 -. 8 |
| 12 | 2 | Version faite par |
| 14 | 2 | Version nécessaire pour extraire (minimum) |
| 16 | 4 | Numéro de ce disque |
| 20 | 4 | Disque où commence le répertoire central |
| 24 | 8 | Nombre d’enregistrements du répertoire central sur ce disque |
| 32 | 8 | Nombre total d’enregistrements du répertoire central |
| 40 | 8 | Taille du répertoire central (octets) |
| 48 | 8 | Offset du début du répertoire central, par rapport au début de l’archive |
| 56 | n | Commentaire (jusqu’à la taille de EOCD64) |
Il n’est pas non plus nécessairement le dernier enregistrement du fichier, un localisateur de fin de répertoire central facultatif pourrait suivre (20 octets supplémentaires à la fin).
L’explorateur de fichiers de Windows XP ne prend pas en charge ZIP64, mais celui de Windows Vista et des versions ultérieures le font. De même, certaines bibliothèques d’extension supportent ZIP64, comme DotNetZip, QuaZIP et IO::Compress::Zip en Perl. Le fichier zip intégré de Python le prend en charge depuis la version 2.5 et le propose par défaut depuis la version 3.4. Le module intégré java.util.zip d’OpenJDK prend en charge ZIP64 depuis la version Java 7. L’API Java d’Android supporte ZIP64 depuis Android 6.0. L’utilitaire d’archivage de Mac OS Sierra ne prend notamment pas en charge ZIP64, et peut créer des archives corrompues alors que ZIP64 serait nécessaire. Toutefois, la commande ditto fournie avec Mac OS permet de décompresser les fichiers ZIP64. Les versions plus récentes de Mac OS sont livrées avec les outils de ligne de commande zip et unzip d’info-zip, qui prennent en charge Zip64 : pour vérifier, exécutez zip -v et recherchez « ZIP64_SUPPORT ».
Combinaison avec d’autres formats de fichiersEdit
Le format de fichier .ZIP permet qu’un commentaire contenant jusqu’à 65 535 (216-1) octets de données se trouve à la fin du fichier après le répertoire central. De plus, comme le répertoire central spécifie le décalage de chaque fichier de l’archive par rapport au début, il est possible que la première entrée de fichier commence à un décalage différent de zéro, bien que certains outils, par exemple gzip, ne traitent pas les fichiers d’archive qui ne commencent pas par une entrée de fichier à l’offset zéro.
Ceci permet à des données arbitraires de se produire dans le fichier à la fois avant et après les données de l’archive ZIP, et à l’archive d’être encore lue par une application ZIP. Un effet secondaire de ceci est qu’il est possible de créer un fichier qui est à la fois une archive ZIP fonctionnelle et un autre format, à condition que l’autre format tolère des données arbitraires à sa fin, son début ou son milieu. Les archives auto-extractibles (SFX), de la forme supportée par WinZip, tirent avantage de cela, en ce sens qu’il s’agit de fichiers exécutables (.exe) conformes à la spécification PKZIP AppNote.txt, et qui peuvent être lus par des outils ou des bibliothèques zip conformes.
Cette propriété du format .ZIP, et du format JAR qui est une variante de ZIP, peut être exploitée pour cacher du contenu malveillant (comme des classes Java nuisibles) à l’intérieur d’un fichier apparemment inoffensif, comme une image GIF téléchargée sur le web. Cet exploit dit GIFAR a été démontré comme une attaque efficace contre des applications web telles que Facebook.
LimitesEdit
La taille minimale d’un fichier .ZIP est de 22 octets. Un tel fichier zip vide ne contient qu’un enregistrement de fin de répertoire central (EOCD) :
La taille maximale à la fois du fichier d’archive et des fichiers individuels qu’il contient est de 4 294 967 295 octets (232-1 octets, ou 4 GiB moins 1 octet) pour le ZIP standard. Pour ZIP64, la taille maximale est de 18 446 744 073 709 551 615 octets (264-1 octets, ou 16 EiB moins 1 octet).
Extensions propriétairesEdit
Champ supplémentaireEdit
.Le format de fichier ZIP comprend une facilité de champ supplémentaire dans les en-têtes de fichier, qui peut être utilisée pour stocker des données supplémentaires non définies par les spécifications ZIP existantes, et qui permet aux archiveurs conformes qui ne reconnaissent pas les champs de les sauter en toute sécurité. Les ID d’en-tête 0-31 sont réservés à l’usage de PKWARE. Les ID restants peuvent être utilisés par des vendeurs tiers pour un usage propriétaire.
Polémique sur le cryptage fortEdit
Lorsque WinZip 9.0 bêta public a été publié en 2003, WinZip a introduit son propre cryptage AES-256, en utilisant un format de fichier différent, ainsi que la documentation pour la nouvelle spécification. Les normes de cryptage elles-mêmes n’étaient pas propriétaires, mais PKWARE n’avait pas mis à jour APPNOTE.TXT pour inclure Strong Encryption Specification (SES) depuis 2001, qui avait été utilisé par les versions 5.0 et 6.0 de PKZIP. Le consultant technique de WinZip, Kevin Kearney, et le chef de produit de StuffIt, Mathew Covington, ont accusé PKWARE de retenir la SES, mais le directeur de la technologie de PKZIP, Jim Peterson, a affirmé que le cryptage basé sur les certificats était encore incomplet.
Dans un autre mouvement controversé, PKWare a demandé un brevet le 16 juillet 2003 décrivant une méthode pour combiner le ZIP et le cryptage fort pour créer un fichier sécurisé.
En fin de compte, PKWARE et WinZip ont accepté de soutenir leurs produits respectifs. Le 21 janvier 2004, PKWARE a annoncé le support du format de compression AES basé sur WinZip. Dans une version ultérieure de WinZip bêta, il a pu prendre en charge les fichiers ZIP basés sur SES. PKWARE a finalement publié la version 5.2 de la spécification du format de fichier .ZIP, qui documente le SES. Le projet de logiciel libre 7-Zip prend également en charge AES, mais pas SES dans les fichiers ZIP (tout comme son port POSIX p7zip).
Lorsque l’on utilise le cryptage AES sous WinZip, la méthode de compression est toujours définie sur 99, avec la méthode de compression réelle stockée dans un champ de données supplémentaires AES. En revanche, la spécification de chiffrement fort stocke la méthode de compression dans le segment d’en-tête de fichier de base de Local Header et Central Directory, à moins que Central Directory Encryption ne soit utilisé pour masquer/chiffrer les métadonnées.