La TRS tiene poca relación con la capacidad general de reconocimiento de palabras. Aunque parece haber una suposición o enfoque de trabajo en nuestro campo (e incluso dentro de la comunidad de investigación) para utilizar el punto de datos del 50% para predecir el rendimiento máximo del procesamiento del habla, esto es, de hecho, un esfuerzo sin ningún fundamento clínico o teórico.
¿Es factible utilizar el Umbral de Reconocimiento del Habla (SRT) como una medida predictiva de la Puntuación de Reconocimiento de Palabras (WRS) de un individuo? Durante el proceso de selección de audífonos, es necesario tomar una decisión entre dos audífonos o entre los ajustes de rendimiento de un solo audífono. Uno de los ajustes de rendimiento produce una TRS mejor que el otro. ¿Qué factores principales detrás de una decisión clínica pesan en la ecuación entre los profesionales de la dispensación de hoy en día? Al ver que un dispositivo es capaz de proporcionar una mejor TER a un nivel de presentación de señal más bajo o a una mejor relación señal/ruido (SNR, o relación S/N) en comparación con otros dispositivos, ¿qué debe esperar el profesional de un dispositivo que tiene una mejor TER? Elegiremos este dispositivo porque, como es de esperar según nuestro criterio profesional, nos llevaría a un mejor rendimiento en la comprensión del habla en el mundo real?
Cuando se comprueba que un audífono digital con un sistema direccional se asocia con SRTs ligeramente mejores en términos de SNR, muchos de nosotros seleccionaríamos ese audífono y esperaríamos ver mejores puntuaciones de inteligibilidad del habla cuando el sistema direccional se activa. Del mismo modo, cuando un dispositivo de ayuda a la audición (ALD), como un sistema FM, muestra un beneficio ligeramente superior en SRT sobre otros dispositivos, muchos clínicos también tenderían a hacer una inferencia razonable de que el ALD va a producir un rendimiento de comprensión del habla superior.1
De hecho, la literatura ha intentado incluso predecir el rendimiento de comprensión del habla de los sujetos a partir del umbral de reconocimiento de frases basándose en la pendiente de la curva de la función Rendimiento-Intensidad (P-I) de la que se obtuvo el umbral de reconocimiento de frases. Como ejemplo, podemos leer en la literatura que, según el manual de la prueba, una diferencia de 1 dB en la relación S/N equivale a 9 puntos porcentuales en la inteligibilidad de las frases. Por lo tanto, una diferencia de 4 dB en la relación S/N entre grupos implica puntuaciones de inteligibilidad del habla aproximadamente un 36% más pobres en los hablantes nativos bilingües que en los monolingües.
Evidentemente, el supuesto subyacente de todos estos enfoques es que se puede hacer una predicción o una estimación del rendimiento de la inteligibilidad del habla de un individuo a partir de la TER. Sin embargo, ¿es este enfoque ampliamente aceptado lo suficientemente preciso para su uso clínico? ¿Podemos realmente estimar o predecir la puntuación de comprensión del habla de un usuario de audífonos simplemente basándonos en ese punto del 50%?
Consideraciones teóricas
Al igual que el umbral de tonos puros (PT), que es el nivel más suave en el que la señal de tonos puros es apenas perceptible el 50% del tiempo, el umbral de reconocimiento del habla (SRT) es el nivel de umbral en el que la señal del habla es apenas reconocible el 50% del tiempo.3-5 De nuevo, al igual que el umbral de tonos puros, que representa la sensibilidad auditiva de un individuo a las señales de tonos puros, el SRT representa la sensibilidad auditiva de un individuo a las señales del habla. Por definición y por la naturaleza del procedimiento de prueba para la determinación del umbral, la TER indica una respuesta del individuo a la señal del habla en el nivel del umbral. Este es un matiz importante: La TER indica la respuesta a las señales del habla cuando la señal del habla se presenta a un nivel bastante suave, de tal manera que sólo es casi perceptible/reconocible durante aproximadamente el 50% del tiempo. Dado que la señal del habla se encuentra en ese nivel apenas reconocible y que, naturalmente, hay que hacer conjeturas durante la prueba, la TER es la respuesta de nivel umbral, que se distingue de la respuesta de nivel supralumbral del individuo.
Por otro lado, la puntuación de reconocimiento de palabras (WRS) representa todas las respuestas posibles cuando la señal del habla se presenta a varios niveles de sonoridad por encima del umbral del individuo.3-5 La WRS muestra lo bien que el paciente puede oír y procesar las señales del habla a varios niveles supraumbrales; en cambio, la SRT indica lo sensible que es la persona para oír las señales del habla a niveles específicos apenas perceptibles. Por lo tanto, en comparación con el trazado de todas las respuestas posibles de la WRS en función de los niveles de presentación de la señal, la SRT se conoce en el campo como el punto del 50% en la curva de Rendimiento-Intensidad. El punto a tener en cuenta aquí es que la TER es la respuesta del nivel de umbral, mientras que la SRS es la respuesta del nivel supraumbral a los estímulos del habla; de ninguna manera la TER indica o insinúa respuestas supraumbral.
Examinando la TER y la SRS para diferentes tipos de pérdida auditiva
Para ilustrar lo anterior, la Figura 1 muestra cuatro TER hipotéticas mostradas como cuatro puntos de datos en función de la SRS (frente a los niveles de presentación de la señal del habla). Los cuatro puntos de datos representan el nivel de señal más suave en el que la señal del habla es apenas perceptible el 50% del tiempo para individuos con sensibilidad auditiva normal y varios grados de pérdida auditiva de alrededor de 50 dB, 70 dB y 90 dB HL. Los cuatro puntos de datos también indican que el rendimiento del reconocimiento de palabras es del 50%, ya que los individuos de los cuatro tipos de estado auditivo sólo pueden reconocer las señales del habla con una precisión del 50% cuando las señales del habla se presentan en sus niveles de umbral, respectivamente.
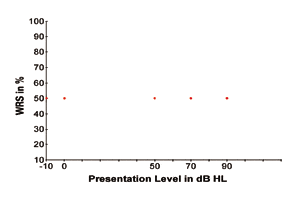 FIGURA 1. Cuatro umbrales hipotéticos de reconocimiento del habla (SRT) mostrados como cuatro puntos de datos para una audición normal y varios grados de pérdida auditiva.
FIGURA 1. Cuatro umbrales hipotéticos de reconocimiento del habla (SRT) mostrados como cuatro puntos de datos para una audición normal y varios grados de pérdida auditiva.
Entonces, ¿cómo sería la curva de rendimiento-intensidad cuando las señales del habla se presentan en sus niveles supralumbral? Basándonos en estos cuatro puntos de datos, ¿podemos estimar sus puntuaciones máximas de reconocimiento de palabras cuando las señales del habla se presentan a varios niveles superiores? Del mismo modo, si estos cuatro puntos de datos representan las TER con un audífono adecuadamente adaptado, ¿podemos predecir la puntuación máxima de inteligibilidad del habla de un sujeto después de recibir el beneficio de un audífono?
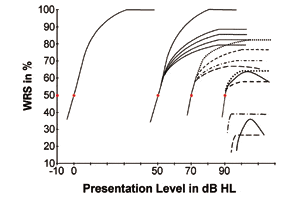 FIGURA 2. Curvas hipotéticas de rendimiento-intensidad que muestran varias puntuaciones máximas de reconocimiento de palabras (eje y) para los cuatro umbrales hipotéticos de reconocimiento del habla (SRT) que se muestran en la Figura 1, que representa el nivel de presentación en el que el habla es apenas reconocible el 50% de las veces. Debe tenerse en cuenta que las curvas mostradas aquí son sólo una parte limitada de la familia de todos los posibles rendimientos de procesamiento del habla que son posibles con los diferentes grados de pérdida auditiva.
FIGURA 2. Curvas hipotéticas de rendimiento-intensidad que muestran varias puntuaciones máximas de reconocimiento de palabras (eje y) para los cuatro umbrales hipotéticos de reconocimiento del habla (SRT) que se muestran en la Figura 1, que representa el nivel de presentación en el que el habla es apenas reconocible el 50% de las veces. Debe tenerse en cuenta que las curvas mostradas aquí son sólo una parte limitada de la familia de todos los posibles rendimientos de procesamiento del habla que son posibles con los diferentes grados de pérdida auditiva.
La figura 2 puede servir para responder a estas preguntas. Basándose en experiencias clínicas y consideraciones teóricas, se han trazado ejemplos de algunas curvas hipotéticas de Rendimiento-Intensidad (P-I) para demostrar la interrelación y el patrón de respuesta de las puntuaciones de reconocimiento de palabras de los sujetos con un estado de audición normal y varios grados de pérdidas auditivas.
Para el estado de audición normal. En la Figura 2, la curva del extremo izquierdo (por ejemplo, pasando el nivel de presentación de 0 dB) puede utilizarse como la curva que representa a los individuos con audición normal. Es la que se ve con frecuencia en los libros de texto y que indica que el rendimiento aumenta junto con el aumento del nivel de presentación de la señal con una pendiente fija, si se mide con un procedimiento de prueba fijo y un material de prueba del habla determinado. El rendimiento alcanza el máximo WRS a unos 40 dB de Nivel de Sensación (SL) por encima del SRT.
Para pérdidas auditivas de 50 dB. En la Figura 2, a la derecha de la curva de los individuos con audición normal, un grupo de curvas que pasan el nivel de presentación de 50 dB representa las respuestas típicas en el WRS para la categoría de oyentes con pérdida auditiva de 50 dB. Entre esta categoría de pérdida auditiva de 50 dB (5 curvas de líneas sólidas), la curva de la izquierda muestra la función P-I cuando la pérdida auditiva de 50 dB es de naturaleza conductiva. Obsérvese que la curva tiene exactamente la misma pendiente y alcanza el mismo WRS máximo que la de los sujetos con audición normal porque la pérdida auditiva conductiva es, por naturaleza, una pérdida de sensibilidad que no implica ninguna patología en el oído interno y las estructuras superiores.
Cuando la pérdida auditiva de 50 dB implica una pérdida auditiva de naturaleza mixta (por ejemplo, un componente leve de pérdida auditiva neurosensorial), entonces la capacidad de procesamiento de señales de los sujetos se reduce. Sus curvas P-I (las otras 4 curvas sólidas de este grupo de curvas) podrían seguir ascendiendo, pero con una pendiente más pronunciada y aplanarse a un WRS máximo más bajo, en comparación con la curva de los sujetos con audición normal o de la pérdida auditiva conductiva.
Desde esta categoría de pérdida auditiva de 50 dB, se puede ver que todas las curvas muestran la misma TER pero con una gran diferencia individual en el WRS máximo, que puede ir desde cerca del 70% al 100%.
Para las pérdidas auditivas de 70 dB. Más a la derecha en la Figura 2, hay 4 curvas de líneas discontinuas que pasan por el punto de datos de SRT de 70 dB, que culminan con un WRS máximo diferente. Estas representan los posibles patrones de respuesta y las diferencias individuales en la función P-I para la categoría de pérdidas auditivas de 70 dB. La categoría de pérdida auditiva en torno a los 70 dB SRT suele ser la mayoría de la población de clientes atendidos en la típica clínica de audífonos.
Debe ser inmediatamente aparente que las mayores variaciones en el WRS máximo, como se muestra en la Figura 2, pueden resultar de este tipo de pérdida. También es interesante observar que algunas curvas discontinuas alcanzan un rendimiento WRS superior a las de la categoría de pérdida auditiva de 50 dB, mientras que otras muestran un rendimiento que es, en general, inferior. Una de las curvas (la curva de línea discontinua inferior) muestra un pequeño grado de fenómeno de vuelco: WRS más pobre a niveles de presentación más altos una vez que se alcanza el WRS más alto.
La gran cantidad de variación individual revelada por las curvas P-I suele estar relacionada con la pérdida auditiva neurosensorial (SNHL) con patología de las células ciliadas y de las fibras neurales. Estas pérdidas suelen presentar un componente de pérdida de sensibilidad y otro de pérdida de claridad, y la pérdida de claridad en las señales del habla varía drásticamente en función de factores como, entre otros, el grado de pérdida de audición, la forma de la pérdida de audición, la etiología de la pérdida de audición, el estado patológico de la estructura del oído-cerebro, el grado de daño de las células ciliadas externas y/o de las células ciliadas internas, el daño y el efecto en la amplificación coclear activa, la función residual de las células ciliadas internas, el daño en las fibras nerviosas retrococleares, el efecto en la sincronía de descarga neural, la proporción de la lesión retrococlear frente a la lesión coclear, el efecto de la reorganización tonotópica de la corteza auditiva, la duración de la pérdida auditiva, el historial de uso de audífonos, la cantidad de tiempo asociada a la estimulación auditiva (in)adecuada, los casos prelinguales frente a los postlinguales, el estilo de vida y el entorno en el que se vive, y la capacidad lingüística de un individuo (véase el recuadro, ¿Existe una pérdida auditiva típica de 70 dB?).
Está claro que un gran número de factores, tal y como se ha comentado en la barra lateral, incluidos los de los ámbitos patológico y lingüístico, interactúan entre sí como mecanismos subyacentes que influyen en el rendimiento del procesamiento de la señal del habla. Por lo tanto, es de esperar que existan grandes diferencias individuales en el patrón de respuesta del procesamiento de la señal del habla, la pendiente de la curva P-I y el WRS máximo entre los sujetos. Para la categoría de pérdida de audición de 70 dB de SNHL, lo que se muestra en la Figura 2 es sólo una parte de las posibles funciones P-I con varios WRS máximos alcanzados, todos con un mismo SRT.
Por lo tanto, la Figura 2 y el sentido común sugieren que predecir la posible WRS máxima a partir de la SRT es un enfoque temerario sin las advertencias adecuadas.
Para pérdidas auditivas de 90 dB. Cuando el grado de pérdida auditiva pasa a la categoría de pérdidas auditivas de 90 dB, la SNHL normalmente involucra el componente neural para complementar el componente sensorial, produciendo pérdidas mucho mayores en la claridad de la señal junto con la pérdida de sensibilidad. Este tipo de pérdidas sugiere un mayor daño en la región retrococlear y en otras estaciones neurales de relevo a lo largo de las vías auditivas superiores. Por lo tanto, es posible que se produzcan más alteraciones neurológicas en las vías superiores, con una mayor probabilidad de disincronía de las descargas neuronales y trastornos del procesamiento auditivo, y que el rendimiento del procesamiento de la señal sea aún peor (en comparación con la categoría de pérdida auditiva de 70 dB). Todos los factores mencionados anteriormente, como el grado real de pérdida auditiva a través de las frecuencias, la etiología particular, la ubicación y la gravedad del daño en el oído interno y las vías auditivas, la reorganización tonotópica, la capacidad lingüística de los individuos, etc., interactuarían entre sí y darían lugar a diferentes patrones de respuesta y pendientes de la curva P-I. De nuevo, se esperarían grandes variaciones en el rendimiento máximo del procesamiento de la señal del habla.
En la figura 2, se trazaron tres curvas (dos de trazos y una de línea sólida que pasan por el punto de datos de 90 dB) para mostrar las diferentes pendientes con varios WRS máximos que pueden alcanzar los individuos de esta categoría de pérdida auditiva. La curva de línea continua muestra un fenómeno de balanceo aún mayor en comparación con el de la categoría de pérdida auditiva de 70 dB. Las tres curvas se sitúan para mostrar que su WRS máxima es probablemente inferior a la de la categoría de pérdida auditiva de 70 dB.
Por supuesto, sabemos que algunos sujetos con una pérdida auditiva de alrededor de 90 dB mostrarían una WRS extremadamente y excepcionalmente buena en comparación con aquellos con una pérdida auditiva incluso leve. Este tipo de excepción no es del todo infrecuente; apoya además la gran variabilidad de las funciones de rendimiento del procesamiento de señales y del sistema auditivo. El punto único de discusión aquí es que todas estas curvas pasan por el mismo punto de datos SRT de 90 dB y producen un WRS máximo radicalmente diferente. Al igual que con el grupo de pérdida de 70 dB, existen grandes diferencias individuales.
En la esquina inferior derecha de la Figura 2, se muestran tres curvas más, mostrando algunas posibles curvas P-I para aquellos con pérdidas auditivas superiores a 90 dB HL. Con este profundo grado de pérdida auditiva y los factores de confusión (como se ha comentado anteriormente), se deben anticipar grandes diferencias individuales en la pendiente de la curva de respuesta y el WRS máximo.
La singularidad de estas tres curvas es que el rendimiento ascendente del reconocimiento del habla de los sujetos puede no llegar ni siquiera al punto del 50%. Además, tanto el máximo WRS como el fenómeno de rollover pueden ser incluso más pobres o más pronunciados, respectivamente, que las pérdidas de 70 dB.
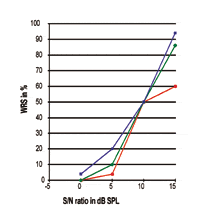 FIGURA 3. Tres curvas individuales de Rendimiento-Intensidad expresadas en relación S/N. Obsérvese que el punto del 50% se encuentra exactamente a 10 dB SPL, mientras que la pendiente y los rendimientos máximos del procesamiento del habla son claramente diferentes.
FIGURA 3. Tres curvas individuales de Rendimiento-Intensidad expresadas en relación S/N. Obsérvese que el punto del 50% se encuentra exactamente a 10 dB SPL, mientras que la pendiente y los rendimientos máximos del procesamiento del habla son claramente diferentes.
Evidencias clínicas
Algunos datos clínicos empíricos pueden ser útiles para demostrar lo anterior. Para estudiar el efecto del umbral de compresión en la inteligibilidad del habla, 12 sujetos con SNHL de leve a grave por encima de 2 kHz escucharon a través de un audífono programable las frases objetivo de la prueba de habla en ruido (SIN). Se seleccionaron ejemplos del rendimiento del procesamiento del habla de estos sujetos y se trazaron como curvas P-I relativas a la SNR (Figuras 3-6).
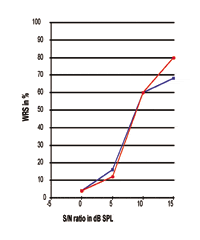 FIGURA 4. Dos curvas individuales de Rendimiento-Intensidad expresadas en relación S/N. Obsérvese que el punto del 50% se sitúa en torno a los 9,06 dB SPL, mientras que la pendiente y los rendimientos máximos del procesamiento del habla son claramente diferentes.
FIGURA 4. Dos curvas individuales de Rendimiento-Intensidad expresadas en relación S/N. Obsérvese que el punto del 50% se sitúa en torno a los 9,06 dB SPL, mientras que la pendiente y los rendimientos máximos del procesamiento del habla son claramente diferentes.
Respecto a las figuras 3-5, está claro que los rendimientos de la SRR de diferentes sujetos pueden ser exactamente iguales en el punto del 50%, mientras que la pendiente de la curva y el rendimiento máximo son completamente diferentes entre sí. Todas estas curvas muestran que la TER es, efectivamente, sólo el punto de datos del 50% a lo largo de la curva de respuesta; en el mundo real existen grandes diferencias con respecto a la pendiente de la curva y al rendimiento máximo de procesamiento. Las cifras indican que el punto de datos del 50% no tiene una relación estrecha con el rendimiento máximo de procesamiento que alcanzarían los individuos. Por tanto, la TER no debe utilizarse como representativa de las respuestas de rendimiento-intensidad.
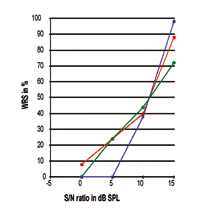 FIGURA 5. Tres curvas individuales de rendimiento-intensidad expresadas en relación S/N. Obsérvese que el punto del 50% se sitúa en torno a los 10,75 dB SPL, mientras que la pendiente y los rendimientos máximos del procesamiento del habla son claramente diferentes.
FIGURA 5. Tres curvas individuales de rendimiento-intensidad expresadas en relación S/N. Obsérvese que el punto del 50% se sitúa en torno a los 10,75 dB SPL, mientras que la pendiente y los rendimientos máximos del procesamiento del habla son claramente diferentes.
Esta información también sugiere que, a la hora de asesorar a los estudiantes de posgrado y formular proyectos de investigación, puede no ser prudente utilizar la TER como criterio principal del estudio. Aunque en la actualidad se diseñan bastantes pruebas para encontrar el punto del 50% del rendimiento del procesamiento del habla de los sujetos, la interpretación del punto del 50% o de la TER, ya sea expresada en términos del nivel de presentación o de la SNR, debe hacerse con precaución. El rendimiento del procesamiento del habla es un fenómeno más complicado.
En la figura 6, las tres curvas P-I individuales tienen un punto 50% totalmente diferente. La curva roja representa a un individuo con SNHL de alta frecuencia leve, mientras que las otras dos curvas se obtuvieron de individuos con SNHL de alta frecuencia de moderada a grave. De hecho, la pendiente pronunciada y el rendimiento casi perfecto del procesamiento del habla demostrado por la curva roja son similares a las respuestas obtenidas por los sujetos con audición normal.
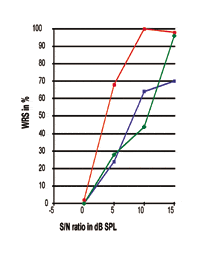 FIGURA 6. Tres curvas individuales de rendimiento-intensidad con sus puntos del 50% a 3,35, 8,51 y 9,83 dB SPL respectivamente. La curva roja con el círculo relleno, cuya pendiente y rendimiento máximo en el procesamiento del habla son similares a los alcanzados por sujetos con audición normal, es realizada por un individuo con pérdida auditiva neurosensorial de alta frecuencia leve, mientras que las otras dos curvas se obtienen de individuos con pérdida auditiva neurosensorial de alta frecuencia de moderada a severa.
FIGURA 6. Tres curvas individuales de rendimiento-intensidad con sus puntos del 50% a 3,35, 8,51 y 9,83 dB SPL respectivamente. La curva roja con el círculo relleno, cuya pendiente y rendimiento máximo en el procesamiento del habla son similares a los alcanzados por sujetos con audición normal, es realizada por un individuo con pérdida auditiva neurosensorial de alta frecuencia leve, mientras que las otras dos curvas se obtienen de individuos con pérdida auditiva neurosensorial de alta frecuencia de moderada a severa.
Esto podría esperarse, ya que los sujetos con pérdida auditiva neurosensorial leve pueden sufrir menos daños en el sistema oído-cerebro. En el caso de las curvas obtenidas de individuos con HNC de alta frecuencia de moderada a severa, se pueden observar mayores grados de diferencias individuales, como se ha comentado anteriormente. Al observar estas dos curvas, hay que tener en cuenta que la que tiene el mejor punto del 50% (curva azul), en comparación con la curva verde, no produce un mejor WRS. Esto indica que, en el mundo real, donde existen variaciones individuales, un mejor punto del 50% (SRT) no siempre se asocia con un mejor rendimiento máximo de procesamiento del habla.
Resumen
1) El rendimiento del procesamiento del habla de un individuo se ve afectado dinámicamente por un número de factores que incluyen el grado, el tipo, la forma de la pérdida auditiva, la duración de la pérdida auditiva y muchas otras condiciones fisiopatológicas en el sistema oído-cerebro e incluso la capacidad/perfil lingüístico del individuo.
2) El umbral de reconocimiento del habla no es más que el punto de datos del 50% en la curva P-I del rendimiento del procesamiento del habla de los sujetos.
3) El punto de datos del 50% (SRT) de un individuo en la curva P-I podría estar en la unidad con otro paciente, pero la pendiente y el rendimiento de procesamiento de estos dos pacientes podrían ser completamente diferentes entre sí.
4) La relación entre el patrón de respuesta, el SRT, la pendiente de la curva P-I y el rendimiento máximo de procesamiento es extremadamente dinámica e impredecible debido a la variabilidad individual.
5) Una respuesta con mejor SRT no está necesariamente asociada a un mejor WRS. Aunque a menudo parece haber una suposición/enfoque de trabajo en nuestro campo para utilizar el punto de datos del 50% para predecir el rendimiento máximo de procesamiento del habla, esto es de hecho un esfuerzo sin fundamento clínico/teórico ni precisión.
6) A la hora de realizar adaptaciones de audífonos o ALD, como la selección, la modificación y el ajuste fino, o a la hora de establecer expectativas realistas sobre los beneficios de la amplificación, no se debe depender en exceso del punto de datos del 50%. En su lugar, obtener una curva P-I más completa con el máximo rendimiento de procesamiento del habla es un enfoque más pragmático para el clínico del mundo real.
¿Existe una pérdida auditiva típica de 70 dB?
Es evidente que las pérdidas auditivas más graves pueden provocar variaciones bastante notables en el WRS. Las pérdidas auditivas de más de 70 dB suelen ser complejas y multifacéticas. Por ejemplo, aquellos pacientes con puntuaciones de SRT de 70 dB pueden tener umbrales de tonos puros totalmente diferentes en las distintas frecuencias. En otras palabras, los pacientes pueden tener varias magnitudes de pérdida auditiva en frecuencias discretas de tonos puros, pero todos pueden parecer tener un SRT alrededor de 70 dB HL. Los individuos también pueden tener diferentes formas de audiograma, incluyendo una pérdida auditiva plana, inclinada, de baja frecuencia, de alta frecuencia, precipitada, o incluso una pérdida auditiva en forma de galleta, pero aún así muestran una TER de alrededor de 70 dB HL.
Esto significa que la localización y la gravedad del daño en la región de alta frecuencia frente a la de baja frecuencia (por ejemplo, basal frente a apical) de la membrana basilar en el oído interno podría ser muy diferente entre estos sujetos. Además, se inducirían diferentes grados de daño en la función de amplificación coclear activa; la diferente electromotilidad de las células ciliadas externas daría lugar a diferentes capacidades de sensibilidad auditiva y discriminación de frecuencias de las señales.6-9 Todas estas condiciones patológicas darían lugar a un procesamiento de la señal con una sensibilidad auditiva deficiente y un análisis de frecuencias reducido, además de diferentes cantidades de distorsión al procesar consonantes y vocales. Y, a su vez, esto se reflejaría en diversas puntuaciones de reconocimiento del habla.
Si la patología implica un mayor daño sobre las células ciliadas internas frente a las externas, su efecto sobre el procesamiento de la señal y la cantidad de distorsión durante el procesamiento de la señal sería probablemente mayor y más alto, porque el 95% de las fibras nerviosas auditivas transportan información de las células ciliadas internas mientras que sólo un 5% de los nervios auditivos inervan las células ciliadas externas.9-10 Cuando la patología se produce más en la región retrococlear que en la coclear, cabría esperar una mayor pérdida de claridad y el fenómeno del rollover en el reconocimiento del habla. También se sabe que, cuando se dañan las vías auditivas superiores, pueden verse afectados los procesos de nivel superior, como la diferenciación auditiva figura-fondo, la integración binaural, la separación binaural y la liberación del enmascaramiento. Esto también podría conducir a un reconocimiento del habla variado y aparentemente más pobre en las tareas de escucha en ruido.11,12 Diversas etiologías como la infección bacteriana/vírica del oído interno, la pérdida de audición inducida por el ruido/drogas, el fenómeno de circulación sanguínea/hemorragia, el neuroma acústico, la APD y la disincronía auditiva, la enfermedad autoinmune del oído interno y la pérdida de audición hereditaria pueden dar lugar a condiciones patológicas que produzcan diferentes ubicaciones y severidades del daño sobre las estructuras sensoriales/neurales, con rendimientos de reconocimiento del habla resultantes que siguen estando asociados a una SRT de 70 dB.11,12
Otro factor proviene del área de reorganización tonotópica de la corteza auditiva de los sujetos animales que sufren de SNHL. Se sabe que, con la SNHL sostenida en el tiempo, se establece un área monotópica expandida en la corteza auditiva en la que las neuronas tienen su frecuencia característica original cambiada a una nueva frecuencia (más baja). Sus curvas de sintonía muestran umbrales elevados, mala discriminación de frecuencias e hipersensibilidad a frecuencias distintas de su frecuencia característica original.13,14
También se ha sugerido que esta reorganización tonotópica -un efecto debido a la plasticidad del cerebro en respuesta a la estimulación auditiva inadecuada y asimétrica a lo largo del tiempo- está estrechamente relacionada con la privación/adaptación auditiva en sujetos humanos que tienen un WRS pobre en palabras y frases monosilábicas, e incluso con otras actuaciones de procesamiento de señales de alto nivel que implican la separación e integración binaural.13-17 En este caso, para los sujetos de la categoría de pérdida de audición de 70 dB, sus diferentes grados de pérdida de audición a través de las frecuencias, las diferentes ubicaciones/severidades del daño y muchas otras variables pueden sumarse como factores de confusión para la formación de la reorganización tonotópica de la corteza auditiva.
Esto significa que, entre los sujetos de esta categoría, un área monotópica diferente en la corteza auditiva de los individuos pierde sus capacidades originales de procesamiento de señales. Se sintoniza con una frecuencia diferente, varios porcentajes de las neuronas se sintonizan menos, y pueden producirse cambios únicos en la disposición de los contornos de isofrecuencia en la corteza, así como diversos grados de elevación del umbral e hipersensibilidad de las neuronas a frecuencias distintas de su mejor frecuencia. Deben esperarse entonces diversas reducciones en la discriminación de frecuencias y otras capacidades de procesamiento neurológico superior. Estas diferentes características de la reorganización tonotópica resultante, a su vez, conducen a variaciones en el rendimiento de los sujetos en el ruido de fondo, el procesamiento de la señal y las resoluciones de frecuencia e intensidad, todo lo cual resulta en diferencias en el reconocimiento del habla.
Además, no hay duda de que la capacidad lingüística de cada individuo es una gran macrovariable en el rendimiento de comprensión del habla de esa persona. Las capacidades lingüísticas de las personas -sus habilidades en cuanto a la forma semántica, la estructura sintáctica y el uso pragmático del lenguaje, etc.- difieren y pueden ayudarles o dificultarles durante las interrupciones de la comunicación (por ejemplo, cuando intentan rellenar los espacios en blanco utilizando pistas lingüísticas y contextuales). En el caso de las personas con una pérdida auditiva de 70 dB, que ya tienen dificultades para comprender el habla, la capacidad lingüística sería una macrovariable que interactuaría con su pérdida auditiva e influiría en el WRS, especialmente cuando el WRS se mide utilizando materiales de frases en ruido de fondo. Además, la complejidad del perfil lingüístico de las personas bilingües puede verse agravada por variables como la edad de adquisición de la segunda lengua, la lengua de los padres, el origen geográfico de la adquisición, el uso de la lengua, el tiempo de exposición a la segunda lengua, etc., y todas estas variables influyen en el rendimiento del procesamiento del habla/lenguaje, especialmente durante las tareas de escucha en ruido.18-20
1. Lewis MS, Crandell CC. Aplicaciones de la tecnología de frecuencia modulada (FM). Presentado en: The 17th Annual Convention of American Academy of Audiology (Instructional course IC-103), Washington, DC;2005.
2. Von Hapsburg D, Pena E. Understanding bilingualism and its impact on speech audiometry. J Speech Lang Hear Res. 2002; 45: 202-213.
3. Newby HA, Popelka GR. Audiology. 6th ed. Englewood Cliffs, NJ: Prentice Hall Inc; 1992:126-201.
4. Stach BA. Clinical Audiology: An Introduction. San Diego, Calif: Singular Publishing Group Inc; 1998:193-249.
5. DeBonis DA, Donohue CL. Survey of Audiology: Fundamentos para audiólogos y profesionales de la salud. Boston, Mass: Allyn and Bacon; 2004:77-164.
6. Brownell W, Bader C, Bertrand D, de Ribaupierre Y. Evoked mechanical responses of isolated cochlear outer hair cells. Science. 1985;227(11):194-196.
7. Dallos P, Evans B, Hallworth R. Nature of the motor element in electrokinetic shape changes of cochlear outer hair cells. Nature. 1991;350(14):155-157.
8. Dallos P, Martin R. The new theory of hearing. Hear Jour. 1994; 47(2):41-42.
9. Ryan AF. Nuevos puntos de vista sobre la función coclear. En: Robinette MS, Glattke TJ, eds. Otoacoustic Emissions: Clinical applications. 1st ed. New York, NY: Thieme Medical Publishers Inc; 1997:22-45.
10. Gelfand SA. Hearing: An Introduction to Psychological and Physiological Acoustics. 3rd ed. New York, NY: Marcel Dekker Inc; 1998:47-82.
11. Mencher GT, Gerber SE, McCombe A. Audiology and Auditory Dysfunction. Needham Heights, Mass: Allyn and Bacon; 1997:105-232.
12. Martin FN, Clark JG. Introduction to Audiology. 9th ed. Boston, Mass: Allyn and Bacon; 2006:277-346.
13. Harrison RV, Nagasawa A, Smith DW, Stanton S, Mount RJ. Reorganización de la corteza auditiva después de la pérdida auditiva coclear neonatal de alta frecuencia. Hearing Res. 1991;54:11-19.
14. Dybala P. Effects of peripheral hearing loss on tonotopic organization of the auditory cortex. Hear Jour. 1997;50(9):49-54.
15. Silman S, Gelfand SA, Silverman CA. Late-onset auditory deprivation: Effects of monaural versus binaural hearing aids. J Acoust Soc Amer. 1984;76(5):1357-1362.
16. Palmer CV. Deprivación, aclimatación, adaptación: ¿Qué significan para sus adaptaciones de audífonos? Hear Jour. 1995;47(5):10,41-45.
17. Neuman AC. Late-onset auditory deprivation: Una revisión de la investigación anterior y una evaluación de las necesidades futuras de investigación. Ear Hear. 1996;17(3):3s-13s.
18. Grosjean F. Processing mixed language: issues, findings, and models. En: de Groot AMB, Kroll JF, eds. Tutorials in Bilingualism: Psycholinguistic Perspectives. Mahwah, NJ: Lawrence Erlbaum Associates; 1997:225-251.
19. Mayo LH, Florentine M, Buus S. Age of second-language acquisition and perception of speech in noise. J Speech Lang Hear Res. 1997;40:686-693.
20. Von Hapsburg D, Champlin CA, Shetty SR. Reception thresholds for sentences in bilingual (Spanish/English) and monolingual (English) listeners. J Amer Acad Audiol. 2004;15(1):88-98.