O SRT tem pouca influência na capacidade geral de reconhecimento de palavras. Embora pareça haver uma suposição ou abordagem de trabalho em nosso campo (e mesmo dentro da comunidade de pesquisa) para usar o ponto de dados de 50% para prever o desempenho máximo do processamento de fala, isto é, de fato, um esforço sem qualquer fundamento clínico ou teórico.
É viável usar o Limiar de Reconhecimento de Fala (SRT) como uma medida preditiva de uma pontuação de reconhecimento de palavras (WRS) individual? Durante o processo de seleção do aparelho auditivo, uma decisão precisa ser tomada entre dois aparelhos auditivos ou entre as configurações de desempenho em um único aparelho auditivo. Uma configuração de desempenho produz um SRT que é melhor do que a outra. Quais os principais fatores por trás de uma decisão clínica pesam na equação entre os profissionais de distribuição de hoje? Ao visualizar um aparelho capaz de fornecer um SRT melhor a um nível de apresentação de sinal inferior ou a uma melhor relação sinal/ruído (SNR, ou relação S/N) em comparação com outros aparelhos, o que o profissional deve esperar de um aparelho que tenha um SRT melhor? Escolheremos este dispositivo porque, como esperado em nosso julgamento profissional, levaria a um melhor desempenho de compreensão da fala no mundo real?
Quando um aparelho auditivo digital com sistema direcional é associado a SRTs ligeiramente melhores em termos de SNR, muitos de nós selecionaríamos esse aparelho auditivo e esperaríamos ver melhores escores de inteligibilidade de fala quando o sistema direcional se engajar. Da mesma forma, quando um aparelho auditivo assistido (ALD), como um sistema FM, mostra um pouco mais de benefício na TRS do que outros aparelhos, muitos clínicos também tenderiam a inferir, de forma razoável, que o ALD vai produzir um desempenho superior de compreensão da fala.1
Indeed, a literatura tem até tentado prever o desempenho de compreensão da fala dos sujeitos a partir do limiar de reconhecimento de sentenças com base na inclinação da curva da função Performance-Intensity (P-I) a partir da qual o limiar de reconhecimento de sentenças foi obtido. Como apenas um exemplo, podemos ler na literatura que, de acordo com o manual de teste, uma diferença de 1 dB S/N é equivalente a 9 pontos percentuais na inteligibilidade das sentenças. Assim, uma diferença de 4 dB na razão S/N entre grupos implica em escores de inteligibilidade de fala aproximadamente 36% mais pobres no bilíngue do que os falantes nativos monolíngues.
Evidentemente, a suposição subjacente a todas estas abordagens é que se pode fazer uma previsão ou uma estimativa do desempenho de inteligibilidade de fala de um indivíduo a partir da SRT. No entanto, esta abordagem amplamente aceita é suficientemente precisa para uso clínico? Podemos realmente ser capazes de estimar ou prever uma pontuação de compreensão da fala dos usuários de aparelhos auditivos simplesmente com base nesse ponto de 50%?
Considerações teóricas
Como o limiar de tom puro (PT), que é o nível mais suave no qual o sinal de tom puro é pouco perceptível 50% do tempo, o limiar de reconhecimento da fala (SRT) é o nível limiar no qual o sinal de fala é pouco reconhecível 50% do tempo.3-5 Mais uma vez, como a debulhada de tom puro que representa uma sensibilidade auditiva individual ao sinal de tom puro – a SRT representa uma sensibilidade auditiva individual aos sinais da fala. Por definição e pela natureza do procedimento de teste para a determinação do limiar, a SRT indica uma resposta do indivíduo ao sinal de fala no nível do limiar. Esta é uma nuança importante: A SRT indica a resposta aos sinais de fala quando o sinal de fala é apresentado a um nível bastante suave, de tal forma que é quase perceptível/reconhecível durante cerca de 50% do tempo. Uma vez que o sinal de fala está naquele nível pouco reconhecível e o trabalho de adivinhação está naturalmente envolvido durante o teste, a SRT é a resposta do nível limite, ficando à parte da resposta do nível de supratressão do indivíduo.
Por outro lado, o Resultado de Reconhecimento de Palavras (WRS) representa todas as respostas possíveis quando o sinal de fala é apresentado em vários níveis de ruído acima do limiar do indivíduo.3-5 O WRS mostra o quão bem o paciente pode ouvir e processar sinais de fala em vários níveis de limiar superior; em contraste, o SRT indica o quão sensível a pessoa é à audição de sinais de fala em níveis específicos pouco perceptíveis. Portanto, em comparação com a representação de todas as respostas possíveis do WRS em função dos níveis de apresentação do sinal, o SRT é conhecido no campo como o ponto de 50% na curva Performance-Intensity. O ponto take-home aqui é que o SRT é a resposta de nível limiar enquanto que o WRS é a resposta de nível supra-limiar a estímulos de fala; de forma alguma o SRT indica ou insinua respostas de nível supra-limiar.
Examinar SRT e WRS para diferentes tipos de perda auditiva
Para ilustrar o acima, a Figura 1 mostra quatro SRTs hipotéticos exibidos como quatro pontos de dados em função do WRS (versus níveis de apresentação do sinal de fala). Os quatro pontos de dados representam o nível de sinal mais suave no qual o sinal de fala é pouco perceptível 50% do tempo para indivíduos com sensibilidade auditiva normal e vários graus de perda auditiva de cerca de 50 dB, 70 dB e 90 dB HL. Os quatro pontos de dados também indicam que o desempenho do reconhecimento da palavra é de 50%, uma vez que os indivíduos dos quatro tipos de estado auditivo só conseguem reconhecer os sinais da fala com 50% de precisão quando os sinais da fala são apresentados nos seus níveis limiares, respectivamente.
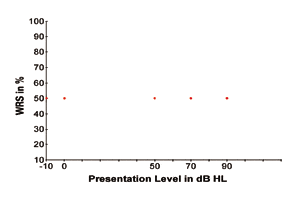 FIGURAR 1. Quatro limiares hipotéticos de reconhecimento de fala (SRTs) exibidos como quatro pontos de dados para audição normal e vários graus de perda auditiva.
FIGURAR 1. Quatro limiares hipotéticos de reconhecimento de fala (SRTs) exibidos como quatro pontos de dados para audição normal e vários graus de perda auditiva.
Então, como seria a curva de desempenho-intensidade quando os sinais de fala são apresentados nos seus níveis de limiar? Com base nestes quatro pontos de dados, podemos estimar seus escores máximos de reconhecimento de palavras quando os sinais de fala são apresentados em vários níveis superiores? Da mesma forma, se estes quatro pontos de dados representam os SRTs com um aparelho auditivo adequado em uso, somos capazes de prever uma pontuação máxima de inteligibilidade de fala após recebermos o benefício de um aparelho auditivo?
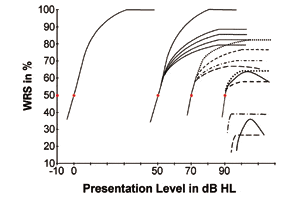 FIGURA 2. Hipotético Desempenho – Curvas de Intensidade mostrando vários escores máximos de reconhecimento de palavras (eixo y) para os quatro limiares hipotéticos de reconhecimento de fala (SRTs) como mostrado na Figura 1, que representa o nível de apresentação em que a fala mal é reconhecível 50% do tempo. Deve-se notar que as curvas aqui mostradas são apenas uma porção limitada da família de todo o desempenho de processamento de fala possível com os diferentes graus de perda auditiva.
FIGURA 2. Hipotético Desempenho – Curvas de Intensidade mostrando vários escores máximos de reconhecimento de palavras (eixo y) para os quatro limiares hipotéticos de reconhecimento de fala (SRTs) como mostrado na Figura 1, que representa o nível de apresentação em que a fala mal é reconhecível 50% do tempo. Deve-se notar que as curvas aqui mostradas são apenas uma porção limitada da família de todo o desempenho de processamento de fala possível com os diferentes graus de perda auditiva.
Figure 2 pode servir para responder a estas questões. Com base em experiências clínicas e considerações teóricas, exemplos de algumas hipotéticas curvas de Performance-Intensidade (P-I) foram traçadas para demonstrar a inter-relação e o padrão de resposta dos escores de reconhecimento de palavras para indivíduos com estado normal de audição e vários graus de perda auditiva.
Para o estado normal de audição. Na Figura 2, a curva na extrema esquerda (por exemplo, passando o nível de apresentação de 0 dB) pode ser usada como a curva que representa os indivíduos com audição normal. Esta é a curva frequentemente vista nos livros didáticos indicando que o desempenho aumenta juntamente com o aumento do nível de apresentação do sinal com uma inclinação fixa, se medida com um procedimento de teste fixo e um determinado material de teste de fala. O desempenho atinge o WRS máximo em cerca de 40 dB Nível de Sensação (SL) acima do SRT.
Para perdas de audição de 50 dB. Na Figura 2, à direita da curva para indivíduos com audição normal, um grupo de curvas passando o nível de apresentação de 50 dB representa respostas típicas sobre o WRS para a categoria de 50 dB de perda de audição dos ouvintes. Dentre esta categoria de 50 dB-hearing-loss (5 curvas de linha sólida), a curva à esquerda mostra a função P-I quando a perda auditiva de 50 dB é uma perda auditiva condutiva por natureza. Note que a curva é exatamente a mesma inclinação e atinge a mesma WRS máxima que a de indivíduos com audição normal, pois a perda auditiva condutiva é, por natureza, uma perda de sensibilidade que não envolve nenhuma patologia no ouvido interno e estruturas mais elevadas.
Quando a perda auditiva de 50 dB envolve perda auditiva mista na natureza (por exemplo, um componente leve da perda auditiva neurossensorial), então a capacidade de processamento de sinal dos sujeitos é reduzida. Suas curvas P-I (as outras 4 curvas sólidas neste grupo de curvas) ainda podem subir, mas com um declive mais acentuado e ficar achatadas a uma WRS máxima mais baixa, em comparação com a curva dos sujeitos com audição normal ou da perda auditiva condutiva.
Desta categoria de perda auditiva de 50 dB, pode-se ver que todas as curvas mostram a mesma SRT, mas com grande diferença individual na WRS máxima, possivelmente de perto de 70% a 100%.
Para perdas auditivas de 70 dB. Mais à direita na Figura 2, há 4 curvas de linha tracejada passando pelo ponto de dados do SRT de 70 dB, culminando em um WRS máximo diferente. Estas representam os possíveis padrões de resposta e diferenças individuais na função P-I para a categoria de perda auditiva de 70 dB. A categoria de perda auditiva em torno de 70 dB SRT é normalmente a maioria da população de clientes observada na clínica de aparelhos auditivos típica.
Deve ser imediatamente visível que maiores variações na TRE máxima, como mostrado na Figura 2, podem resultar deste tipo de perda. Também é interessante notar que algumas curvas tracejadas atingem um desempenho de WRS superior às da categoria de perda auditiva de 50 dB, enquanto outras mostram um desempenho que é, em geral, menor. Uma curva (a curva de linha tracejada inferior) mostra um pequeno grau de fenômeno de rollover: WRS mais pobre em níveis de apresentação mais altos uma vez que o WRS mais alto é atingido.
A grande quantidade de variação individual revelada a partir das curvas P-I está frequentemente relacionada com a perda auditiva neurossensorial (SNHL) com a patologia das células capilares e das fibras neurais envolvidas. Estas perdas frequentemente apresentam tanto uma perda de sensibilidade como um componente de perda de claridade, com a perda de claridade nos sinais de fala variando dramaticamente dependendo de fatores como, mas não limitado a, grau de perda auditiva, forma da perda auditiva, etiologia da perda auditiva, condição patológica da estrutura do cérebro da orelha, extensão dos danos às células capilares externas e/ou internas, danos e efeito na amplificação coclear ativa, função residual das células capilares internas, dano nas fibras nervosas retrococleares, efeito na sincronia da descarga neural, proporção de lesão retrococlear versus lesão coclear, efeito da reorganização tonotópica do córtex auditivo, duração da perda auditiva, histórico de uso de aparelhos auditivos, quantidade de tempo associada à estimulação auditiva (in)adequada, casos prelíngues versus pós-língues, estilo de vida e ambiente de vida, uma habilidade lingüística individual (ver barra lateral, Existe uma Coisa Típica de Perda Auditiva de 70 dB?).
Claramente, uma miríade de fatores como discutidos na barra lateral, incluindo aqueles nos domínios patológicos e linguísticos interagem uns com os outros como os mecanismos subjacentes influenciando os desempenhos do processamento do sinal de fala. Portanto, grandes diferenças individuais no padrão de resposta do processamento de sinais de fala, inclinação da curva P-I e WRS máxima, devem ser razoavelmente expectáveis entre os sujeitos. Para a categoria de perda de audição de 70dB da SNHL, o que é mostrado na Figura 2 é apenas uma parte das possíveis funções P-I com várias WRS máximas alcançadas, todas com um mesmo SRT.
Por isso, a Figura 2 e o senso comum sugerem que prever o possível WRS máximo a partir do SRT é uma abordagem imprudente sem as devidas advertências.
Para perdas auditivas de 90 dB. Quando o grau de perda auditiva se move para a categoria de perda auditiva de 90 dB, a SNHL normalmente envolveria o componente neural para complementar o componente sensorial, produzindo perdas muito maiores na claridade do sinal junto com a perda de sensibilidade. Estes tipos de perdas sugerem mais danos na região retrococlear e em outras estações de relé neural ao longo de vias auditivas mais elevadas. Assim, mais deficiências neurológicas em vias mais elevadas, com maior chance de dis-sincronia da descarga neural e distúrbios do processamento auditivo, podem se tornar uma possibilidade e revelar um desempenho ainda pior no processamento do sinal (em comparação com a categoria de perda de 70 dB de audição). Todos os fatores discutidos, como o grau real da perda auditiva nas frequências, etiologia particular, localização e gravidade da lesão no ouvido interno e vias auditivas, reorganização tonotópica, capacidade linguística individual, etc., interagiriam entre si e resultariam em diferentes padrões de resposta e declives da curva P-I. Mais uma vez, grandes variações no desempenho máximo do processamento do sinal de fala seriam esperadas.
Na Figura 2, três curvas (duas tracejadas e uma curva de linha sólida passando o ponto de dados de 90 dB) foram traçadas para mostrar inclinações variáveis com várias WRS máximas que podem ser alcançadas por indivíduos nesta categoria de perda auditiva. A curva da linha sólida mostra um fenômeno de roll-over ainda maior em comparação com a categoria de perda auditiva de 70 dB. Todas as três curvas são colocadas para mostrar que seu WRS máximo é provavelmente menor do que o da categoria de perda auditiva de 70-dB.
Obviamente, sabemos que alguns sujeitos com cerca de 90 dB de perda auditiva mostrariam um WRS extremamente e excepcionalmente bom em comparação com aqueles com perda auditiva mesmo leve. Este tipo de exceção não é totalmente incomum; ele suporta ainda mais a grande variabilidade nas funções de desempenho do processamento de sinais e do sistema auditivo. O ponto único de discussão aqui é que todas estas curvas estão passando pelo mesmo ponto de dados SRT de 90 dB e produzindo um WRS máximo radicalmente diferente. Assim como no grupo de perda de 70 dB, existem grandes diferenças individuais.
No canto inferior direito da Figura 2, mais três curvas são exibidas, mostrando algumas possíveis curvas P-I para aqueles com perda auditiva maior que 90 dB HL. Com este profundo grau de perda auditiva e fatores de confusão (como discutido acima), grandes diferenças individuais na inclinação da curva de resposta e a WRS máxima devem ser antecipadas.
A singularidade destas três curvas é que os sujeitos com desempenho de reconhecimento de fala ascendente podem nem mesmo ser capazes de alcançar o ponto de 50%. Além disso, tanto o WRS máximo quanto o fenômeno de rollover podem ser ainda mais pobres ou mais pronunciados, respectivamente, que as perdas de 70 dB.
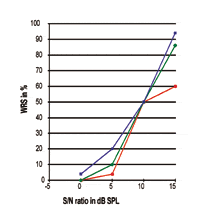 FIGURA 3. Três curvas individuais de Performance-Intensidade expressas na relação S/N. Note que o ponto de 50% está exatamente em 10 dB SPL enquanto a inclinação e o desempenho máximo do processamento da fala são claramente diferentes.
FIGURA 3. Três curvas individuais de Performance-Intensidade expressas na relação S/N. Note que o ponto de 50% está exatamente em 10 dB SPL enquanto a inclinação e o desempenho máximo do processamento da fala são claramente diferentes.
Provas Clínicas
Alguns dados clínicos empíricos podem ser úteis para demonstrar o acima exposto. Numa tentativa de estudar o efeito do limiar de compressão na inteligibilidade da fala, 12 sujeitos com SNHL leve a grave acima de 2 kHz ouviram através de um aparelho auditivo programável as frases alvo do teste Speech In Noise (SIN). Exemplos do desempenho de processamento de fala destes sujeitos foram seleccionados e traçados como curvas P-I relativas ao SNR (Figuras 3-6).
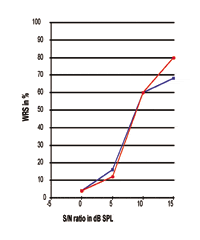 FIGURA 4. Duas curvas individuais de Performance-Intensidade expressas na razão S/N. Note que o ponto 50% está em torno de 9,06 dB SPL enquanto a inclinação e o desempenho máximo do processamento da fala são claramente diferentes.
FIGURA 4. Duas curvas individuais de Performance-Intensidade expressas na razão S/N. Note que o ponto 50% está em torno de 9,06 dB SPL enquanto a inclinação e o desempenho máximo do processamento da fala são claramente diferentes.
Referindo às Figuras 3-5, é claro que diferentes sujeitos de desempenho WRS podem ser exatamente os mesmos no ponto 50%, enquanto a inclinação da curva e o desempenho máximo são completamente diferentes um do outro. Todas essas curvas mostram que o SRT é, de fato, apenas o ponto de dados de 50% ao longo da curva de resposta; existem grandes diferenças em relação à inclinação da curva e ao desempenho máximo de processamento no mundo real. Os números indicam que o ponto de dados de 50% não tem relação próxima com o desempenho máximo de processamento que seria alcançado pelos indivíduos. Assim, a SRT não deve ser usada como sendo representativa das respostas de intensidade de desempenho.
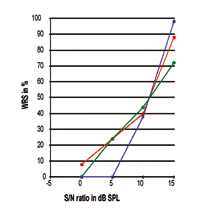 FIGURA 5. Três curvas de Performance-Intensidade individuais expressas na razão S/N. Observe que o ponto de 50% está em torno de 10,75 dB SPL enquanto a inclinação e o desempenho máximo do processamento da fala são claramente diferentes.
FIGURA 5. Três curvas de Performance-Intensidade individuais expressas na razão S/N. Observe que o ponto de 50% está em torno de 10,75 dB SPL enquanto a inclinação e o desempenho máximo do processamento da fala são claramente diferentes.
Esta informação também sugere que, ao aconselhar estudantes de pós-graduação e formular projetos de pesquisa, pode não ser sábio usar a SRT como critério primário do estudo. Embora alguns testes sejam agora concebidos para encontrar o ponto 50% do desempenho do processamento de fala dos sujeitos, a interpretação do ponto 50% ou SRT ou expresso em termos do nível de apresentação ou SNR deve ser feita com cautela. O desempenho do processamento da fala é um fenômeno mais complicado.
Na Figura 6, as três curvas P-I individuais estão com um ponto de 50% totalmente diferente. A curva vermelha representa um indivíduo com SNHL suave de alta freqüência, enquanto as outras duas curvas foram obtidas de indivíduos com SNHL moderada a severa de alta freqüência. Na verdade, a inclinação acentuada e o desempenho quase perfeito do processamento da fala demonstrado pela curva vermelha são semelhantes às respostas obtidas por indivíduos com audição normal.
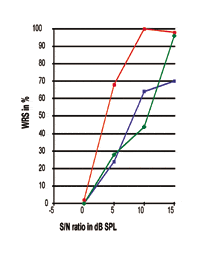 FIGURA 6. Três curvas individuais de desempenho-intensidade com seus pontos de 50% a 3,35, 8,51, e 9,83 dB SPL respectivamente. A curva vermelha com círculo preenchido, cuja inclinação e desempenho máximo de processamento de fala são semelhantes aos obtidos por indivíduos com perda auditiva neurossensorial leve de alta frequência, enquanto as outras duas curvas são obtidas de indivíduos com perda auditiva neurossensorial moderada a grave de alta frequência.
FIGURA 6. Três curvas individuais de desempenho-intensidade com seus pontos de 50% a 3,35, 8,51, e 9,83 dB SPL respectivamente. A curva vermelha com círculo preenchido, cuja inclinação e desempenho máximo de processamento de fala são semelhantes aos obtidos por indivíduos com perda auditiva neurossensorial leve de alta frequência, enquanto as outras duas curvas são obtidas de indivíduos com perda auditiva neurossensorial moderada a grave de alta frequência.
Tal pode ser esperado, uma vez que indivíduos com perda auditiva neurossensorial leve podem sofrer de menos danos no sistema otorrinolaringológico. Para as curvas obtidas de indivíduos com SNHL moderada a severa de alta frequência, podem ser vistos maiores graus de diferenças individuais, como discutido anteriormente. Ao observar estas duas curvas, observe que aquela com o melhor ponto 50% (curva azul), comparado com a curva verde, não produz um WRS melhor. Isto indica que, no mundo real onde existem variações individuais, um melhor ponto de 50% (SRT) nem sempre está associado a um melhor desempenho máximo no processamento da fala.
Sumário
1) O desempenho do processamento de fala de um indivíduo é dinamicamente afetado por uma série de fatores, incluindo grau, tipo, forma da perda auditiva, duração da perda auditiva e muitas outras condições fisiopatológicas no sistema otorrinolaringológico e até mesmo a habilidade/profile linguístico do indivíduo.
2) O limiar de reconhecimento da fala é apenas o ponto de dados de 50% na curva P-I do desempenho do processamento de fala dos indivíduos.
3) Um indivíduo com 50% de ponto de dados (SRT) na curva P-I poderia estar em unidade com outro paciente, mas a inclinação e o desempenho de processamento desses dois pacientes poderiam ser completamente diferentes um do outro.
4) A relação entre o padrão de resposta, o SRT, a inclinação da curva P-I e o desempenho máximo de processamento é extremamente dinâmica e imprevisível, devido à variabilidade individual.
5) Uma resposta com melhor SRT não está necessariamente associada a melhor WRS. Embora muitas vezes pareça haver uma suposição/abordagem de trabalho em nosso campo para usar o ponto de dados de 50% para prever o desempenho máximo do processamento da fala, este é de fato um esforço sem fundamento clínico/teórico e precisão.
6) Ao realizar a adaptação de aparelhos auditivos ou ALD, tais como selecionar, modificar e afinar, ou ao estabelecer expectativas realistas para os benefícios da amplificaçãoone não deve ser excessivamente dependente do ponto de dados de 50%. Ao invés disso, a obtenção de uma curva P-I mais completa com desempenho máximo no processamento da fala é uma abordagem mais pragmática para o clínico do mundo real.
Is There Such a Thing as a Typical 70 dB Hearing Loss?
É evidente que perdas auditivas mais graves podem trazer variações bastante notáveis no WRS. Perdas auditivas acima de 70 dB são frequentemente complexas e multifacetadas. Por exemplo, aqueles pacientes com escores de 70 dB de SRT podem ter limiares de puretone totalmente diferentes nas frequências. Em outras palavras, os pacientes podem ter várias magnitudes de perda auditiva em frequências de tons puros discretos, mas todos podem parecer ter uma TRS em torno de 70 dB HL. Os indivíduos também podem ter diferentes formas de audiograma, incluindo uma frequência plana, inclinada, baixa frequência, alta frequência, precipitada ou até mesmo uma perda auditiva de mordida de biscoito, mas ainda mostram uma TRS de cerca de 70 dB HL.
Isso significa que a localização e gravidade da lesão na região de alta versus baixa freqüência (por exemplo, basal versus apical) da membrana basilar no ouvido interno pode ser bem diferente entre estes sujeitos. Além disso, diferentes graus de lesão seriam induzidos na função ativa de amplificação coclear; diferentes eletromotilidade externa das células capilares levariam a diferentes habilidades de sensibilidade auditiva e discriminação de freqüência dos sinais.6-9 Todas essas condições patológicas resultariam em processamento de sinais com baixa sensibilidade auditiva e análise de freqüência reduzida, além de diferentes quantidades de distorção no processamento de consoantes e vogais. E, por sua vez, estas seriam refletidas por vários escores de reconhecimento de fala.
Se a patologia envolver mais danos sobre as células ciliadas internas versus externas, seu efeito sobre o processamento do sinal e a quantidade de distorção durante o processamento do sinal provavelmente seria maior e maior, pois 95% das fibras nervosas auditivas transportam informações das células ciliadas internas, enquanto apenas cerca de 5% dos nervos auditivos internos privam as células ciliadas externas.9-10 Quando a patologia ocorre mais na região retrococlear do que na região coclear, pode ser esperada uma maior perda de clareza e o fenômeno do rollover no reconhecimento da fala. Sabe-se também que, com danos nas vias auditivas superiores, os processos de nível superior, tais como diferenciação entre figura auditiva e solo, integração binaural, separação binaural e liberação do mascaramento, podem ser todos afetados. Isso também pode levar a um reconhecimento variado e aparentemente desproporcionalmente mais pobre da fala nas tarefas de escuta em ruído.11,12 Várias etiologias como infecção bacteriana/vírus do ouvido interno, perda auditiva induzida por ruído/droga, fenômeno de circulação sanguínea/hemorragia, neuroma acústico, APD e dissincronia auditiva, doença auto-imune do ouvido interno e perda auditiva hereditária podem resultar em condições patológicas que produzem diferentes localizações e severidades dos danos sobre as estruturas sensoriais/neuronais, com os desempenhos de reconhecimento de fala resultantes ainda sendo associados a uma SRT de 70 dB.11,12
Outro fator vem da área de reorganização tonotópica do córtex auditivo de sujeitos animais que sofrem de SNHL. Sabe-se que, com a SNHL sustentada ao longo do tempo, uma área monotônica expandida no córtex auditivo é estabelecida na qual os neurônios têm sua freqüência característica original alterada para uma nova freqüência (mais baixa). Suas curvas de sintonia mostram limiares elevados, baixa discriminação de freqüência e hipersensibilidade a outras freqüências que não a sua freqüência característica original.13,14
Também tem sido sugerido que este efeito tonotópico reorganizador devido à plasticidade cerebral em resposta à estimulação auditiva inadequada e assimétrica ao longo do tempo está intimamente relacionado com a privação/adaptação auditiva em sujeitos humanos que têm WRS pobre em palavras e frases monossilábicas, e mesmo com outras performances de alto nível de processamento de sinal envolvendo separação e integração binaural.13-17 Aqui, para os sujeitos da categoria de perda auditiva de 70 dB, seus diferentes graus de perda auditiva nas frequências, diferentes localizações/severidades de lesão e muitas outras variáveis podem se somar como fatores de confusão para a formação da reorganização tonotópica do córtex auditivo.
Isto significa que, entre os sujeitos desta categoria, uma área monotônica diferente no córtex auditivo individual perde sua capacidade original de processamento de sinal. Ela fica sintonizada em uma freqüência diferente, várias porcentagens dos neurônios ficam menos sintonizadas, e mudanças únicas na disposição do contorno de iso-freqüência no córtex podem ocorrer, assim como vários graus de elevação do limiar e hipersensibilidade dos neurônios a outras freqüências além de sua melhor freqüência. Várias reduções na discriminação de freqüência e outras maiores habilidades de processamento neurológico devem então ser esperadas. Essas diferentes características da reorganização tonotópica resultante, por sua vez, levam a variações no desempenho dos sujeitos em ruído de fundo, processamento de sinais e resoluções de frequência e intensidade, resultando em diferenças no reconhecimento da fala.
Outras, não há dúvida de que a capacidade linguística de cada indivíduo é uma grande macrovariável no desempenho de compreensão da fala das pessoas. Peoples linguistic abilitiestheir skills in semantic form, syntactic structure, and pragmatic language use, etcdiffer and may help or hindr them during communication breaksdowns (eg, when trying to fill in the blanks using linguistic and contextual cues). Para aqueles na categoria de perda auditiva de 70dB, que já têm dificuldade em entender a fala, a habilidade linguística seria uma macrovariável interagindo com sua perda auditiva e influenciando o WRS, especialmente quando o WRS é medido usando materiais de frases em ruído de fundo. Além disso, a complexidade do perfil linguístico das pessoas bilíngües pode ser agravada por variáveis como idade de aquisição da segunda língua, língua dos pais, origem geográfica da aquisição, uso da língua, tempo de exposição à segunda língua, etc, e todas essas variáveis são influentes no desempenho do processamento da fala/língua, especialmente durante tarefas de escuta com ruído.18-20
1. Lewis MS, Crandell CC. Aplicações da tecnologia de modulação por frequência (FM). Apresentado em: A 17ª Convenção Anual da Academia Americana de Audiologia (Curso Instrucional IC-103), Washington, DC;2005.
2. Von Hapsburg D, Pena E. Compreender o bilinguismo e o seu impacto na audiometria de voz. J Speech Lang Hear Res. 2002; 45: 202-213.
3. Newby HA, Popelka GR. Audiologia. 6ª ed. Englewood Cliffs, NJ: Prentice Hall Inc.; 1992:126-201.
4. Stach BA. Audiologia Clínica: Uma Introdução. San Diego, Califórnia: Singular Publishing Group Inc.; 1998:193-249.
5. DeBonis DA, Donohue CL. Survey of Audiology: Fundamentos para Audiologistas e Profissionais de Saúde. Boston, Massachusetts: Allyn e Bacon; 2004:77-164.
6. Brownell W, Bader C, Bertrand D, de Ribaupierre Y. Evocou respostas mecânicas de células capilares externas cocleares isoladas. Ciência. 1985;227(11):194-196.
7. Dallos P, Evans B, Hallworth R. Natureza do elemento motor em mudanças de forma eletrocinética das células capilares externas cocleares. Natureza. 1991;350(14):155-157.
8. Dallos P, Martin R. A nova teoria da audição. Jornada da Audição. 1994; 47(2):41-42.
9. Ryan AF. Novas visões da função coclear. In: Robinette MS, Glattke TJ, eds. Emissões Otoacústicas: Aplicações clínicas. 1ª ed. Nova York, NY: Thieme Medical Publishers Inc.; 1997:22-45.
10. Gelfand SA. Hearing: An Introduction to Psychological and Physiological Acoustics. 3ª ed. New York, NY: Marcel Dekker Inc.; 1998:47-82.
11. Mencher GT, Gerber SE, McCombe A. Audiologia e Disfunção Auditiva. Needham Heights, Mass: Allyn e Bacon; 1997:105-232.
12. Martin FN, Clark JG. Introduction to Audiology. 9ª ed. Boston, Massachusetts, Mass: Allyn and Bacon; 2006:277-346.
13. Harrison RV, Nagasawa A, Smith DW, Stanton S, Mount RJ. Reorganização do córtex auditivo após a perda auditiva coclear neonatal de alta freqüência. Res. Auditiva 1991;54:11-19.
14. Dybala P. Efeitos da perda auditiva periférica na organização tonotópica do córtex auditivo. Jornada Auditiva. 1997;50(9):49-54.
15. Silman S, Gelfand SA, Silverman CA. Privação auditiva tardia: Efeitos de aparelhos auditivos monoauriculares versus biauriculares. J Acoust Soc Amer. 1984;76(5):1357-1362.
16. Palmer CV. Deprivação, aclimatação, adaptação: O que significam para os seus aparelhos auditivos? Jornada Auditiva. 1995;47(5):10,41-45.
17. Neuman AC. Privação auditiva tardia: Uma revisão da pesquisa passada e uma avaliação das necessidades futuras de pesquisa. Audição auditiva. 1996;17(3):3s-13s.
18. Grosjean F. Processing mixed language: issues, findings, and models. In: de Groot AMB, Kroll JF, eds. Tutoriais em Bilinguismo: Perspectivas Psicolinguísticas. Mahwah, NJ: Lawrence Erlbaum Associates; 1997:225-251.
19. Mayo LH, Florentine M, Buus S. Age of second-language acquisition and perception of speech in noise. J Speech Lang Hear Res. 1997;40:686-693.
20. Von Hapsburg D, Champlin CA, Shetty SR. Limites de recepção de frases em ouvintes bilingues (espanhol/inglês) e monolingues (inglês). J Amer Acad Audiol. 2004;15(1):88-98.